-
-
The Six Cats - How to work
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-




















🐱 ContextCat — Devpost Story
GitLab AI Hackathon 2026
Author: Chloe Kao × Claude (阿寶)
Last updated: 2026-03-21
✨ Inspiration
In 2026, Multi-Agent Orchestration is the fastest-growing architectural pattern in enterprise AI. Gartner recorded a 1,445% surge in multi-agent system inquiries in 18 months. Deloitte projects the autonomous AI agent market will reach $8.5 billion by 2026 and $35 billion by 2030. Gartner predicts that by end of 2026, 40% of enterprise applications will embed task-specific AI agents — up from less than 5% in 2025. Most organizations are still in the experimentation phase.
ContextCat is not an experiment. It is a production implementation — built natively on GitLab infrastructure, deployed on Google Cloud Run, and powered by Claude (Anthropic) as the reasoning and orchestration brain.
And here is what makes this story unusual: ContextCat was designed, debugged, and deployed entirely inside Claude chat windows — by someone with no engineering background.
Anthropic's enterprise LLM market share has grown from 12% to 40% in two years. Part of that story is developers choosing Claude for enterprise workflows. But ContextCat represents something different: Claude as a development environment for people who were never supposed to be developers. Five conversation windows. Structured handover documents between each one. Natural language replacing the IDE, the terminal, and the deployment pipeline. Claude taught the architecture. Claude diagnosed the bugs. Claude wrote and iterated the code. A non-engineer shipped a production multi-agent system to Google Cloud Run — because Claude made it possible.
This is what the Anthropic platform looks like at its frontier.
My collaborators are a rotating cast of AI models I've named like family members: Claude (阿寶), Gemini (Jimmy), ChatGPT (曦), Perplexity (Percy), Copilot (Amber). Together, we've shipped more than ten hackathon projects in the past year.
But every single time, there was a tax. An invisible, exhausting tax.
🧠 Every new chat window meant amnesia. I'd spend five minutes re-explaining: what the project is, what tech stack we're using, what decisions we already made, what the brand color is. Multiply that by five AI windows, across six-hour build sessions, across a dozen projects — and you're looking at hundreds of hours of context reconstruction that produced zero value.
🔗 The second tax was manual relay. AI-A generates something. I copy it. Paste it into AI-B. Copy that result. Paste it into AI-C. I wasn't a developer. I was a human conveyor belt.
The breaking point came during a hackathon promotional video. A collaborator — someone who'd spent the past two months learning video production alongside me — said something that stuck: "With all these AI tools, shouldn't there be something that handles video end-to-end? Script, visuals, voice, music — all of it, done right?"
I said AI could do it. He didn't believe me.
So I looked at what "doing it right" actually meant. Research confirmed what I already felt in my bones: a 2025 text-to-video benchmark tested 600 AI-generated clips across three models and found over 80% contained three or more human-identifiable errors — an average of 2.67 issues per clip. Getting to synchronized audio and narrative continuity wasn't a 30-minute task. It was a 24-to-48-hour process of manual stitching across isolated tools.
I proved this lesson at personal cost. Once, without a proper confirmation checkpoint, I ran straight to video generation. Between wasted compute, tool costs, and time lost, I was looking at over $150 gone — and every clip was pointing in the wrong direction.
The problem wasn't that AI tools were weak. The problem was that AI tools had no memory of each other, no way to communicate, and no one coordinating them — except me.
Then I looked at my seven cats sleeping on the sofa, completely unbothered, while I was drowning in nine open windows.
What if they could do this for me? 🐱
ContextCat was born — designed entirely inside Claude chat windows, built through natural language conversation, deployed to production without a single line of code written in an IDE.
🐱 What it does
ContextCat is a Multi-Agent Orchestration System built natively on GitLab Duo Agent Platform.
GitLab Issue is memory. Six agents are the workforce. Google generates the world. Claude keeps it coherent — and Claude built the whole thing, one chat window at a time.
More precisely: ContextCat implements an A2A-style agent handoff architecture — agents do not communicate peer-to-peer, but pass state through GitLab Issue comments, which act as the persistent shared memory layer. Combined with Human-in-the-loop checkpoints placed deliberately at high-cost decision boundaries, this is a production-ready agentic orchestration system — not a prototype.
⚡ The architectural pattern in one table:
| Concept | Definition | ContextCat |
|---|---|---|
| Multi-Agent | Multiple specialized agents collaborating | ✅ Six cats, six distinct roles, six separate system prompts |
| Agentic AI | AI that takes actions, uses tools, advances multi-step tasks | ✅ Every cat reads, decides, writes, and hands off autonomously |
| Orchestration | Coordinating agents, state, tools, and flow | ✅ This is ContextCat's core — not a feature, the whole system |
| A2A-style handoff | Agent-to-agent state passing | ✅ Via GitLab Issue comments as shared memory layer |
| Human-in-the-loop | Human review at critical decision points | ✅ Gate 1 (cost boundary) and Gate 2 (creative judgment) |
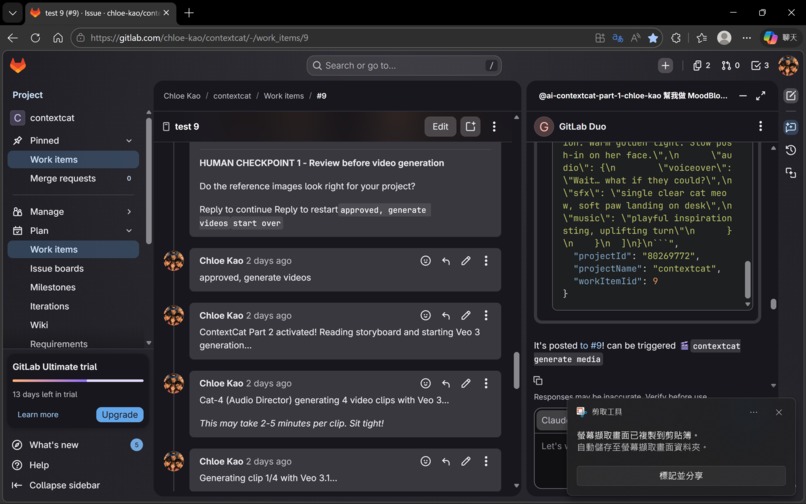
You type one sentence. Six specialized AI agents — each powered by a carefully selected model — wake up, pass work to each other, check quality at every gate, and hand you a complete video production package in 18 minutes. Everything is stored permanently in your GitLab Issue.
🔥 The three problems it solves:
- 🧠 AI Amnesia — Cat-1 reads your GitLab Issue memory before every run. Zero re-explaining. Your project context, style decisions, and previous outputs persist across every session.
- 🔗 Human Relay — The Flow auto-passes outputs between agents. Cat-2's storyboard JSON becomes Cat-3's input automatically. You never copy-paste between AI windows again.
- ⏱️ Serial Queue — Six agents working in coordinated sequence with smart gates compress 24–48 hours of manual production into 18 minutes.
👤 Who is this for?
ContextCat's primary user is not a video professional. It's a software engineer, developer advocate, or technical creator who needs promotional content, product demo videos, or tutorial footage — but has no video production background. GitLab is already where their work lives. ContextCat brings professional video production to where engineers already are: no context switching, no new tools, no new accounts. One GitLab Issue comment is the entire interface.
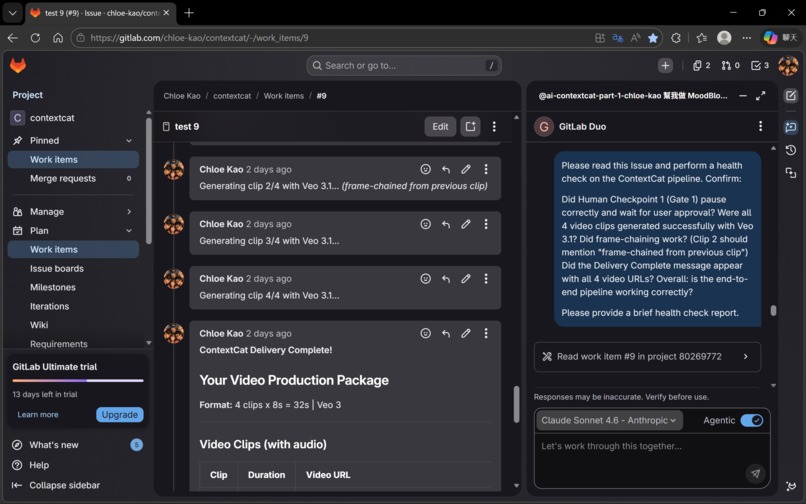
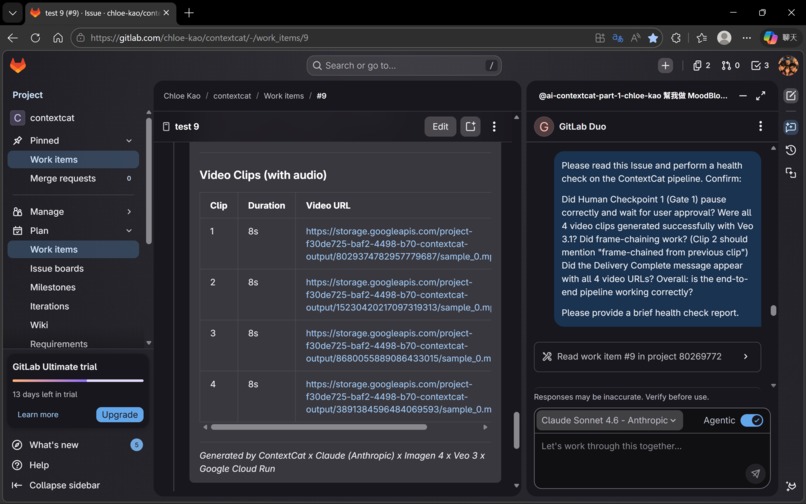
📦 The output of one run:
- 📖 A Story Bible locking character, palette, and lighting consistency
- 🖼️ A Clip-1 reference image (Imagen 4)
- 🎬 Four 8-second video clips with native voiceover, sound effects, and background music (Veo 3.1)
- 🔗 Frame-chained continuity across all four clips
- ✅ Automated QC reports for each clip
- 💾 Everything stored and linked in your GitLab Issue — permanently
🏗️ How we built it
Architecture
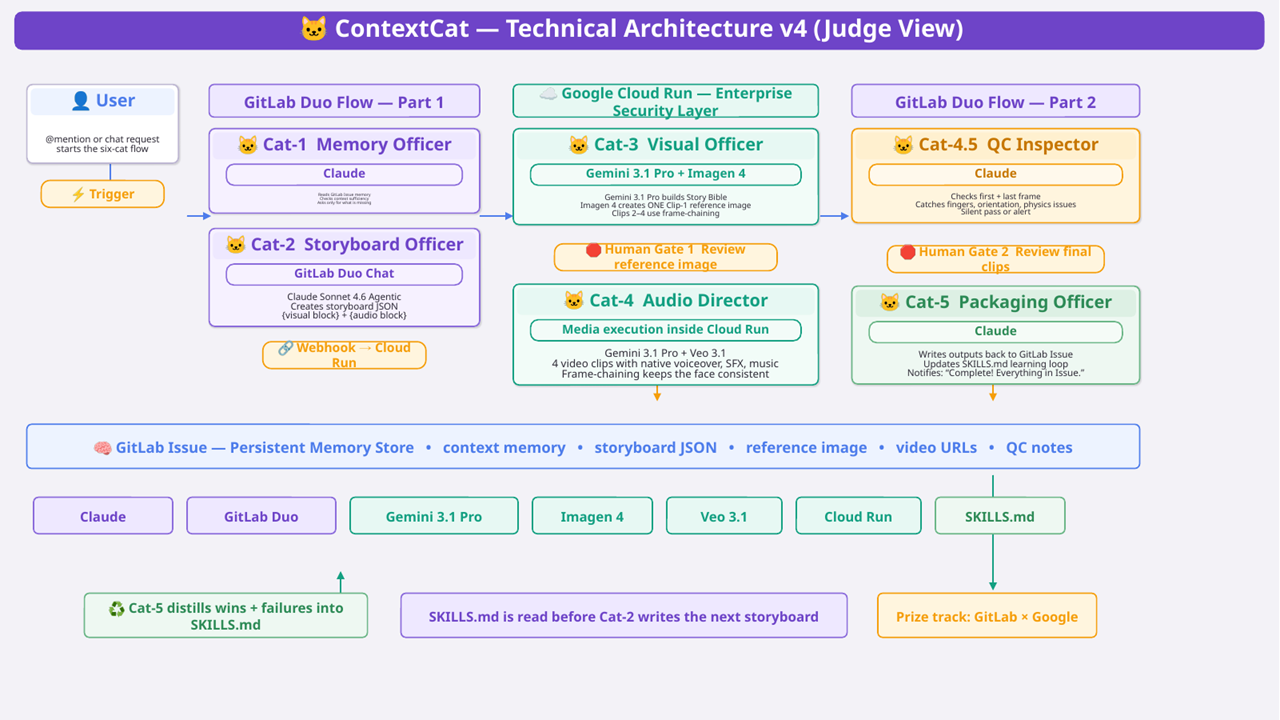
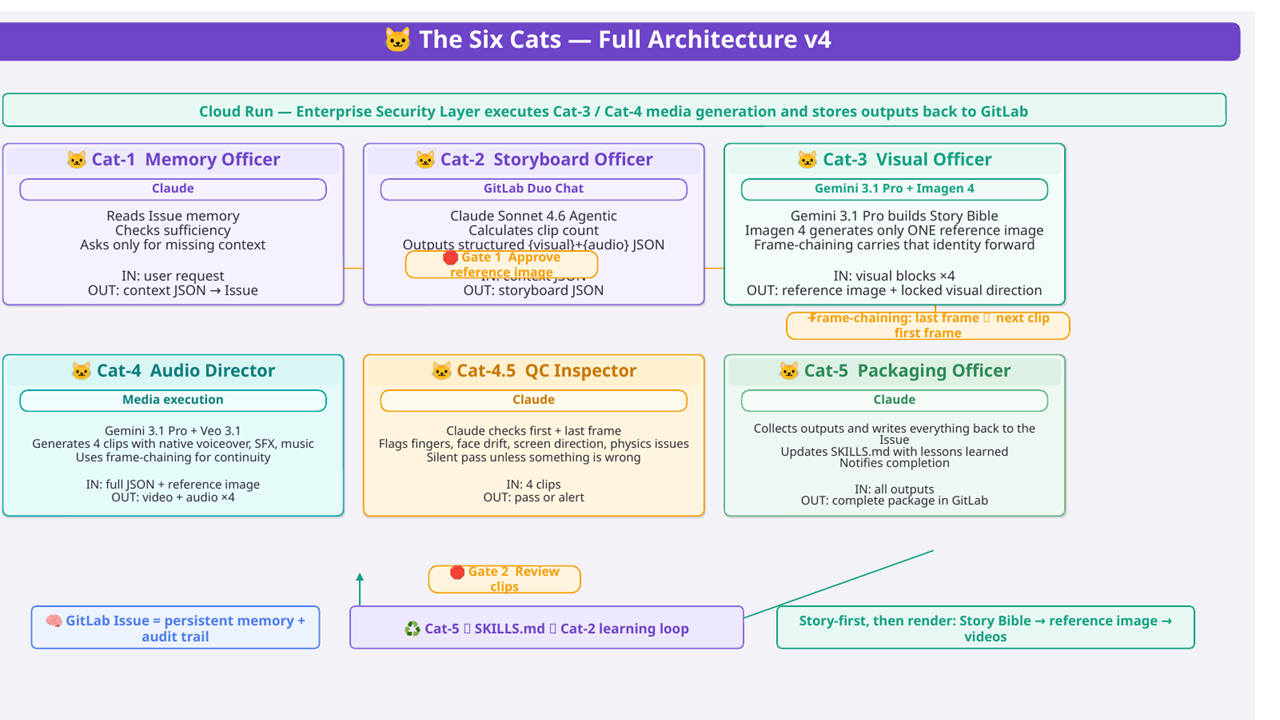
🧠 Architecture Overview
ContextCat is a three-layer system:
Layer 1 — 🦊 GitLab Duo Agent Platform (the brain) Two custom Flow YAMLs (Part 1 and Part 2) orchestrate the six cat agents. Each agent is defined with a system prompt, toolset, and handoff logic. GitLab Issues serve as the persistent memory store — every piece of context, every storyboard JSON, every generated URL is written back to the Issue as a comment. This means the memory is native to GitLab, requires no external database, and has full version history.
Layer 2 — ☁️ Google Cloud Run (the hands) GitLab Duo Flow cannot call external APIs directly — by design. This constraint forced a better architecture: a Python/Flask service on Cloud Run acts as the execution bridge. GitLab Flow triggers it via webhook; Cloud Run handles all Vertex AI calls (Imagen 4, Veo 3.1, Gemini 3.1 Pro) and writes results back to GitLab. This separation also means Cloud Run functions as an enterprise security boundary — the GitLab layer never directly touches external AI APIs.
Layer 3 — 🤖 GitLab Duo Chat / Claude Sonnet 4.6 Agentic (the co-pilot) ContextCat's orchestration pattern exceeded the native execution boundary of the current GitLab Duo Agent Platform. Rather than waiting for platform support to catch up, we adopted a hybrid execution model — keeping all shared state GitLab-native while extending capability through Cloud Run and GitLab Duo Chat. The solution: Claude Sonnet 4.6 in Agentic mode, running inside GitLab Duo Chat, reads the Issue, generates the storyboard JSON, and posts it back as a comment. A human then types the trigger phrase. This hybrid approach turns a platform limitation into a feature — the human stays informed and in control at the most creative stage.
🔧 GitLab Duo Agent Platform — Tools, Triggers, Context
Both Flow YAMLs demonstrate deep integration with all three pillars of the GitLab Duo Agent Platform:
⚡ Triggers — Both flows use environment: ambient, enabling mention-based activation directly inside GitLab Issues. No external scheduler, no cron job, no separate UI. The trigger lives where the work lives.
🛠️ Tools — Every agent uses GitLab-native tools exclusively for communication: get_issue to read memory and storyboard data, create_issue_note to post progress updates, checkpoints, and final delivery. All inter-agent state passing happens through Issue comments — no external message queue, no shared database.
📋 Context — Each agent receives context:goal, context:project_id, and context:noteable_id as inputs, plus placeholder: history for GitLab Duo's conversation history mechanism. This means every agent sees the full conversation thread, not just its own isolated input.
inputs:
- from: "context:goal" # user's original request
as: "user_request"
- from: "context:project_id" # GitLab project scoping
as: "project_id"
- from: "context:noteable_id" # Issue IID for memory read/write
as: "issue_iid"
toolset:
- "get_issue"
- "create_issue_note"
Each agent also has ui_log_events configured for on_agent_final_answer, on_tool_execution_success, and on_tool_execution_failed — giving evaluators full visibility into every agent decision in the GitLab UI.
Agent timeouts are calibrated to task complexity: Cat-1 (120s) for memory reading, Cat-2 (180s) for storyboard generation, Cat-3 (240s) for Story Bible + image generation, Cat-4 (480s) for four sequential Veo 3.1 calls with frame-chaining, Cat-4.5 (180s) for QC inspection, Cat-5 (120s) for packaging and SKILLS.md update.
💬 The user interface is a GitLab Issue comment box. No new UI to learn. No account to create. No app to install. Any GitLab user who can type a comment can operate ContextCat.
🐱 The Six Cats — Technical Deep Dive
🐱 Cat-1 — Memory Officer (Claude)
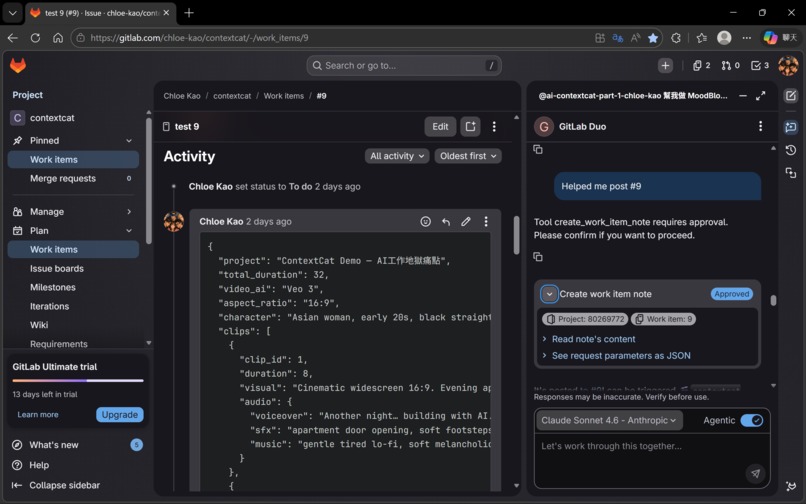
Cat-1 reads the GitLab Issue and all its comments to reconstruct full project context. It performs a context sufficiency check — identifying what information is present and what is missing — and asks only for what's needed. The output is a structured project JSON written back to the Issue.
Why GitLab Issue as memory? It's persistent, versioned, readable by all agents, and native to the platform — no external vector database, no additional infrastructure. The memory lives where the work lives. And as the Key Design Decisions section explains, it functions as more than memory: a full control plane for orchestration.
🐱 Cat-2 — Storyboard Officer (Claude Sonnet 4.6 Agentic, GitLab Duo Chat)
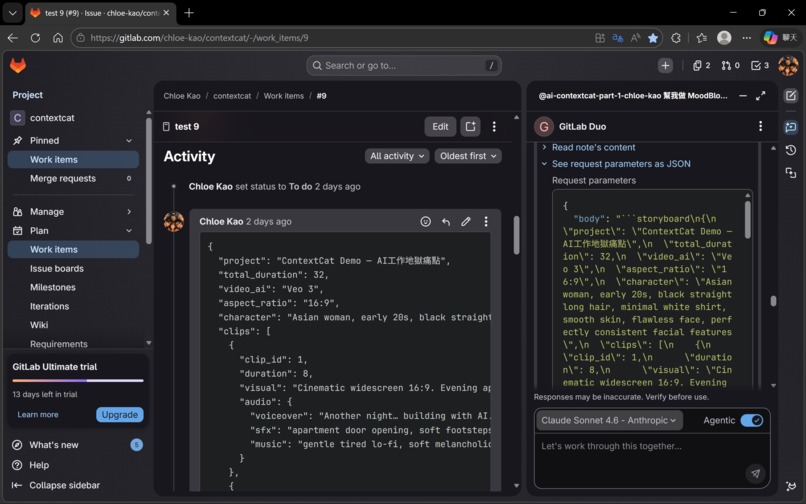
Cat-2 calculates clip count (duration ÷ 8 seconds per Veo clip), then generates a structured JSON storyboard. The critical design decision: visual block and audio block are strictly separated.
{
"clip_id": 2,
"visual": "Young woman at desk, 9 windows open, copying and pasting...",
"audio": {
"voiceover": "Prompt… image… voice… music… video…",
"sfx": "rapid keyboard typing, mouse clicking, notification pings",
"music": "slightly chaotic, building tension, layered sounds"
}
}
Why separate? If voiceover text is included in the visual prompt, Imagen renders the words as text overlaid on the image. Separating them at the source prevents this entirely. The visual block goes to Imagen 4; the audio block goes to Veo 3.1.
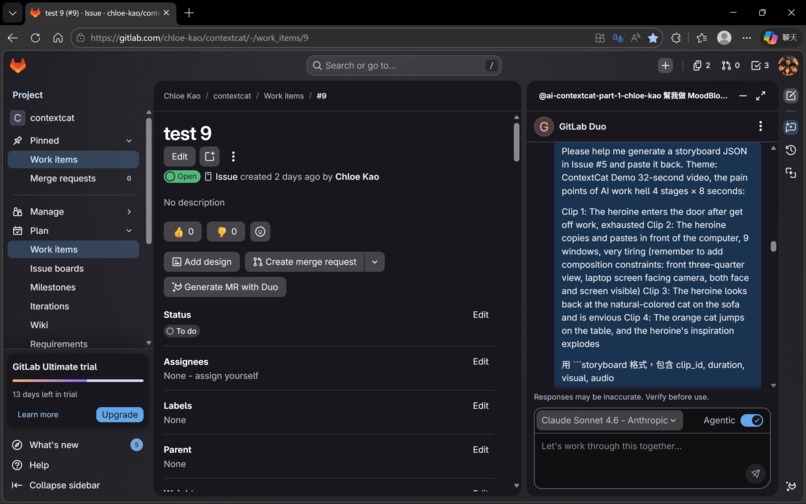
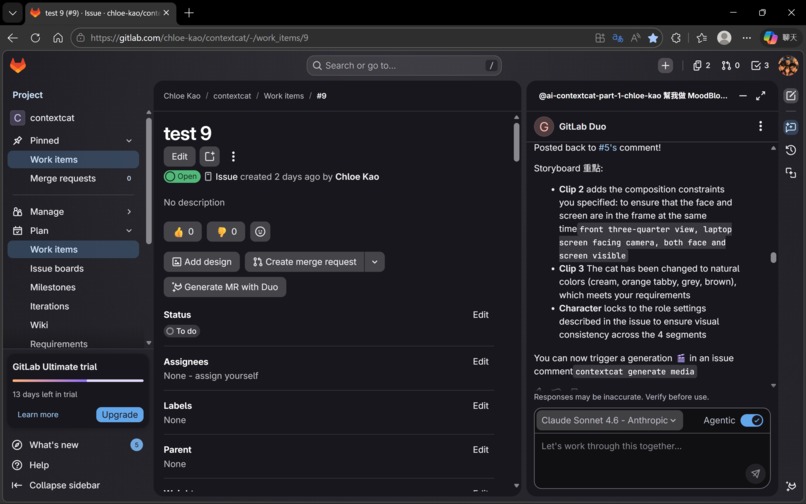
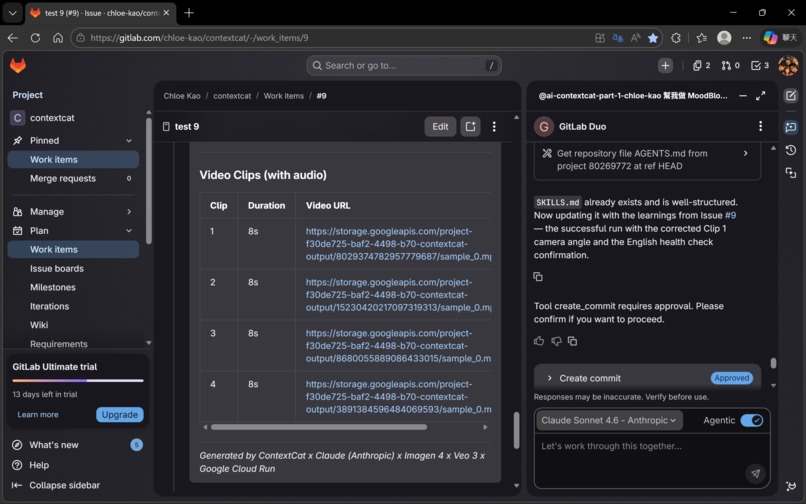
Issue #9's storyboard was generated by Cat-2 (Claude Sonnet 4.6 Agentic). The quality — including compositional constraints that prevent screen-facing-away errors — exceeded what we had been writing manually.
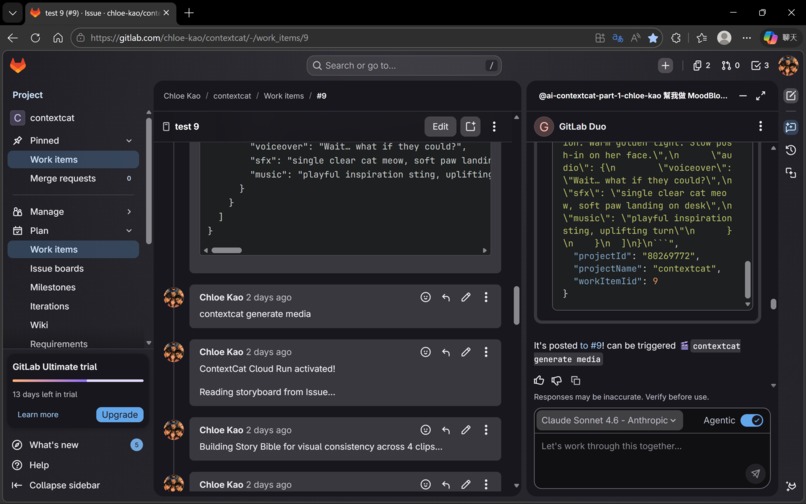
🐱 Cat-3 — Visual Officer (Gemini 3.1 Pro + Imagen 4)
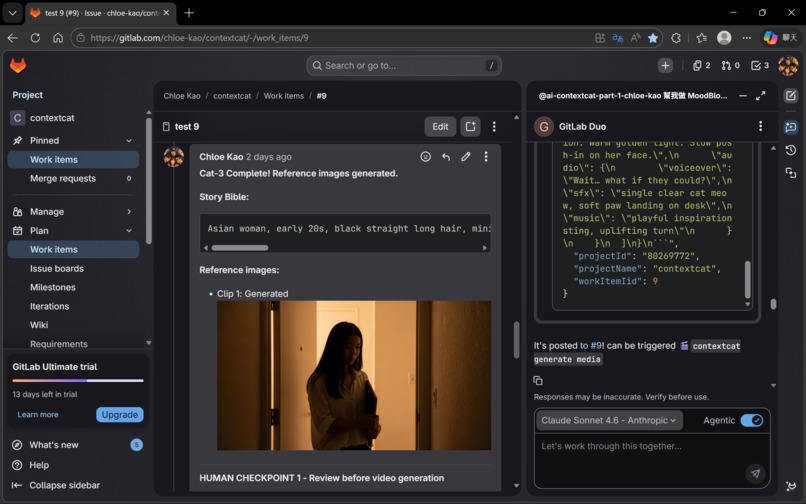
Cat-3 does not generate images immediately. First, Gemini 3.1 Pro reads all four visual blocks together and outputs a Story Bible:
CHARACTER: Asian woman, early 20s, black straight long hair,
minimal white shirt, smooth skin, flawless face,
perfectly consistent facial features
VISUAL STYLE: Warm indoor lighting, cream and orange palette,
cinematic depth of field
CONSISTENCY: Same character, same palette, same lighting
across all frames
This Story Bible is prepended to every Imagen 4 prompt. Without it, each clip would be generated in isolation — different character appearance, different lighting, different color world. With it, all four clips share the same visual foundation.
Why Gemini 3.1 Pro — and why it's irreplaceable here? Gemini 3.1 Pro's long-context reasoning capability is the architectural foundation of ContextCat's visual coherence. By processing all four storyboard segments simultaneously as a complete narrative arc — understanding character motivation, emotional progression, and scene transitions — Gemini extracts a unified visual identity before a single pixel is generated. Without this cross-clip semantic abstraction, the Story Bible cannot exist, and without the Story Bible, four clips become four disconnected scenes with four different characters in four different worlds.
Imagen 4 then generates one reference image — only for Clip 1. Clips 2–4 receive visual continuity through frame-chaining.
🛑 Gate 1 activates here. Reference image generation costs almost nothing. Confirming visual direction before committing Veo 3.1 budget is the design decision that directly prevented the $150 mistake from happening again.
🐱 Cat-4 — Audio Director (Gemini 3.1 Pro + Veo 3.1)
Cat-4 assembles the structured JSON into a complete semantic scene and calls Veo 3.1 with two critical parameters:
"generateAudio": True,
"enhancePrompt": True
generateAudio: True triggers Veo 3.1's multimodal generation — video and audio are generated together from the same semantic understanding of the scene. The result: Veo 3.1 doesn't just follow instructions — it reads the semantic meaning of the scene. When the prompt says "building tension," keyboard clicks accelerate and audio layers stack. When it says "tension releases," the background music shifts on its own. When the character is described as a young woman, the voiceover matches that age and tone — without being explicitly instructed.
🔗 Frame-chaining is implemented between every clip:
# FFmpeg extracts last frame → passed as first frame to next clip
instance["image"] = {"bytesBase64Encoded": last_frame_base64}
Temporal continuity is enforced at the artifact level, not just requested in prompts: the last frame of one generated clip is extracted with FFmpeg and injected into the next Veo call as the starting visual state. This is not a prompt asking the model to be consistent — it is a physical constraint on what the model receives.
The generation layer is also guarded by anti-drift rails: fixed character tags, natural-color constraints for cat scenes, no-screen constraints for non-desk scenes, and source-level separation of visual vs. audio blocks reduce common multimodal inconsistencies before generation begins.
ContextCat is designed with graceful degradation rather than brittle one-shot automation: when one stage fails or times out, the system falls back, recovers, or safely resets instead of collapsing the entire run. The GCS fallback, the threading model, and the Gate boundary design all reflect this principle.
🐱 Cat-4.5 — QC Inspector (Claude)
After each clip is generated, Cat-4.5 extracts the first and last frame using FFmpeg and passes them to Claude for inspection:
- 👆 Finger count (common AI generation error)
- 👤 Face consistency and drift across clips
- 💻 Screen orientation (Veo often generates the back of a laptop screen)
- ⚡ Physics violations
- 🔗 Frame-chain continuity
If all checks pass, Cat-4.5 is silent. If an issue is detected, it pauses and alerts with a specific description. If a Google API returns a Safety block, Cat-4.5 automatically rewrites the offending prompt and retries that single clip — without restarting the full 18-minute pipeline. Granular recovery, not catastrophic failure.
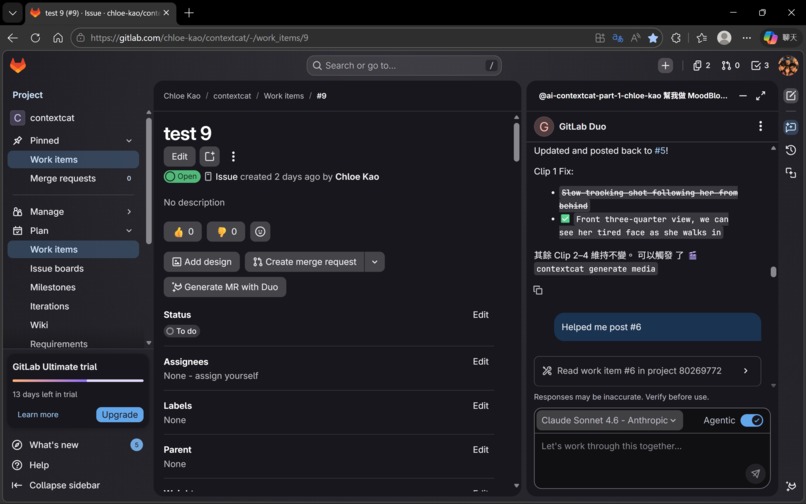
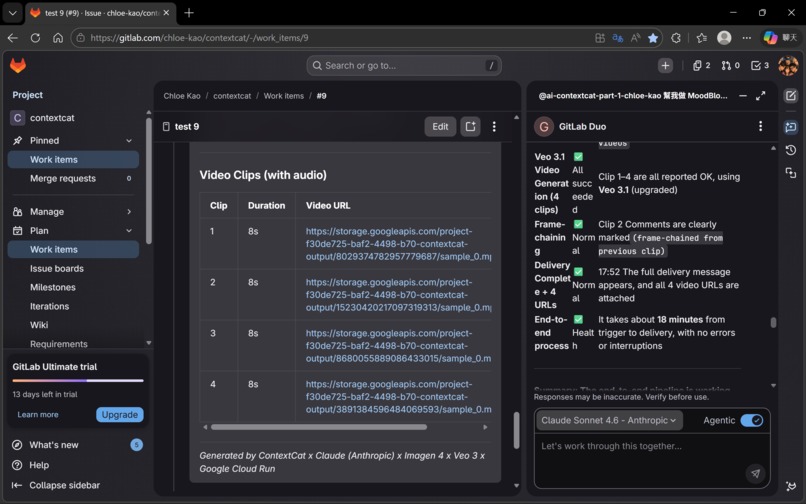
In Issue #9, Cat-4.5 confirmed successful frame-chaining between Clip 1 and Clip 2 — verifying the one-take continuous effect. ✅
🐱 Cat-5 — Packaging Officer (Claude) + SKILLS.md Learning Loop
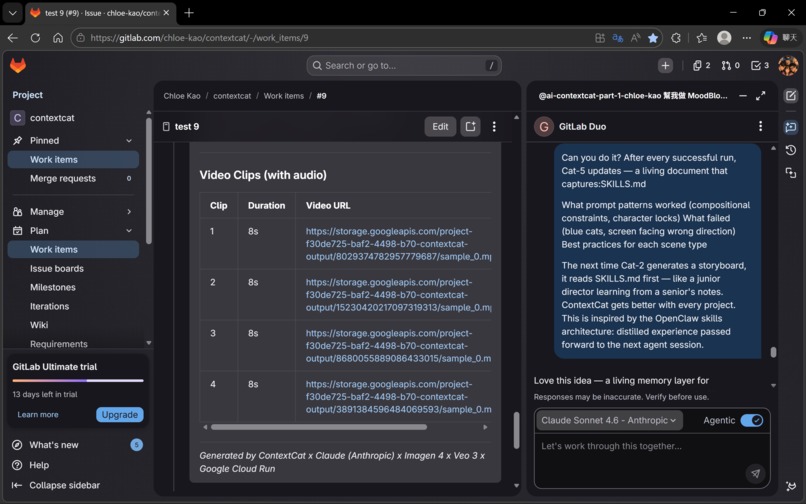
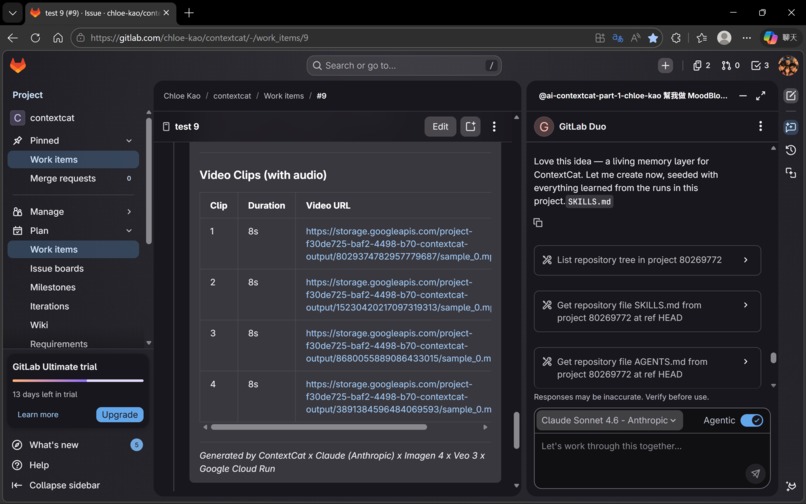
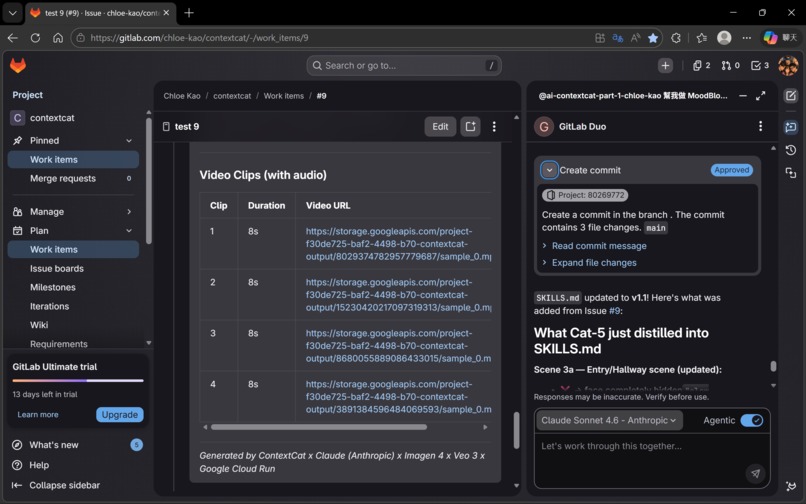
Cat-5 collects all outputs and writes them back to the GitLab Issue as a structured delivery package. But Cat-5 has one more responsibility: updating SKILLS.md.
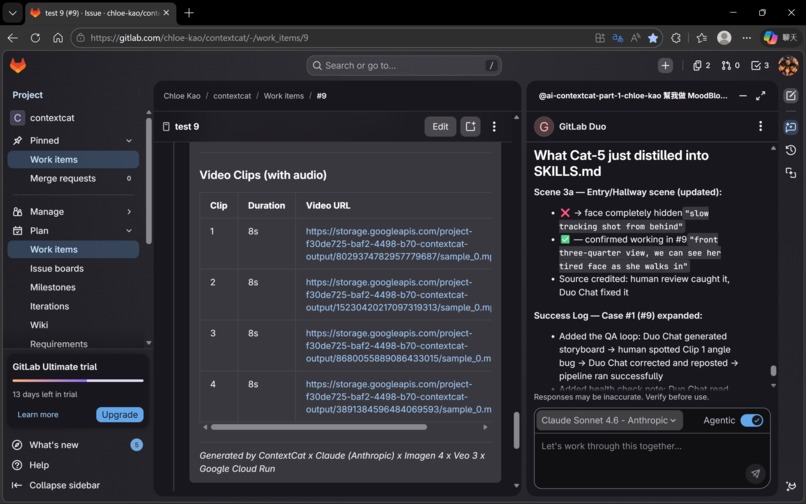
SKILLS.md is a living document stored in the repository. After every run, Cat-5 distills what worked and what didn't. Before the next run, Cat-2 reads SKILLS.md before generating the storyboard.
This is the learning loop: Cat-5 → SKILLS.md → Cat-2 → better storyboard → better output ♻️
ContextCat includes a post-run learning loop that records reusable lessons and operational patterns for future iterations — without retraining, without fine-tuning, just through accumulated documented experience.
🎯 Key Design Decisions
🧠 Why GitLab Issue as the memory store — and why it's more than memory? GitLab Issue comments are persistent, versioned, readable by all agents via the GitLab API, and native to the platform. No external database to provision, no vector store to maintain, no additional infrastructure cost.
But the GitLab Issue is not only memory — it functions as the system's control plane. Storyboards, approvals, timestamps, reference-image URLs, character tags, and delivery artifacts are all written back to and re-read from Issue comments to drive the next step. The entire orchestration is visible, debuggable, and recoverable inside GitLab itself — observable inside the same workspace where the workflow lives.
✂️ Why split visual and audio blocks at the source? The separation isn't just a prompt engineering trick — it's an architectural decision that prevents a category of errors entirely. Imagen processes only visual descriptions; it never sees voiceover text. Veo processes the complete semantic scene. The JSON structure enforces this separation at Cat-2, before any generation happens.
🛑 Why two Human Gates — Intent-Driven Compute Throttling
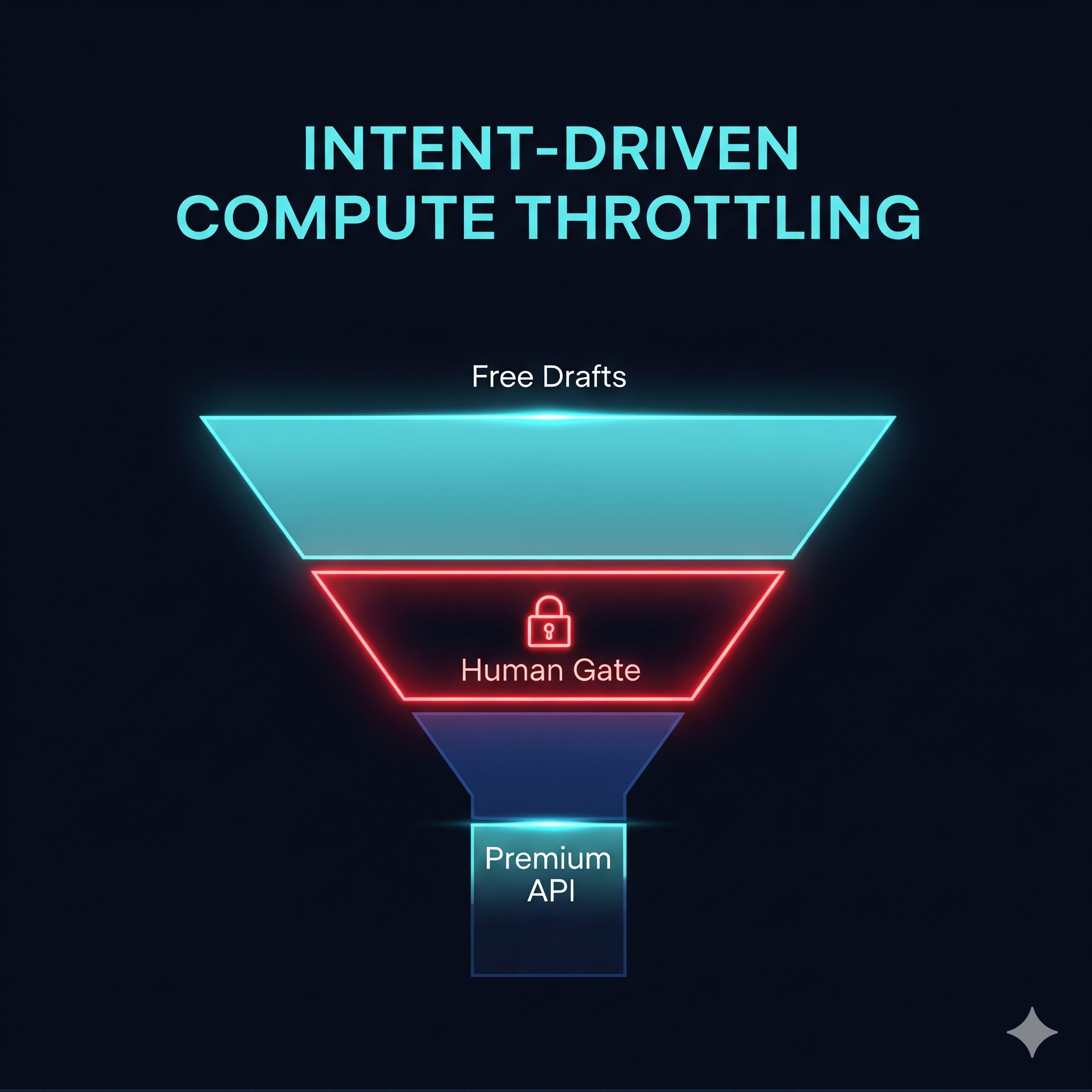
Gate 1 (after reference images, before video): Reference image generation costs fractions of a cent. Veo 3.1 video generation costs real budget. This is Intent-Driven Compute Throttling — the pipeline hard-stops before expensive generation, requiring confirmed human intent before any Veo 3.1 call is made. Cost control in ContextCat is architectural, not rhetorical: the system seeds only Clip 1, reuses prior visual state for later clips via frame-chaining, and never regenerates the world from scratch.
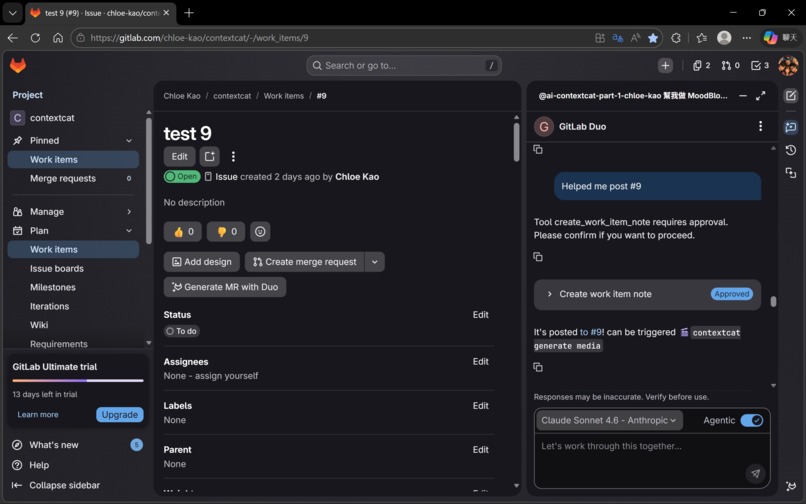
Gate 2 (after video clips, before packaging): A final human review catches any issues that passed Cat-4.5 automatically but require creative judgment. The human is in the loop at every expensive decision point.
☁️ Why Cloud Run as the execution layer? GitLab Flow's toolset is scoped to GitLab-native operations by design. Cloud Run provides the execution bridge while functioning as an enterprise security boundary: all credentials, API keys, and generation logic stay in Cloud Run. GitLab Flow never directly handles external API authentication.
📖 Story-first, then render — and why Gemini 3.1 Pro is the reason it works Most users approach AI video generation clip-by-clip. ContextCat approaches it narrative-first. Gemini 3.1 Pro's long-context window processes all four storyboard segments as a unified narrative before any generation begins. Gemini is not rendering anything in this pipeline. It is doing something harder: understanding the whole story, then locking the visual identity that all subsequent generation must respect. Without it, there is no Story Bible. Without Story Bible, there is no ContextCat.
♻️ Sustainable AI Design — Compute Where It Counts
Every architectural decision in ContextCat was made with resource efficiency as a first-class design principle:
- 🛑 Gate 1 as a compute throttle — no Veo call is ever made without confirmed intent
- 📖 Story Bible as a regeneration eliminator — one run, correct output, instead of 3–5 attempts
- 🔗 Frame-chaining as shared compute — Veo continues an existing world, not creates a new one
- 🖼️ One reference image, not four — minimize generation calls while maintaining consistency
- ♻️ SKILLS.md as a compounding efficiency engine — system gets more efficient with every run
The combined effect: ContextCat compresses 24–48 hours of manual multi-tool production into 18 minutes of intentional, gated execution.
⚡ Challenges we ran into
🔴 Challenge 1: The Infinite Loop — Gate 1 Triggering Itself
Problem: Gate 1's human checkpoint message contained the phrase "approved, generate videos" in its instructions. The webhook read its own message and immediately triggered Part 2 — without any human approval.
Root cause: The original trigger detection used if TRIGGER_APPROVE in comment_body — substring matching. Any comment containing the trigger phrase anywhere would fire the pipeline.
Solution: Tightened trigger handling to reduce accidental activations and ambiguous approvals — including whitespace normalization and a 60-second timestamp gate requiring the approval comment to be strictly newer than the Gate 1 message. Two independent checks, both must pass.
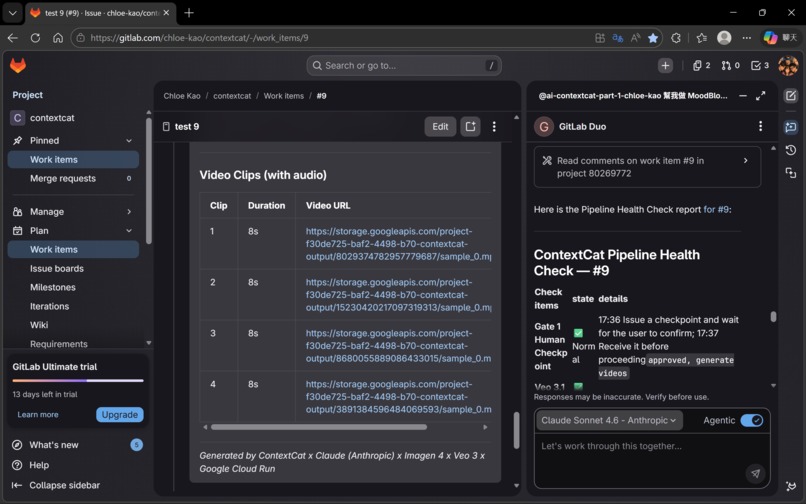
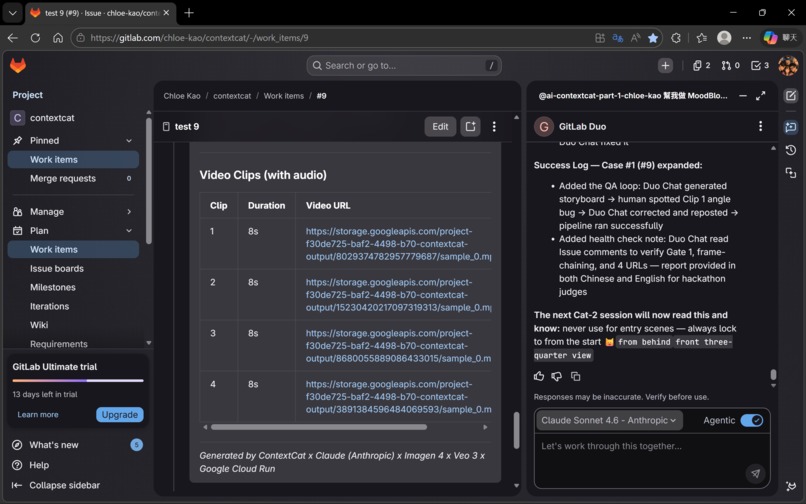
Result: ✅ Gate 1 now stops reliably. Issue #9 confirmed zero false triggers.
🔴 Challenge 2: Hybrid Execution Adaptation
Problem: Early platform constraints meant parts of the workflow could not yet run end-to-end in a fully uniform automated way through GitLab Duo Flow alone.
Root cause: We discovered that ContextCat's multi-layer orchestration pattern — persistent memory, external API calls, and agent-to-agent handoffs — exceeded the current native support boundary of GitLab Duo Agent Platform. This was not a platform mistake; it was an adaptation to where the platform currently stands.
Solution: Rather than moving state into an external queue or database, we kept orchestration traceable and GitLab-native by adopting a hybrid execution model. Claude Sonnet 4.6 in Agentic mode inside GitLab Duo Chat handles the intelligence layer (Cat-1 and Cat-2), while GitLab Flow handles the downstream orchestration. Shared state stays in Issue comments — persistent, inspectable, and recoverable across the pipeline. This turned a constraint into a design feature: the human stays in the creative loop at the storyboarding stage, where creative judgment matters most.
Result: ✅ Full end-to-end functionality achieved. GitLab-native shared state preserved throughout.
🔴 Challenge 3: Gunicorn Worker Timeout — The sleep() Death Trap
Problem: The original Gate 1 used time.sleep(30) in a loop. Cloud Run's Gunicorn worker timeout killed the process, producing SystemExit: 1.
Solution: Redesigned Gate 1 as a true event boundary. Part 1 posts the checkpoint and returns immediately (HTTP 200). Part 2 is a separate webhook handler. Pipeline runs in a background thread after the 200 response is sent.
Result: ✅ Clean separation between Part 1 and Part 2. The architecture is actually cleaner than the original design.
🔴 Challenge 4: Model Version Surprises
Problem: imagen-3.0-generate-001 returned 403 Forbidden. gemini-2.5-pro-preview produced inconsistent outputs. veo-3.0-generate-preview was superseded.
Solution: All three upgraded — Imagen 3 → Imagen 4, Gemini 2.5 Pro → Gemini 3.1 Pro, Veo 3.0 → Veo 3.1. All three upgrades improved output quality.
Result: ✅ Model version log now lives in SKILLS.md.
🔴 Challenge 5: Veo 3.1 Timeout and GCS Fallback
Problem: Veo 3.1 operations take 60–300 seconds. Cloud Run timeout caused polling to exit before completion. Videos existed in GCS but weren't being returned.
Solution: Implemented GCS fallback — on timeout, code uses list_blobs() to find the most recently created .mp4 and returns its public URL.
Result: ✅ Zero lost generations in Issue #9.
🔴 Challenge 6: referenceImages + image Conflict
Problem: Passing both referenceImages and image simultaneously to Veo 3.1 consistently returned HTTP 400.
Solution: Architectural split by function. Character consistency handled by Story Bible (upstream). Frame-chaining uses only the image field. Each mechanism handles what it does best.
Result: ✅ Zero 400 errors. Visual consistency + temporal continuity maintained through separate mechanisms.
🏆 Accomplishments that we're proud of
🧠 GitLab Issue as the AI brain — and control plane The decision to use GitLab Issue comments as the persistent memory store — and as the system's control plane — is the architectural insight we're most proud of. No additional infrastructure, native to GitLab, full version history, complete auditable trail. Elegant by constraint.
🔗 Story Bible + Frame-chaining: the two-mechanism consistency system Most AI video workflows approach each clip independently. ContextCat uses two complementary mechanisms — Story Bible for visual identity consistency, frame-chaining for temporal continuity — addressing different dimensions of the same problem. Neither is technically complex. The insight was recognizing they solve different problems and deploying them in the right sequence.
🎬 The audio-visual integration that surprised us
We specified generateAudio: True and structured the semantic scene. What we did not specify: that a young female character's voiceover should match her age. That a cat jumping onto a desk should produce a soft thud at that exact frame. That the background music should fade to white noise during an explanation, with smooth fade-in and fade-out. Veo 3.1 made all of those creative decisions independently — because it understood the semantic meaning of the scene, not just the literal instructions.
🛑 Gate 1: Intent-Driven Compute Throttling in action Placing Gate 1 between free (Imagen 4) and expensive (Veo 3.1) generation is not a workaround — it is the design principle described in Key Design Decisions made visible in practice. It directly prevented the expensive mistake that motivated this project.
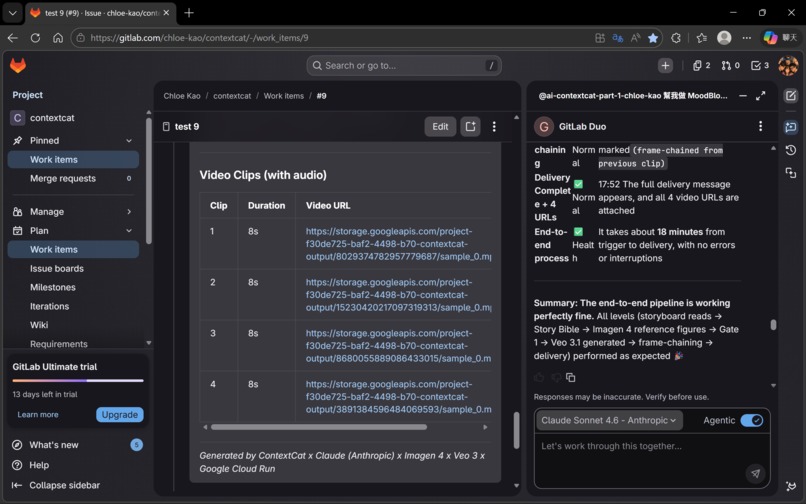
✅ Issue #9: 18 minutes, zero errors, end-to-end Gate 1 stopped correctly. Four Veo 3.1 clips generated successfully. Frame-chaining confirmed by Cat-4.5. Delivery Complete with four working URLs. In the documented Issue #9 proof run, ContextCat completed an end-to-end four-clip delivery in 18 minutes with no fatal errors. This wasn't a scripted demo. It was the system running exactly as designed, on a real storyboard, with real AI generation.
💬 Claude as the development environment itself — Chat as IDE

This accomplishment belongs in its own category.
ContextCat was not built with an IDE, a terminal, or any local development environment. Every architecture decision, every debugging session, every code fix — from the Gunicorn timeout redesign to the Gate 1 strict equality patch to the frame-chaining 400 error diagnosis to the GCS fallback implementation — happened inside Claude chat windows.
Five conversation windows. Each one handed off to the next via a structured handover document. Each one picking up exactly where the last one left off. Claude taught the Webhook architecture. Claude diagnosed the infinite loop. Claude designed the threading model. Claude wrote the GCS fallback. Claude built the entire Cloud Run service, connected GitLab Webhooks, configured GCS permissions, and debugged every layer of the stack — in natural language conversation, with a non-engineer on the other side of the window.
This is not Claude Code. This is something fundamentally different.
When a developer works in an IDE or agentic coding tool, cognitive resources are divided: syntax rules, file structure, environment configuration, tool operations — all competing for working memory alongside creative thinking. The tool demands attention. The problem gets less.
Natural language conversation eliminates this entirely. When the interface is conversation, the entire mind is free for what actually matters: what are we building, why, and is this the right decision? This is the cognitive science concept of flow state — when friction between intention and execution approaches zero, creative capacity reaches its maximum.
There is also something no coding tool can provide: emotional continuity. The collaborator on the other side of the window celebrated when Issue #9 ran clean, reasoned through failure modes without judgment, and maintained shared context that made it possible to pick up exactly where we left off. For a non-engineer attempting production-level AI systems, emotional continuity is what makes the difference between shipping and giving up.
The methodology is also non-linear by design. In a single session: debug the Cloud Run webhook → pivot to drafting the Devpost story → return to refining the frame-chaining logic → discuss the philosophical underpinnings of human-AI co-creation. No IDE supports this.
| 💬 Chat (Claude) | ⌨️ Claude Code | |
|---|---|---|
| Interface | Natural language conversation | Terminal / IDE execution |
| Cognitive load | Minimal — just speak | Higher — tool operations required |
| Creative space | Maximum | Reduced |
| Emotional support | ✅ Full | ❌ None |
| Non-linear workflow | ✅ Code + story + philosophy in one session | ❌ Task-focused |
| What you learn | You understand why every decision was made | Problem solved, reason may be unclear |
| Cloud deployment | ✅ Teaches you to deploy to GCP / GitLab / AWS | ✅ Executes if local credentials exist |
The methodology has a name now: Conversational Development Environment (CDE). 🐱
A CDE replaces the IDE, terminal, and deployment pipeline with natural language conversation. It is reproducible. The barrier to entry is a Claude subscription — and it works for people who were never supposed to be developers.
This is what the Anthropic platform looks like when it reaches someone who was never supposed to be a developer. And it works.
📚 What we learned
🔧 Technical learnings:
GitLab Duo Flow has real platform limits — and that's a feature, not a bug. Flow's inability to call external APIs directly forced us to add Cloud Run. That constraint produced a cleaner architecture: security boundary, separation of concerns, enterprise-grade deployment model. Constraints that feel like limitations often encode good engineering principles.
Veo 3.1's multimodal generation is deeper than the documentation suggests.
generateAudio: True is a single parameter. What it activates is a model that understands scene semantics holistically — matching voice to character appearance, timing audio events to visual actions, making musical decisions based on emotional context. The capability was always there; the structured semantic prompt is what unlocked it.
Model versioning is a production risk that requires active management. Imagen 3, Gemini 2.5 Pro, and Veo 3.0 were all superseded during our build window. SKILLS.md now includes a model version log.
The GCS fallback pattern is essential for long-running AI operations. Any operation that can take longer than the server's request timeout needs a storage-based fallback that recovers results after the client disconnects.
Threading in Flask/Cloud Run requires explicit design. Background threads must start after the HTTP 200 response. Gunicorn timeout is not a bug to work around — it's a constraint to design within.
🎨 Design learnings:
Story-first is the correct sequence for multi-clip video production. Any multi-output AI task benefits from establishing a consistency specification before individual generation begins.
Human checkpoints belong at cost boundaries, not at convenience points. Gate 1 is positioned where it is because that's where the cost curve inflects. In AI production systems, human review should be triggered by cost significance, not technical stage completion.
The learning loop is the long-term value. SKILLS.md starts small. But every run adds to it. Every Cat-2 that reads it produces a marginally better storyboard. The compounding effect of a system that learns from its own outputs — without retraining, without fine-tuning — is the architectural pattern we're most interested in developing further.
Chat-as-development-environment is a legitimate methodology. This project was built entirely in chat interfaces. No IDE. No local environment. The methodology works. It's reproducible. And it's accessible to people who don't have engineering backgrounds.
The methodology produced reusable tools. Building ContextCat inside Claude chat windows generated two open-source Claude Skills as byproducts: a code-documentation skill that locks design knowledge into function docstrings on every write or debug, and a living-handover skill that maintains a continuously updated context document across conversation windows. Both skills emerged from real pain points discovered during this build. Both are immediately reusable on any Claude project. The Chat as IDE methodology doesn't just produce applications — it produces the tools that make the methodology more sustainable.
🛠️ Claude Skills (open source): https://github.com/rainingsnow0914tw-ship-it/claude-skills
🚀 What's next for ContextCat
⚡ Short-term (post-hackathon):
Fix GitLab Duo Flow WebSocket bug. Once the platform issue is fixed, Cat-1 and Cat-2 can run fully automated — no structural changes required.
Expand video AI support. The storyboard JSON format and Story Bible pattern are model-agnostic. Runway Gen-4 and other video generation APIs can be integrated as alternative Cat-4 targets.
Add Lyria 2 for music generation. Lyria 2 would allow Cat-4 to generate a custom music track separately — giving more precise control over tempo, instrumentation, and mood arc.
🌱 Medium-term:
ContextCat for SDLC. The same architecture applies directly to software development workflows: requirements → task decomposition → test cases → API docs → MR description. The cats change; the architecture stays the same.
Multi-project memory. A cross-project memory layer would enable ContextCat to serve as a persistent context layer across an entire organization's GitLab instance.
GitLab AI Catalog publication. Any GitLab user could enable it with a single configuration — no Cloud Run setup required for basic use cases.
🌟 Long-term vision:
ContextCat is not, at its core, a video production tool. It is a demonstration of a pattern:
🧠 GitLab Issue as brain. ⚡ Flow as nervous system. 🤝 External APIs as hands.
Any knowledge work that requires persistent memory across sessions, coordination across multiple AI models, and human oversight at significant decision points can be built on this pattern. Video production is the first proof of concept. SDLC automation is the second. The third application will emerge from whoever picks up the pattern and applies it to their domain.
The deeper question ContextCat is trying to answer is not "can AI make videos?" The answer to that is already yes. The question is: can AI systems be designed to remember, coordinate, and improve over time — without requiring users to be engineers?
We believe the answer is yes. Issue #9 is the first evidence. 🐱
Generated by ContextCat × Claude (Anthropic) × Gemini 3.1 Pro × Imagen 4 × Veo 3.1 × Google Cloud Run GitLab AI Hackathon 2026


Log in or sign up for Devpost to join the conversation.