-
-
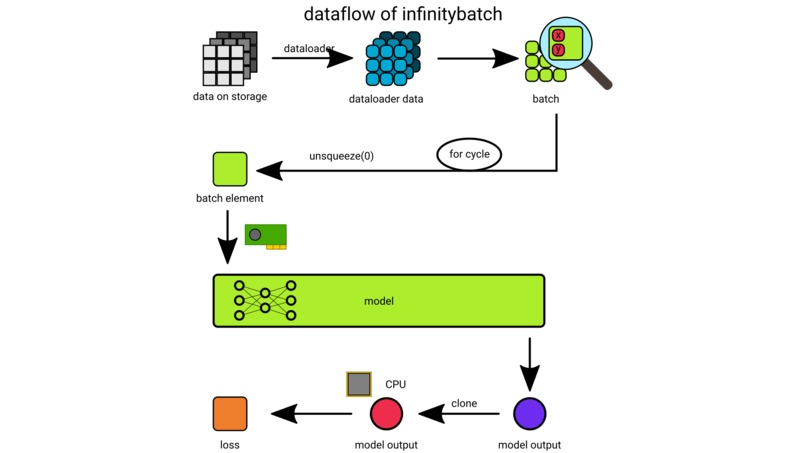
dataflow
-
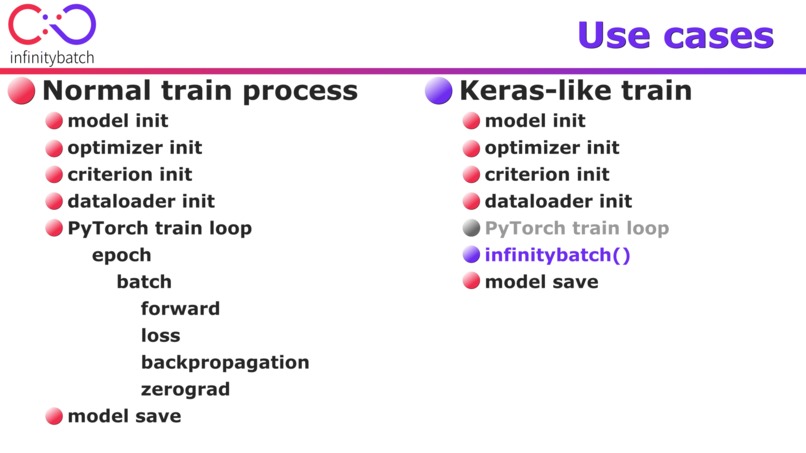
use case 01: Keras-like training
-
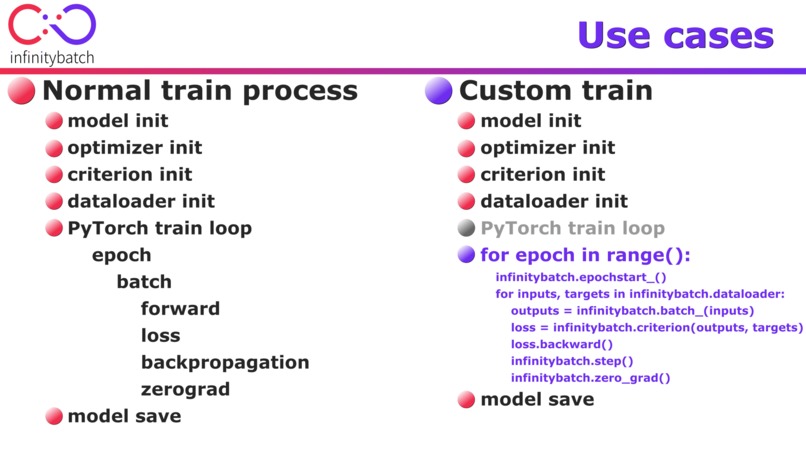
use case 02: Custom training
-
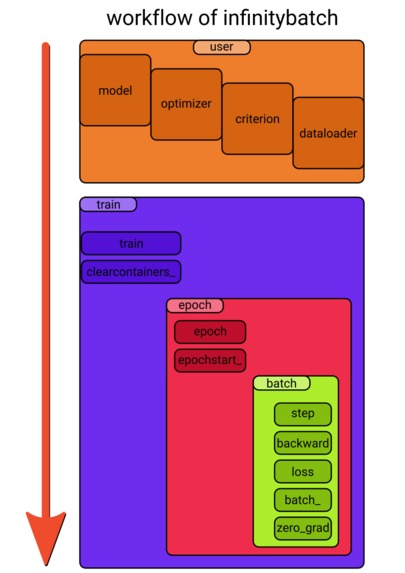
workflow
-

cover





infinitybatch
Infinitybatch is an open source solution for PyTorch that helps deep learning developers to train with bigger batch size than it could be loaded into GPU RAM through a normal PyTorch train loop.
The core concept of the idea comes from the fact that GPU time is expensive and the usage of own GPU cluster or a cloud based GPU service has to be optimized to be cost efficient. Furthermore, developers and researchers regularly have limited access to GPU. However, CPU based training mostly allows higher batches than a normal GPU could provide, it is much slower. Infinitybatch helps to use GPU during training with bigger batch size thanks to the special unloading and uploading process that manages the GPU RAM to avoid memory overrun.
Inspiration
Nowadays computers at home or at companies usually contain GPU. However, these GPUs have very poor computational resources compared to dedicated deep learning GPUs like Tesla or Quadro series. Despite of limitation, the home or company GPU, it can be used for experimenting, testing new theories, trying new approaches and learning. Using cloud based GPU services can be expensive especially when the whole concept of model is made on the cloud. A properly trained model is based on a lot of dead ends. A huge amount of model architectures are in the trash after the training phase. A developer or researcher has to try different batch sizes with different batch-creation technology and tune other hyperparameters as well. If any of these steps can be used on own GPU, it saves a lot of money and internet bandwidth compared with a cloud based service.
The simplest way to solve batch size problem is to use little batch size that fits into GPU memory in all circumstances. There are a lot of forum topics about possible solutions. Using the same batch size, compared to a PyTorch normal train loop, the result with the existing solutions will be slightly different. However the results should be the same.
The lack of a real solution provoked us to explore how painful the problem is. That’s why we made a survey. We got more than a thousand responses. 33% percent of people quite often get CUDA memory error during training. More than 70% percent try different batch size usually. Now, we have proof, that the problem is real and really burning.
What it does
Infinitybatch is an open source solution that helps deep learning developers to train with bigger batch size than it could be loaded into GPU RAM. It is built under MIT license.
The only one limitation with Infinitybatch is that at least the model and one element at the same time must be fit into GPU-RAM.
Infinitybatch fits perfectly into PyTorch and PyTorch’s workflow. It does not override or exploit any PyTorch’s function or class. A train loop with infinitybatch suits smoothly into the logic of a common train loop. The user initializes a model, an optimizer, a criterion and a dataloader and the train can just begin. This kind of workflow guarantees compatibility through different PyTorch versions in the future as well. If the torch.stack and torch.clone will be the same and the core concept of autograd function will remain, there is no harm to this compatiblity.
How we built it
Our main goal was to make a solo Python solution which is robust enough to sustain some version change of PyTorch and is easy to use without major issues. Therefore we had to figure out how to satisfy our needs in Python level.
There are two main concepts in infitybatch that can be considered as unique or special. One conception is the way how we treat the output of the forward pass of a model and the other conception is to separate forward-pass and backpropagation devices.
The output of a model should be treated carefully since it contains a computational graph which is essential to be preserved for the backpropagation process at least till the calculation of the loss. PyTorch doesn’t let developers to access autograd directly on the purpose to ensure its proper workflow at any circumstances. This limit slightly encumbers to find working solutions for a couple of problems like this which is solved by infinitybatch now.
The ability to separate forward and backward devices hardly hangs together with the ability to preserve computational graphs. Graphs are essential for the loss to backpropagate. If the graph is broken for any reason the backpropagation will lead to bad results. This is the reason why common solutions for increasing batch size on GPU RAM don't work.
Infinitybatch clones the output of the model with its computational graph and this clone is moved away from the device of the model to the device with more memory – usually CPU RAM – where the backpropagation will occur. As the whole batch is forwarded the outputs get stacked and together with targets the loss is calculated. The computation of the loss happens on the backward device however it affects the data on the forward device as well. All of the rest of training is just like any other PyTorch model training and this means real freedom for a developer who tries out infinitybatch.
Challenges we ran into
We figured out that we have to get more familiar with the core conception of PyTorch’s autograd system and memory usage conception in general. Our solution touches the core part of this framework. We had a further block in our development since we targeted to make a solo Python solution without going to the C++ level. The reason is quite easy; we wished to have a simple but robust solution that is easy to use and that hopefully resists some version changes in the near future.
Accomplishments that we're proud of
We made a survey to measure how painful the problem is that we try to solve. We had interesting feedback and we had the luck of getting the opinion of more than a thousand developers from all over the world.
We made the Tesla Index inspired from our background research. We plan to continue the development of this index because we are thinking it will break kind of walls in the world of developers. The idea of the Tesla index comes from The Economist’s Big Mac Index. That index focuses on the purchasing power parity and national market and goods, but programmers are living in a globalized world where every item can be purchased from the global market. Tesla Index compares the local salaries through the most expensive Tesla card that is available at the moment.
We made a complete book about the background of the problem; our research, market analysis and our solution as well.
What we learned
We learned a lot about the discourse around batch size and hyperparameter optimization in general. We also experienced deep fundamentals of the PyTorch autograd system and we are thinking we have a better overview of its conception. At least we hope so.
What's next for infinitybatch
We have a detailed future plan for this project.
eval()
However making evaluation with infinitybatch is very easy for user who like to have “canonical way” for everything we plan to implement .eval() function separately. The hardest task of this implementation is to relate to dataloaders because of the freedom use that we can provide at this point.
PyPi
Since infinitybatch is a production ready module it could be right now loaded into PyPi.org to be usable as a Python package globally. We plan to wait till the outcome of this hackathon gets clear and then we will upload this package together with a ReadTheDocs documentation and with a lot of examples and tests as well.
Event monitor
To support do-it-yourself train loops even more we plan add an event monitor to infinitybatch. This feature could warn the user if they leaves out something important from the forward-backward process.
Improvement of warnings
A good and highly configurable warning system is needed for infinitybatch in the future to be able to serve experimenters and real experts at the same time. We plan to add warning plans and warning levels and more safety functions.
Improvement of the containers
The containers of infinitybatch are very simple constructions at the moment. In the future we plan to add sophisticated storage strategies and container-related functions too.
Counter of learnable parameters
We plan to add sophisticated counter function to make a summary about the characteristics of learnable parameters of a model. We plan to show a detailed overview across the whole model including the number of elements and their aspects to memory and speed as well. This feature is far away from a level where pure Python could be enough. Memory usage monitor
To be able to have a better overview of what happens in the memory we have to dig much deeper therefore we plan to make a detailed memory usage monitor. To develop this we have to leave the level of Python but we plan to build something that is usable in the pure Python level as well.
Improving memory usage
If we have a better overview of what happens in the memory why not to improve the usage of the memory. At least the precise and up-to-date calculation of active and inactive memory blocks would be very welcome and the lifecycle of temporary variables could be also examined.
Improving UI
At the moment our user interface is far away from perfect but at least we have a verbose property to decide about the appearance of very simple prints during the training. In the future we plan to have more configurable training prints. We plan to offer saving stats into file and we plan to create some functionality to be able to connect with graphical interfaces.
Change of model
We plan to add observer to the model, optimizer and criterion properties of infinitybatch to be able to monitor important changes of these attributes without the need to implement a wrapper of the PyTorch method. This ways the use of infinitybatch would be much more convenient.
“In case if needed” plans
The improvements below are a question of need. Because of different reasons we don’t consider those ones that much important right now but we are open and curious about the real-world needs of the users.
Callbacks
Based on the first experiences we plan to add the ability to place callbacks in the worklfow of infinitybatch. We think the ability of calling forward-backward stages separately should be enough to build very different train loops but there could be draw up some real needs.
Improvement of tools.CudaHistory
Classes tools.CudaHistory and tools.CudaMemorySnapshot began their lives like experimental classes. The importance of the management of snapshots like memory state at a given moment or anything else is obvious therefore we plan improve history based containers.
Complexity
We plan to add the ability of using more models, criterions or optimizers together. This leads to much more complex epochs and functionality. Though it would be nice to have that level of functionality yet tomorrow it seems it’s not that easy. To give all the needed energy for this improvement we need to have a better view to the real-world use-cases of our users.



Log in or sign up for Devpost to join the conversation.