-
-
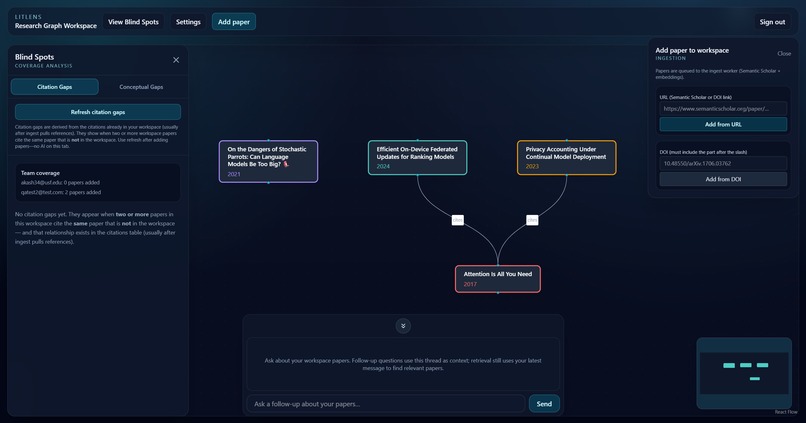
All features with RAG, citation and concept gap detection, add papers, visualize citations and missing papers
-
LitLens Login/Auth page
-
Adding collaborators



Inspiration
Research keeps piling up faster than anyone can read it. One week it’s a few PDFs, and the next it’s 40 tabs open, your laptop fan screaming, and no one on the team is fully sure what’s already covered. We kept running into the same problem: losing track of which papers connect to each other, what each teammate had actually read, and which “must-cite” papers were showing up everywhere but still missing from our own list. So we built LitLens to feel less like a folder of documents and more like a shared map of the field, one that helps us spot missing papers early, before we start writing or running experiments.
What it does
LitLens turns paper URLs and DOIs into a team citation graph, then runs a multi-agent pipeline to find what your review is missing.
You get:
- Semantic Scholar ingestion agent: resolves DOI/URL, pulls metadata, references, and citation links
- Orchestrator agent: coordinates ingestion, graph updates, blind-spot detection, and query flow
- Gap detection agent: finds
- Citation gaps: outside papers cited by multiple papers in your workspace
- Conceptual gaps: under-covered clusters from embeddings + clustering + Gemini topic labels
- Research/RAG agent: answers questions over your workspace only, keeps conversation context for follow-ups, and cites relevant papers
- Shared workspace model: invite-based team spaces so each group has its own graph and history
- Live collaboration layer: real-time presence and shared graph state for parallel review sessions
How We Built It
We built LitLens as a workflow tool for research teams, not just a paper viewer.
The goal was simple: make it easy to ingest papers, see citation structure, detect coverage gaps, and discuss findings in one shared workspace.
Stack Choices
| Layer | What We Used | Why |
|---|---|---|
| Frontend | React, Vite, React Flow, Tailwind | Fast UI development and a graph interface that makes citation relationships readable |
| Collaboration | Yjs | Real-time shared state so teammates can work in the same graph live |
| Backend | FastAPI, SQLAlchemy | Clean API surface and maintainable data access for ingest, graph, gaps, and chat routes |
| Auth | JWT + refresh token rotation | Smooth session handling in the frontend with safer long-lived auth behavior |
| Data | PostgreSQL + pgvector | Stores both structured graph/workspace data and embedding vectors in one place |
| Background Jobs | Redis + arq workers | Moves heavy ingest/gap work off request threads so the app stays responsive |
| Graph Analysis | Embeddings + K-means + density-based grouping | Creates readable topic clusters and identifies under-covered conceptual areas |
| Infra | Docker on EC2, Caddy, Vercel, CI/CD on push | Reproducible deploys, HTTPS termination, simple singe page hosting, and automated delivery |
End-to-End Flow
- User logs in and submits a DOI or URL.
- Ingestion job fetches metadata and citation links, then writes papers and edges to the workspace graph.
- Embeddings are generated and stored for similarity search.
- Clustering organizes papers into topical neighborhoods for visualization.
- Gap detection runs:
- Citation gaps: papers your team has not added yet, even though several papers in your workspace keep citing them. These are likely “core” papers you should read to avoid missing foundational context.
- Conceptual gaps: research themes that show up around your papers but are still under-covered in your own collection. This helps you spot weak areas in your review before writing or running experiments.
- Chat retrieval searches workspace vectors, pulls relevant passages, and answers using those passages plus recent conversation context.
In Short
Paste papers -> map the network -> detect what is missing -> ask grounded questions in context.
Challenges we ran into
- Shared demo workspace problem: Early versions dropped everyone into one workspace UUID. We fixed this by creating per-user primary workspaces and removing legacy demo-workspace assumptions from routing and membership logic.
- Conceptual gaps disappearing after adding a citation-gap paper: Our conceptual pipeline initially focused on external cited papers. Once users added those papers, the external candidate pool shrank and results looked “empty.” We added a workspace-only fallback path and clearer UI copy so this behavior is expected, not confusing.
- RAG follow-up failures: We saw null responses, oversized history payloads, and 422 errors. We hardened validation, trimmed chat history on the client, increased timeouts, and surfaced actionable error messages in the UI.
- Environment drift across services: Keeping API, worker, and frontend env vars synchronized across local and EC2 (especially invite-link origin settings) was a recurring operational issue.
Accomplishments that we're proud of
- Built a full path from paper URL/DOI → citation graph → blind spots → grounded chat in a deployable stack.
- Shipped two distinct blind-spot modes (citation and conceptual) with behavior and UX tailored to each mode.
- Implemented real multi-user collaboration with invite-based workspaces, instead of a single shared demo room.
- Kept the codebase extension-friendly by separating routers, workers, and agent logic.
What we learned
- RAG is a systems problem, not just a model call: retrieval query quality, history size, and grounding constraints matter as much as model choice.
- Terminology drives trust: users interpret “gap” differently for citation structure vs embedding coverage, so labels and explanations must match actual behavior.
- Multi-service delivery needs proper checklists: migrations, Redis, worker image versions, CORS, and invite base URLs must stay aligned.
What's next for LitLens
- Enforce workspace membership checks server-side on every workspace-scoped route (graph, gaps, ingest, and chat).
- Improve retrieval for vague follow-ups with query expansion and/or multi-query retrieval.
- Add export workflows (BibTeX and citation lists) from graph views and blind-spot queues.
- Add lightweight evals for blind-spot usefulness and RAG faithfulness in research workflows.
Built With
- amazon-web-services
- arq
- aws-ec2
- aws-rds
- aws-ses
- axios
- bcrypt
- caddy
- docker
- docker-compose
- fastapi
- framer-motion
- github-actions
- google-adk
- google-gemini
- hdbscan
- jwt
- lucide-react
- numpy
- pgvector
- postgresql
- python
- react
- react-flow-(@xyflow/react)
- redis
- scikit-learn
- semanticscholarapi
- sqlalchemy
- tailwind-css
- typescript
- uvicorn
- vercel
- vite
- yjs
- ypy-websocket



Log in or sign up for Devpost to join the conversation.