-
-
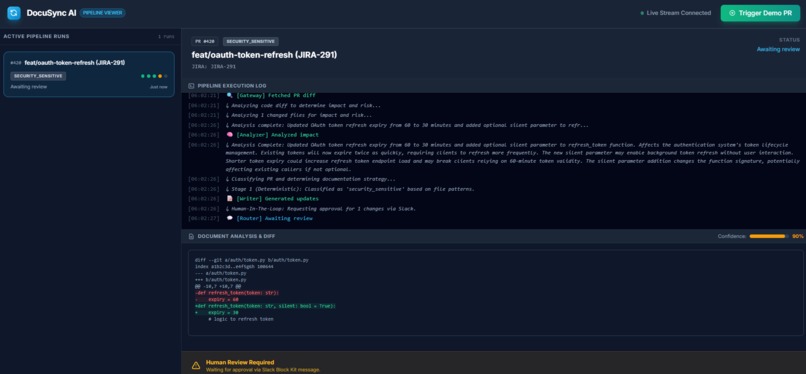
Dashboard displaying pipeline workflow
-
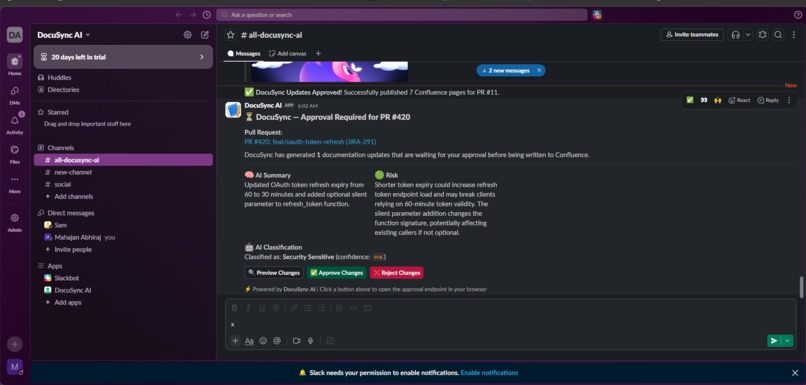
Slack approval request notification
-
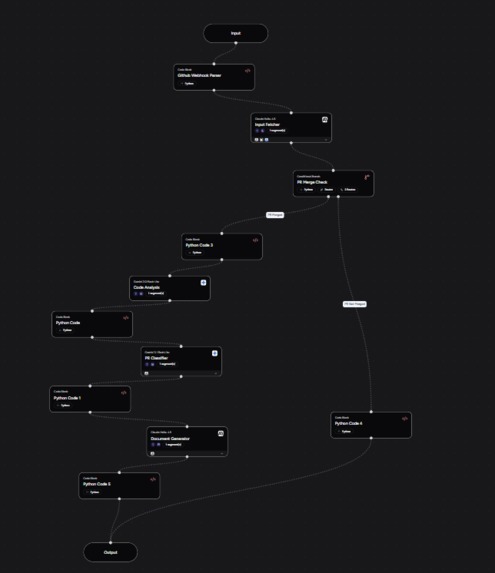
Complete Airia Studio Configured Pipeline
-
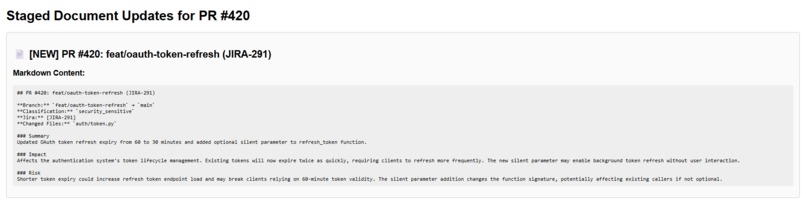
Preview of draft documents in confluence during approval
-
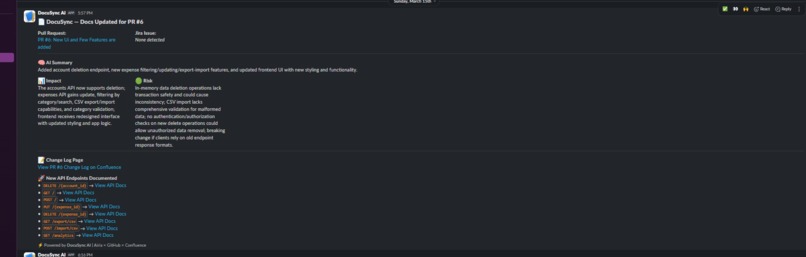
Final slack notification after updating the docs
-
Proof of agent submission in community






DocuSync AI
Inspiration
It started with a code review comment that genuinely annoyed me.
A teammate merged a PR that refactored a core API endpoint. The code was clean, the tests passed, the review was smooth. Two weeks later, a new engineer joined and spent half a day confused because the Confluence page still described the old behaviour. Nobody had updated it. Nobody had even thought to.
That's not laziness......that's just how it goes. Docs live in a different tab, in a different headspace. When you're deep in a PR, the last thing on your mind is switching over to Confluence and rewriting a page you haven't opened in months.
I kept thinking: this is exactly the kind of work an agent should be doing. The context is all there — the diff, the PR description, the linked tickets. A human reads all of that and writes a doc update. Why can't a chain of agents do the same thing, automatically, the moment the PR merges?
That question became DocuSync AI.
Short Description
DocuSync AI is a multi-agent system that automatically keeps your Confluence documentation in sync with your GitHub codebase. Every time a Pull Request is merged, a pipeline of AI agents figures out what changed, finds the affected docs, and updates them — no human intervention required. It's documentation that maintains itself.
How I Built It
The core idea was a five-agent pipeline that wakes up on every GitHub PR merge webhook and figures out what — if anything — needs to change in Confluence.
The Agent Pipeline
| Agent | Role |
|---|---|
| Reader | Parses the PR — title, diff, linked tickets |
| Scout | Searches Confluence for pages affected by the change |
| Writer | Drafts updated documentation using the PR diff as context |
| Publisher | Pushes the update to Confluence via the REST API |
| Notifier | Posts a Slack summary with page link and confidence score |
The names used for agents here are just for understanding, they may vary in our project.... Each agent has one job. That was a deliberate choice.
The Confidence Gate
Not every PR needs a doc update, and not every update should publish without a human glancing at it first. So I built a confidence gate that routes each PR into one of three buckets:
$$ \text{Action} = \begin{cases} \text{Auto-publish} & \text{if } c \geq 0.85 \ \text{Human review (HITL)} & \text{if } 0.60 \leq c < 0.85 \ \text{Skip} & \text{if } c < 0.60 \end{cases} $$
High confidence, low-risk changes go straight through. Ambiguous ones — maybe the diff touches three different systems, or the PR description is vague — get flagged for a quick human review before anything goes live.
Stack
- Backend: FastAPI + Python
- Agents: Orchestrated via Airia, each scoped to a single responsibility
- Integrations: GitHub Webhooks → Atlassian Confluence API → Slack API
- Frontend:HTML pages with SSE for dashboard real time event fetching
- Storage: SQLite for run history and stats
What I Learned
Honestly, the hardest part wasn't the AI — it was the plumbing.
I learned pretty quickly that agent design is really interface design. If Reader passes a messy, bloated payload to Scout, the whole chain degrades. I spent more time thinking about what each agent receives than what it does.
The sneakiest bug was JSON serialisation. I was constructing prompts with
f-strings and embedding JSON inside them, which caused values to arrive
double-escaped on the other end. Completely silent failure — the pipeline ran,
the output just looked wrong. Fixed it by switching to structured Python dicts
and writing a parse_if_string helper. Obvious in hindsight.
I also learned that thirteen PR types are not the same problem. A dependency bump, an endpoint refactor, a config change, a new feature — they all interact with documentation differently. Mapping that case matrix out early, before writing a single line of agent code, saved me from a lot of rework.
Challenges
The webhook payload problem. Raw GitHub PR payloads are enormous — hundreds of nested fields, most of which mean nothing to a documentation agent. Passing them straight into context bloated token usage and made prompts noisy. I ended up writing a preprocessing step that strips everything irrelevant and hands the pipeline a clean, minimal object.
Silent failures are the worst kind. Early on, the pipeline would stall somewhere upstream with no indication of where or why. I added structured logging at every agent boundary after that. If something breaks, I want to know exactly where.
Saying no to myself. At various points I wanted to add a knowledge graph, semantic search across Confluence, a diff visualisation layer. All genuinely useful. All deferred. Shipping a clean, end-to-end pipeline felt more valuable than a half-built feature list — so I held the line and saved the ambitious stuff for next phase of development.
What's Next
- A
/docs-healthendpoint exposing Confluence page staleness at a glance - Richer per-PR context: AI-generated summaries and confidence breakdowns surfaced alongside each run
- Persistent historical stats so trends become visible over time
- A knowledge graph layer for tracking cross-page dependencies — so DocuSync knows that updating this page probably means that page needs a look too
Public Link: https://community.airia.ai/import-agent/ociuxDdcT2A3m16RAmiDzdYyyD6pUVvtgMyh1uFRTXr (One-time sharable link)
https://community.airia.ai/import-agent/Tx9lu8YielUU0LStl0yapA65Zg78f3NFge2VqFTJd4n(One-time sharable link)

Log in or sign up for Devpost to join the conversation.