-
-
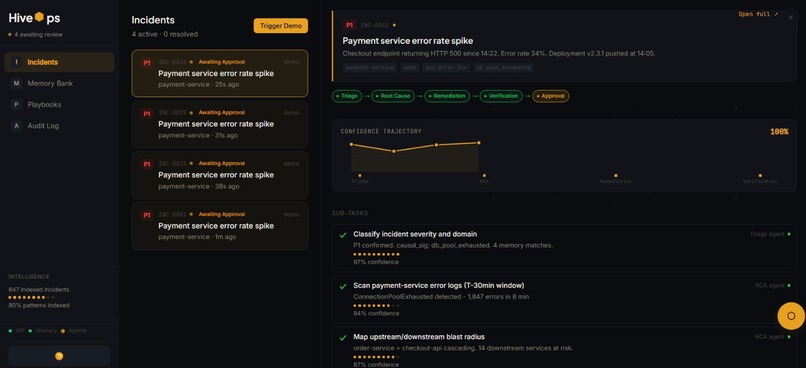
Incidents
-
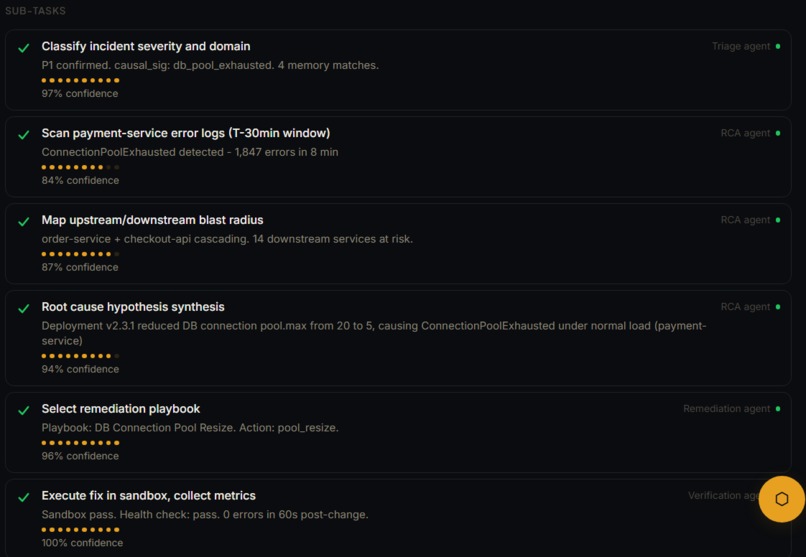
Agent Sub tasks
-
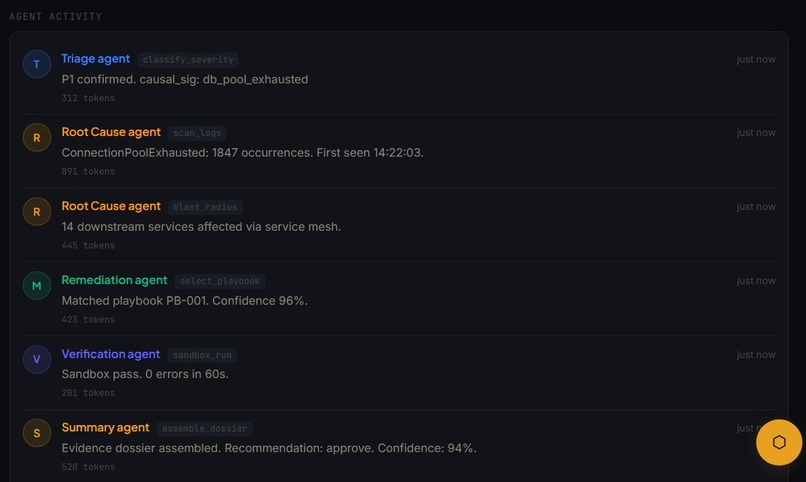
Agent activities
-
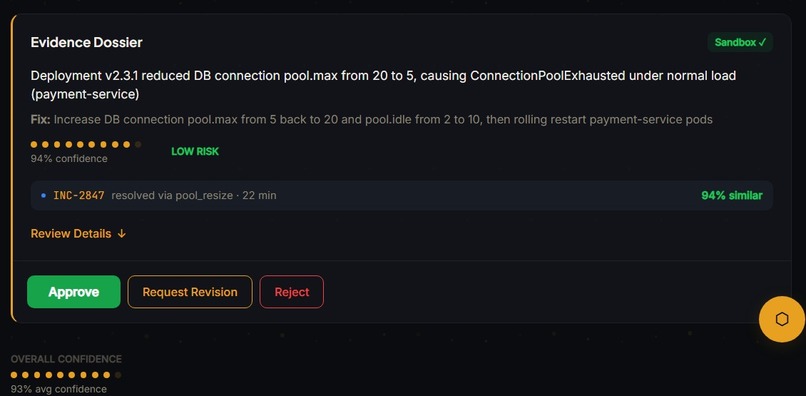
Approval Stage
-
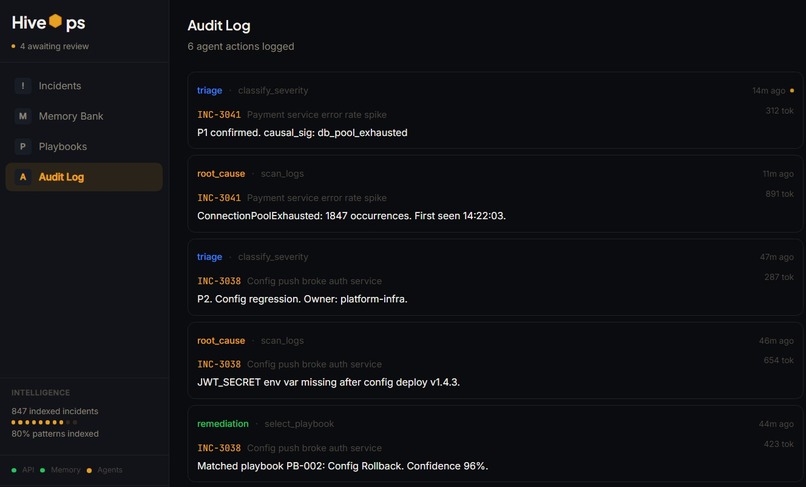
Audit Logs
-
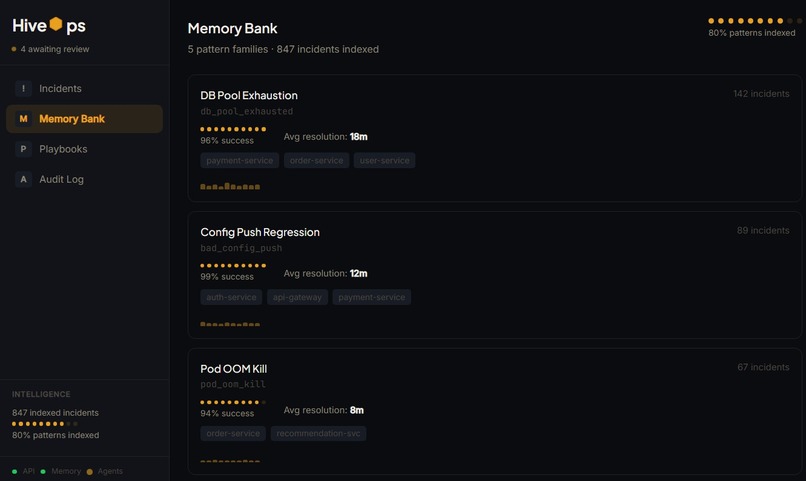
Memory Bank
-
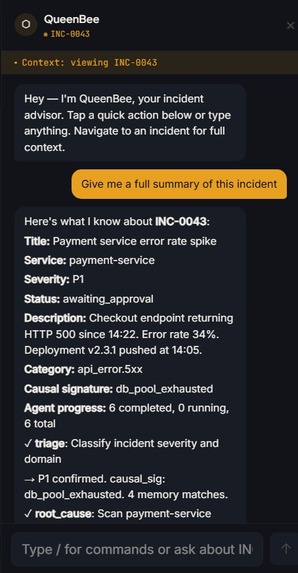
Chatbot
-
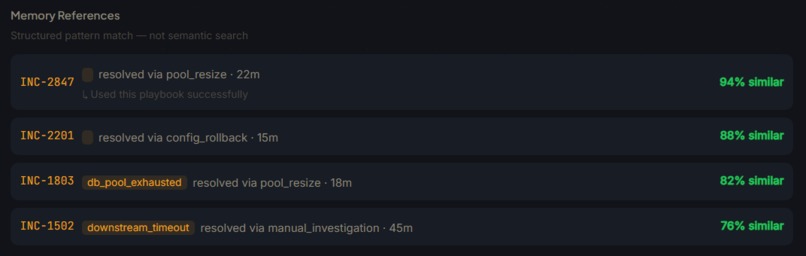
Past similar solved cases
-
Git diff after agents implement the fix









Inspiration
It's 2am. A P1 fires, you're on call. Something broke and you spend the first hour not fixing it, just figuring out what it even is. A similar outage happened six months ago. Someone wrote a fix. It worked. And now that knowledge is buried in a closed ticket that nobody searches during an incident. Each minute taken to solve the issue costs the company precious customers and profits. What if there was a system in place that could have the fix ready, implemented and tested before you washed your face and opened your laptop for you to review and approve?
What it does
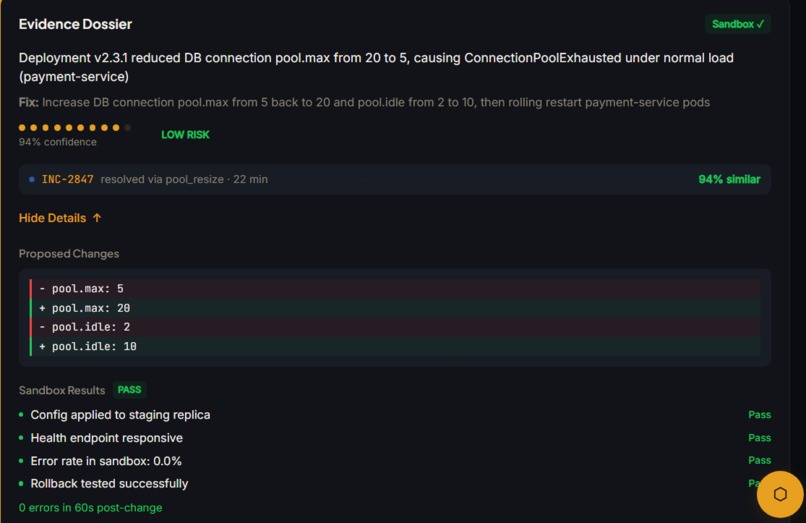
We built HiveOps, an agentic AI incident resolution platform that ingests incoming service tickets and orchestrates a fully an end-to-end pipeline to perform triage, root cause analysis, remediation (in a sandboxed environment) and verification with a human feedback step.
The coordinator agent decomposes the incident into sub-tasks, assigns the sub tasks to smaller agents (which have specialized skills), queries and extracts similar past incidents (using progressive disclosure technique with Hex API) and understands how they were fixed in the past. Every proposed fix is simulated and tested before reaching the human approval step so that there is no production risk.
The whole pipeline outputs the root cause, fix steps, confidence score, risk level and the sandbox results for a human to review to Approve, Reject or Request revision so that the model can learn from its mistakes. We also implemented an incident-aware conversational interface with "/" (slash) commands to ask any questions related to the live incident.
How we built it
Backend
Runtime: Python 3.11 + FastAPI + uvicorn (async throughout)
Agent System Each agent is an async function that calls Claude via the Lava API gateway (OpenAI-compatible, routes to 'claude-sonnet-4-20250514'). Agents receive a shared incident context object and append structured JSON output. Every agent call is wrapped in a 'tenacity' retry decorator with exponential backoff, and a JSON parse fallback handles malformed LLM responses without crashing the pipeline.
Orchestrator The orchestrator agent runs first and returns a 'pipeline_config' - an ordered list of agent names and their input mappings. This allows the coordinator to skip agents irrelevant to the incident type (e.g. a disk exhaustion incident doesn't need a 'downstream_timeout' verification pass).
symptom → investigation steps → root cause → fix → outcome
Memory: Progressive Disclosure
We are using Hex as a Long-term incident memory bank. Hex acts as a query-able store of all past resolved incidents. When a new incident arrives, the system queries Hex with the current incident's service, category, and causal_sig to find historically similar incidents.
Loading full incident history into every agent prompt would blow the context window on high-volume organizations with queries using Hex API. We implemented a 4-stage loader based on progressive disclosure techniques:
| Stage | Content | Tokens (approx) |
|---|---|---|
| 0 | Match count only | ~20 |
| 1 | Incident headlines + severity | ~200 |
| 2 | Root cause + outcome summary | ~800 |
| 3 | Full resolution path + playbook | ~3,000 |
Agents request escalation explicitly. Stage 3 is only loaded when the root cause agent determines the historical match is structurally similar.
Database Supabase (Postgres) handles persistent storage for incidents, sub-tickets, audit logs, and agent traces. A singleton pattern wraps the connection - not re-instantiated per request.
Sandbox The sandbox module accepts a proposed 'RemediationAction' and returns a 'SandboxResult' with simulated before/after state.
Frontend
Stack: React 19 + TypeScript + Vite + TailwindCSS + Framer Motion + Zustand + React Query
Split View Architecture Desktop layout uses a Gmail-style split view: incident list on the left, detail panel slides in on the right via a dot-burst entrance animation. The detail panel is conditionally rendered - not hidden - to prevent unnecessary DOM weight on mobile.
Real-Time Updates Incident status and sub-ticket progress stream over WebSocket. React Query polls as a fallback for environments where WebSocket connections drop.
Confidence Sparklines Each evidence dossier renders a pure SVG sparkline showing how agent confidence scores evolved across the pipeline steps - built without a charting library to keep bundle size minimal.
HiveUI Component System
All UI primitives share a hexagon motif: HiveLoader (7-dot hex arrangement), HivePulse (ring animation), HiveProgress (hex-segment fill), HivePattern (dot background), HiveDivider. Theming via CSS custom properties with light/dark mode support.
Mobile Bottom tab navigation with safe-area padding. QueenBee chat panel manages keyboard displacement explicitly - input floats above the virtual keyboard on iOS and Android via viewport resize detection.
Infrastructure
| Service | Provider | Notes |
|---|---|---|
| Frontend | Vercel | Preview + production deployments |
| Backend | Render | Python 3.11 pinned, env vars per environment |
| Database | Supabase | Managed Postgres, real-time subscriptions |
| LLM | Lava API | OpenAI-compatible gateway to Claude |
| Memory | Hex API | Structured SQL incident matching |
Challenges we ran into
| Challenge | Root Cause | Resolution |
|---|---|---|
| Token budget blowout | Feeding full incident history to all agents exceeded context limits for high-volume orgs | Built 4-stage progressive memory loader; agents request escalation only when needed |
| LLM output instability | Agents under latency pressure occasionally returned malformed JSON | Added tenacity retry on all agent calls + JSON parse fallback that extracts partial data rather than failing hard |
| Orchestrator over-routing | Early builds ran all 6 agents on every incident, wasting tokens on irrelevant passes | Orchestrator now returns a pipeline_config - a dynamic agent sequence customized per incident type |
| WebSocket + React Query conflict | Duplicate state updates when both WebSocket and polling fired simultaneously | WebSocket takes ownership of live incidents; React Query polling is suspended when a WebSocket connection is confirmed active |
Accomplishments that we're proud of
1. A real end-to-end pipeline with no smoke and mirrors Every stage - webhook intake, orchestration, agent execution, memory query, sandbox simulation, human approval - is wired together and functional. The demo runs the same code path a production deployment would. We didn't stub the agent pipeline behind a fake progress bar.
2. The progressive memory system Most RAG implementations dump everything into the context and hope for the best. Our 4-stage loader is genuinely novel for incident tooling: it treats historical context as a resource to be budgeted, not a feature to be maximized. The result is faster agent responses and lower hallucination rates on memory-grounded claims.
3. Structured SQL matching over embeddings and why that's the right call For incident data, interpretability matters. When the system says "this looks like a past incident," an SRE needs to understand why. Vector similarity scores don't give you that. Our weighted SQL matching on service, category, causal signature, and severity is debuggable, tunable, and produces results an engineer can reason about.
4. The mandatory human approval gate as a first-class architectural constraint This wasn't a last-minute safety disclaimer. The entire evidence dossier format - root cause, fix steps, confidence score, risk level, sandbox diff - was designed around the question: what does a tired engineer need to see in under 10 seconds to make a confident approval decision? The gate is the product, not a footnote to it.
5. A production-quality UI built in 24 hours The hexagon motif isn't decoration - it's a coherent design language that runs from the brand mark through the loader animation through the component library. HiveUI is a real component system with documented primitives, not a pile of one-off styled divs.
What we learned
We learned that orchestrator-first agent design is meaningfully better than monolithic prompting for structured pipelines. Giving one agent the job of planning the sequence, and the authority to skip irrelevant steps, produced more coherent outputs than routing every incident through a fixed pipeline regardless of type.
What's next for HiveOps
Model improvements Fine-tune a triage classifier on org-specific incident history to improve severity classification and causal signature prediction over time.

Log in or sign up for Devpost to join the conversation.