-
-
IndyVerse
-
Dasboard


Project Story
Inspiration
Emergency response systems today are largely reactive. Dispatchers depend on 911 calls, which often arrive late, lack context, or fail to capture the full severity of a situation. In fast-moving emergencies like physical altercations or medical collapses, every second matters — yet critical delays still occur due to fragmented information and manual coordination.
We were inspired by a simple question: What if cities could detect emergencies the moment they happen, instead of waiting for someone to call for help?
With the increasing availability of camera infrastructure and advancements in AI, we saw an opportunity to transform passive video and audio feeds into real-time public safety intelligence, specifically tailored for a city like Indianapolis.
What It Does
Our system is an AI-powered emergency coordination platform that combines computer vision and audio analysis to detect critical incidents in real time.
It can identify events such as:
physical altercations individuals collapsing or lying motionless distress signals like “help” or “call 911” bystander reactions indicating urgency
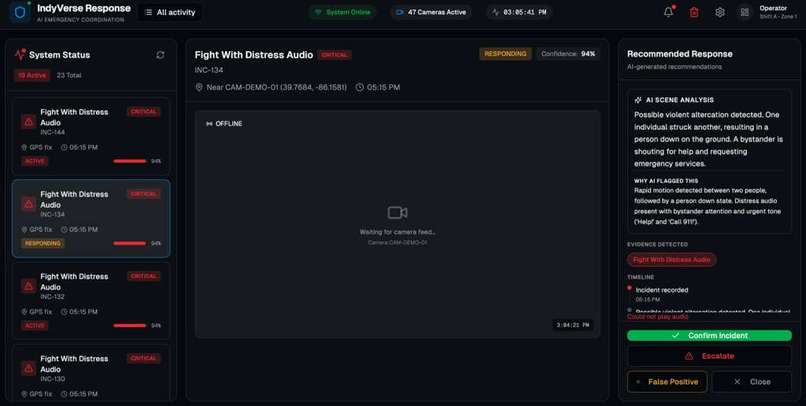
Instead of producing raw model outputs, the system fuses these signals into a single incident command card, which includes:
a clear summary of what happened severity and confidence levels recommended responders (Police, EMS) suggested hospital destination with ETA reasoning behind each decision
To ensure reliability, the system includes a human-in-the-loop review step, allowing an operator to confirm, escalate, or dismiss incidents.
We also integrated voice alerts using ElevenLabs, enabling the system to announce high-severity incidents in real time — making the platform more actionable and immersive.
How We Built It
We designed the system as a layered pipeline:
- Ingestion Layer Video frames from camera feeds (live or prerecorded) Audio input for distress detection Metadata such as camera ID and location
- AI Detection Layer
We used computer vision techniques (OpenCV + model-based reasoning) to detect:
motion patterns (rapid movement, collapse, inactivity) multi-person interactions (fights, crowd behavior)
In parallel, we incorporated audio signals (distress phrases, yelling) to enhance detection confidence.
- Event Fusion Engine
Instead of generating multiple noisy alerts, we built a fusion layer that combines:
visual signals audio signals temporal patterns
- Decision & Recommendation Engine
We implemented rule-based logic to determine:
who should respond (Police, EMS, or both) severity level recommended medical destination
- Frontend Dashboard
We built a real-time dashboard that displays:
live incident cards severity indicators responder recommendations hospital suggestions human review controls
- Voice Layer (ElevenLabs)
We integrated ElevenLabs text-to-speech to generate:
spoken incident alerts operator feedback (e.g., “Incident confirmed”)
This adds a real-world operational feel to the system.
Challenges We Faced
- Balancing accuracy vs. speed
We quickly realized that training a perfect model was not feasible within hackathon time constraints. Instead, we focused on reliable signals and strong system design, combining motion analysis, rules, and multimodal inputs.
- Avoiding noisy detections
Raw detections can be messy. We solved this by building an event fusion layer that consolidates multiple signals into one clean incident.
- System integration
Coordinating frontend, backend, and detection pipelines was one of the hardest parts. We had to carefully design interfaces so that:
detection outputs could plug into backend logic backend data could cleanly drive the UI
- Demo reliability
Live systems are fragile. To ensure a smooth demo, we implemented:
seeded dummy incidents prerecorded fallback scenarios
This guaranteed that the system would always demonstrate correctly.
- Realism vs. scope
We wanted to simulate a full emergency ecosystem (police, EMS, hospitals), but had to keep the implementation lightweight. We focused on high-impact features like:
incident command cards responder recommendations hospital suggestions What We Learned System design matters more than raw model accuracy in real-world applications Combining multiple weak signals (vision + audio + motion) can produce strong results Human-in-the-loop is critical for safety-critical AI systems Clear, actionable outputs (not raw predictions) make AI systems usable Demo reliability is just as important as technical correctness in hackathons What’s Next
In the future, we would:
integrate real-time camera streams incorporate live traffic APIs for more accurate routing expand hospital capability matching improve audio detection with more robust models deploy the system in collaboration with local agencies Final Thoughts
Our project transforms passive infrastructure into proactive intelligence.
Instead of waiting for emergencies to be reported, we enable cities like Indianapolis to detect, understand, and respond to incidents in real time — improving coordination, reducing response time, and ultimately saving lives.
Built With
- atlas
- elevenlabs
- express.js
- llm
- mongodb
- node.js
- opencv
- python
- react
- render
- socker.io
- tailwind
- typescript
- vercel
- vite
- yolo

Log in or sign up for Devpost to join the conversation.