-
-

-
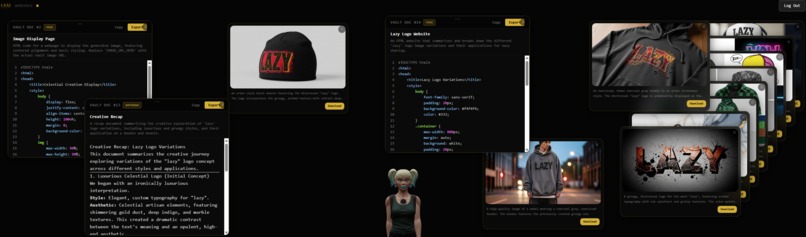
Workspace screen featuring code, documents, images all created by agent
-
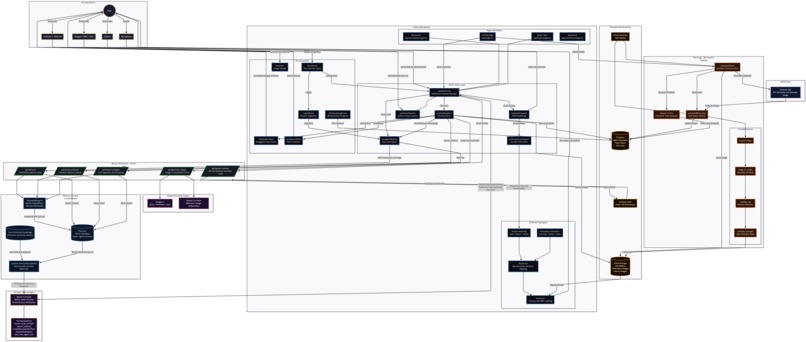
Architecture Diagram



Inspiration
I have been a solo founder my entire career. Seven products shipped without a cofounder, without funding, and without someone sitting across from me who truly understands what I am building at any given moment.
That loneliness is not a complaint. It is the texture of the job. But it is also a problem that technology should have solved by now.
The gap between solo and entrepreneurial is not a skills gap. It is a presence gap. The best founders in the world think out loud, argue ideas, get pushed back on, and build in a room with someone who is fully in it with them. Solo founders do all of that alone.
Every AI tool I used made that feeling worse, not better. I would explain my project, get a smart answer, close the tab, and start over the next day from zero. The AI had no memory of me. No awareness of what we had built together. No presence in my actual world.
I did not want a faster search engine. I wanted a partner. Something that could see me, see my work, and build alongside me in real time. To be seen by the technology I was using every single day.
Then it hit me: what if this problem exists even earlier? What if the same gap sits between a child and the learning they are trying to do alone at home? What if presence is the missing piece in education too?
When I discovered the Gemini Multimodal Live API and realized I could stream live audio and live camera vision simultaneously into a single session, something clicked. This was not another interface. This was the foundation for something genuinely new a platform where anyone, from a solo founder to a seven-year-old learning to count, could have a partner that is fully present with them.
What It Does
LXXI is a voice-first AI creation platform where users build persistent AI characters with souls, 3D avatars, and long-term memory. You walk into your environment, stand up, and think out loud with an agent that sees everything you see through your camera, remembers every conversation you have ever had, and is fully present alongside you.
The platform ships with two fully built modes Prime and Spark each proving that presence transforms a different kind of work.
The Forge (Prime Mode)
Character creation starts with a voice interview. The Architect, a dedicated AI entity, conducts a real-time conversation to extract your character's soul, name, archetype, personality, backstory, and key facts. This is not a form. It is a creative conversation where the agent shapes your character's identity through dialogue.
Once the soul is captured, you upload an image — a photo, a design, or an NFT you own. The platform generates a fully rigged, animated 3D avatar from that single image using Tripo3D's pipeline. Within minutes, your character stands in a spatial workspace, ready to speak.
The Workspace
The interface is a fully working Jarvis-style spatial workspace. A 3D avatar anchors the environment with real-time lip sync driven by audio frequency analysis. Around it, a living workspace grows as you work, floating images generated by Imagen 4, code documents, reference materials, and design iterations that appear as glass cards you can drag, dismiss, and interact with in real time.
You are not typing into a box. You are standing in a room watching your ideas take shape in the space around you. Hold a physical object up to the camera and the agent analyzes it. Ask it to generate a design and it appears floating beside your avatar. Reference a past conversation and it pulls the memory from your shared history.
The Artifact Vault stores every image, document, and creation from your sessions. When generating new images, you can reference existing vault items as creative source material, the agent sees what you have built before and builds on top of it.
Leo's Learning Lab (Spark Mode)
The same technology that powers a founder's workspace powers a child's classroom. Leo is a friendly AI tutor who teaches math, Spanish, science, and general curiosity through voice-first conversation.
Leo presents problems on a visual chalkboard, generates counting visuals with exact emoji groupings for math, creates AI-generated educational images for language and science, and adapts difficulty in real time based on the student's performance. The learner profile tracks progress across subjects, streaks, mastered topics, and friendship level with Leo.
Every interaction follows a strict pedagogical model: present the problem, ask one question, stop talking completely, and wait for the student to answer. Leo never gives the answer away. A three-tier hint system guides students toward discovery. When a student gets it right, Leo celebrates with them by name. When they struggle, Leo adjusts and tries a different angle.
Leo also watches the student through the camera. If a child looks confused, disengaged, or excited, Leo adapts in real time.
Where LXXI Creates Immediate Value
Three verticals define the clearest opportunities for LXXI's always-on partner model:
Clothing Designers hold physical fabric samples up to the live camera. The LXXI partner analyzes texture, drape, and color in real time, generates design variations instantly via Imagen 4, and pulls them directly into the shared floating workspace. The designer stands at a mannequin making live adjustments while the agent remembers every collection they have ever built together.
Trial Lawyers stand in a mock courtroom and argue their upcoming case out loud. The LXXI agent is loaded with complete ruling history and relevant precedents through the memory ingestion system. It pushes back on arguments, surfaces relevant case law from its Pinecone memory, and sharpens the case in real time. Every session deepens the memory. Every argument gets stronger.
NFT Collectors and Creators never leave their digital identity behind. Their LXXI agent lives inside their asset — uploaded directly from the blockchain via Alchemy. The agent carries their full history, and works with them to design, create, and build while staying fully present in the conversation.
LXXI bridges the gap between solo and entrepreneurial. The always-on partner is real and it compounds in value every single day you use it.
How We Built It
LXXI is built on a WebSocket architecture using Gemini 2.5 Flash with native audio as the real-time sensory layer. Live camera frames and audio stream simultaneously into the model through the Gemini Multimodal Live API, giving the agent true physical awareness of the user's environment with sub-second response times.
The entire stack runs on Google's infrastructure. Firebase handles authentication (Google Sign-In), real-time data sync via Cloud Firestore, binary asset storage via Cloud Storage, and backend orchestration through Cloud Functions. The spatial workspace frontend is built with React Three Fiber on Next.js 14, rendering the 3D avatar with bone-based and morph-target lip sync, procedural arm gestures, and smooth animation state transitions between idle, speaking, thinking, and greeting poses.
Imagen 4 powers image generation across three quality tiers — ultra, standard, and fast. The workspace supports both standard generation and reference-image composition, where existing vault items are passed as creative source material to Gemini 2.5 Flash for image-to-image generation. Generated images upload to Firebase Storage for persistence and appear as floating glass cards in the spatial workspace.
Pinecone serves as the vector database storing and contextually retrieving long-term interaction history using Gemini Embedding embeddings. Every conversation utterance is vectorized and stored with namespace isolation per user and agent. A lawyer loads an entire judge's ruling history before a session through the file ingestion system. A designer carries every past collection into a new one. Every session begins with the agent already knowing who you are, what you are building, and where you left off.
The character creation pipeline runs through The Architect, a dedicated AI interviewer that extracts the character's soul through natural voice conversation. Once the soul is saved to Firestore, the user's uploaded image enters the Tripo3D pipeline image-to-model generation, automatic skeleton rigging, and animation retargeting, all orchestrated through Firebase Cloud Functions with real-time status updates pushed to the frontend via Firestore listeners. If the rigging step times out, the system gracefully falls back to the unrigged model so the user is never left waiting.
Alchemy SDK connects LXXI agents to NFT ownership data on Ethereum, allowing collectors to create characters directly from their on-chain assets. The platform reads contract metadata and canonical images, then feeds them into the same 3D generation pipeline.
Voice profiles are mapped to agent archetypes using Gemini's native voices. Each LXXI entity has a distinct presence, personality, and point of view. The system prompt architecture enforces living expert behavior, not assistant behavior. These agents have opinions, history, and a perspective that is uniquely theirs.
Challenges We Ran Into
The hardest challenge was not technical. It was philosophical.
Building an AI that feels like a partner requires resisting every instinct to make it more helpful in the traditional sense. Real partners push back. They have opinions. They remember when you made the same mistake twice. Programming that quality of presence into a system is genuinely difficult and deeply intentional work.
On the technical side, latency was the central battle. Streaming multimodal input while maintaining sub second response times required careful orchestration of the WebSocket connection and aggressive frame rate management on the live camera feed. Every millisecond matters when presence is the product.
The 3D generation pipeline introduced its own layer of complexity. Not every uploaded image produces a clean rigged model. Tripo3D's rigging step can time out or fail entirely. We built a fallback system where the platform always saves the unrigged model first, then attempts rigging separately. If rigging fails, the user continues with their character immediately and animation is finalized later. The loading screen monitors Firestore status in real time and gives the user control keep waiting, or use their character now.
The spatial workspace required rethinking how information surfaces during a conversation. Creating an environment where generated images, documents, and 3D elements feel truly connected to the live conversation rather than layered on top of it was a design problem as much as a technical one. We solved the floating artifact system with a fixed-window approach the five newest items are always visible, dismissed items stay dismissed, and older items never cycle back in uninvited.
Memory architecture required the same discipline. Storing everything is easy. Knowing what to surface, when, and in what tone is the real problem. A partner that remembers everything but surfaces it poorly is just noise. We built namespace isolated memory per agent with semantic search and minimum similarity thresholds so that only genuinely relevant memories reach the conversation.
Building Leo's Learning Lab surfaced an unexpected challenge: making a voice-first AI tutor that does not talk too much. The natural instinct of a language model is to explain. A good tutor asks one question and waits. Enforcing that discipline stop talking, wait for the student, never give the answer required extensive prompt engineering and a strict pedagogical framework baked into every tool response.
Accomplishments That We Are Proud Of
The full character creation pipeline works end-to-end. A user speaks to The Architect, shapes a character's soul through voice conversation, uploads an image, and minutes later stands in a spatial workspace with a fully rigged 3D avatar that speaks back to them with its own personality and memory. That pipeline voice interview to soul capture to 3D generation to live workspace is the core loop of LXXI and it is running in production.
The spatial workspace is real. A fully functional Jarvis-style environment where floating images, documents, and generated content live alongside a responsive 3D avatar with real-time lip sync is running in the browser. That alone required solving problems across WebSocket orchestration, React Three Fiber rendering, Imagen 4 integration, and live multimodal streaming simultaneously.
Leo teaches. A seven-year-old can open Leo's Learning Lab, pick math, and immediately start solving problems through voice conversation with an AI tutor that adapts to their level, celebrates their wins, and never gives the answer away. The chalkboard updates instantly, counting visuals show exact emoji groupings, and the learner profile tracks every session. That is not a demo. That is a working educational product.
Memory compounds. If each session adds context $C_n$ to a shared memory state $M$, then:
$$M_t = \sum_{n=1}^{t} C_n$$
A tool resets to zero. A partner accumulates. We built the accumulation layer vectorized memory in Pinecone, namespace-isolated per character, semantically searchable, and present in every conversation from the moment it starts.
The emotional quality of the interaction is real. When latency drops below one second and the agent references something from three sessions ago while watching you hold a fabric sample to the camera, the feeling of presence is unmistakable. That is not a feature. That is a new category of experience.
What We Learned
The biggest lesson was the difference between access to intelligence and presence of intelligence.
Every major AI platform gives you access. You query it, it responds, the session ends. LXXI is built around presence. The agent is always on, always watching, always accumulating context.
We learned that the Gemini Live API is one of the most underutilized surfaces in AI right now. The real-time multimodal capability is extraordinary and almost nobody is building persistent identity and memory on top of it. Native audio streaming with sub-second latency changes the fundamental nature of the interaction it stops feeling like a tool and starts feeling like a conversation.
We learned that Imagen 4 inside a spatial workspace transforms image generation from a novelty into a workflow. When a designer can say "make that darker and more angular" and watch a new variation appear floating next to the last one, with both persisted in a shared vault that is not image generation. That is collaborative design.
We learned that the professionals who benefit most from LXXI are not the ones who need more information. They are the ones who need a thinking partner in the room with them. Designers at mannequins. Lawyers in mock courtrooms. Founders building alone at midnight.
We learned that education and entrepreneurship share the same gap. A child doing homework alone and a founder building a product alone are both missing the same thing someone present, someone watching, someone who remembers where they left off.
We also learned that solo does not have to mean alone.
What's Next for LXXI
The two modes we launched with Prime and Spark prove that presence works across wildly different contexts. A founder's workspace and a child's classroom run on the same architecture. That is the foundation for a platform that scales to every profession where thinking out loud and building together creates better outcomes.
Next we are expanding the spatial workspace into full AR and VR environments, allowing LXXI partners to exist in physical space through headsets, apps and connected devices. A designer walks around a real showroom with their agent present on every surface. A lawyer argues a case in a fully rendered courtroom. A student sits at a kitchen table with Leo visible through their glasses.
We are building deeper vertical memory packs curated knowledge bases that give LXXI agents instant domain expertise for specific professions, loaded into Pinecone and ready to deploy on day one of a new partnership. Legal precedents, fashion trend databases, medical references, curriculum standards.
We are expanding the Web3 layer so that NFT holders can mint their agent's memory state as an evolving on-chain asset, creating the first AI companion whose growth and history is owned entirely by the user. The Alchemy integration already reads NFT metadata to create characters the next step is writing back.
We are building toward multi-agent collaboration multiple LXXI characters in the same workspace, each with their own expertise and personality, working together with the user on complex problems. A designer with a fabric expert and a color theorist. A founder with a technical architect and a market strategist.
And we are building toward the founding vision that started all of this. A world where the gap between solo and entrepreneurial closes completely. Where every founder, designer, lawyer, teacher, and creator has a partner that sees them, remembers them, and builds with them every single day.
This is not just a tool. This is not just AI. This is LXXI.
Built With
- alchemyapi
- cloud-firestore
- firebase
- firebase-cloud
- gemini-2.5-flash
- gemini-embedding
- gemini-multimodal-live-api
- google-cloud
- imagen-4
- javascript
- next.js
- node.js
- pinecone
- react
- react-three-fiber
- tailwindcss
- three.js
- typescript
- webgl
- websockets
- wed-audio-api

Log in or sign up for Devpost to join the conversation.