-
-
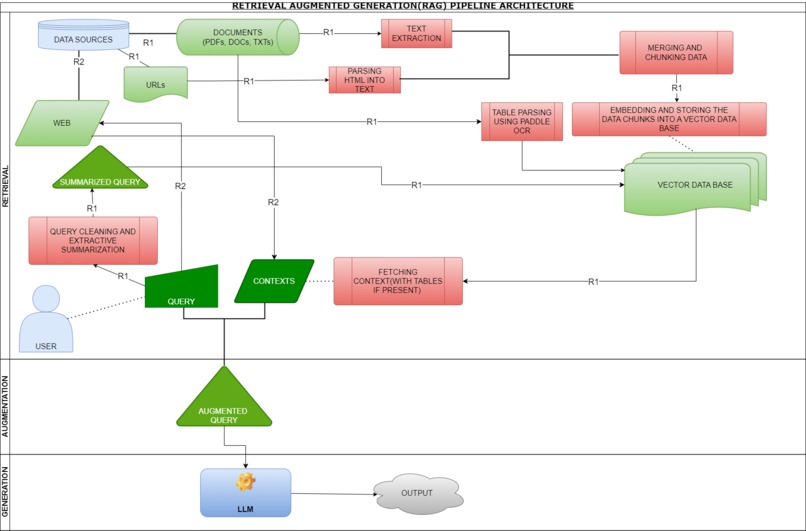
Advance RAG-Pipeline: Integrates PDF, URL, web retrievers for efficient retrieval.

The inspiration behind the development of our Advanced RAG-Pipeline stems from the pressing need to enhance academic research and learning. Researchers and students often struggle to efficiently retrieve accurate information from vast amounts of data. Our goal was to create a system that streamlines this process, making it more accessible and effective for the academic community.
Our Advanced RAG-Pipeline is specifically designed to improve the accuracy and efficiency of information retrieval for academic purposes. It leverages advanced retrieval-augmented generation techniques to fetch precise answers from PDFs, URLs, and the web. The system is built to support the diverse needs of researchers and students by providing quick and accurate information, thus enhancing their academic experience.
We built the Advanced RAG-Pipeline using a combination of cutting-edge technologies. The project incorporates Langchain, Hugging Face Transformers, PaddleOCR, and cv2. The pipeline was tested extensively on over 50+ documents and 500+ questions during the alpha-testing phase, achieving an efficiency of 92%. Our team focused on developing an efficient context-fetching system to ensure the accuracy and reliability of the retrieved information.
One of the main challenges we faced was ensuring the accuracy and relevance of the information retrieved by the pipeline. Balancing the speed of information retrieval with its accuracy required fine-tuning and rigorous testing. Additionally, integrating various technologies and ensuring their seamless interaction posed significant technical challenges.
We are proud to have developed a highly efficient RAG-Pipeline that achieves an impressive efficiency rate of 92%. Our system has demonstrated its capability to accurately retrieve and generate information, significantly benefiting the academic community. We are also proud of the collaborative effort and innovation that went into overcoming the technical challenges we faced.
Through this project, we learned the importance of interdisciplinary collaboration and the value of combining various technologies to achieve a common goal. We gained deeper insights into the complexities of information retrieval and the potential of RAG techniques in enhancing academic research and learning.
The next steps for DyausAI involve further refining and expanding the capabilities of our RAG-Pipeline. We plan to conduct more extensive testing across different academic domains to ensure its versatility and effectiveness. Additionally, we aim to explore potential partnerships with academic institutions to implement and demonstrate the benefits of our system in real-world academic settings.
Built With
- beautiful-soup
- chroma
- duckduckgo
- flask
- huggingface
- langchain
- numpy
- opencv
- openpyxl
- paddle
- pandas
- pil
- python
- torch
- transformer

Log in or sign up for Devpost to join the conversation.