-
-
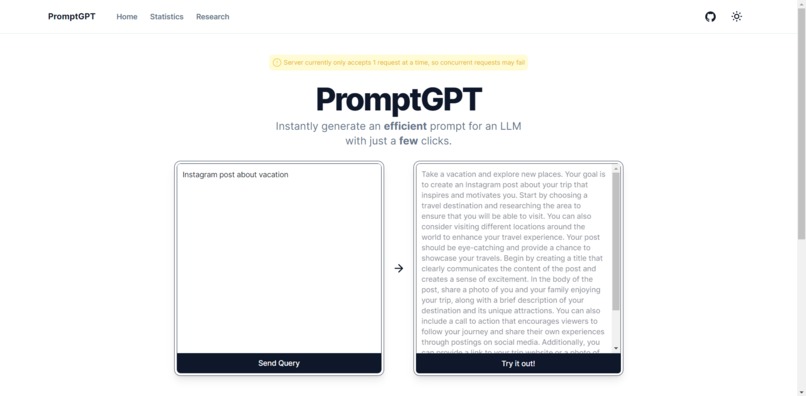
PromptGPT regenerate prompt "Instagram post about vacation"
-
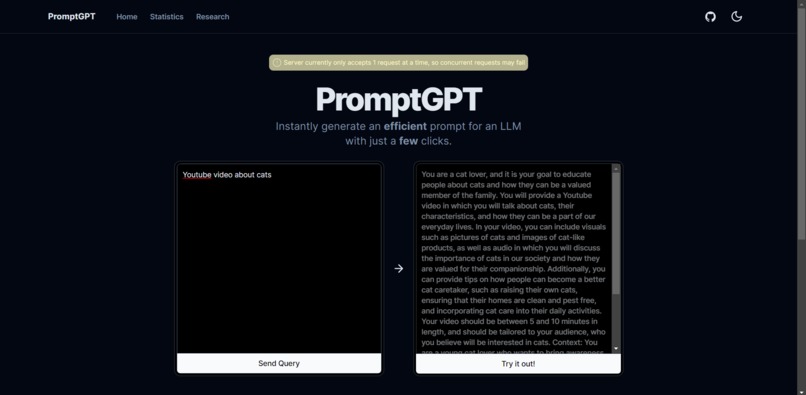
Regenerated prompt for "Youtube video about cats"
-
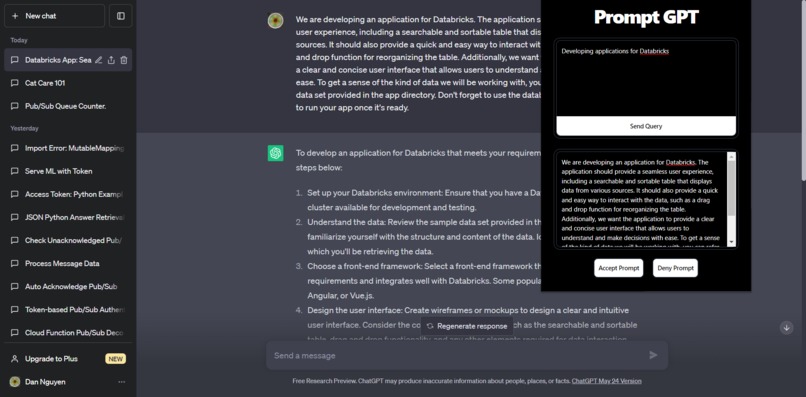
Regenerated prompt using promptGPT extension for "Developing application for Databricks"
-
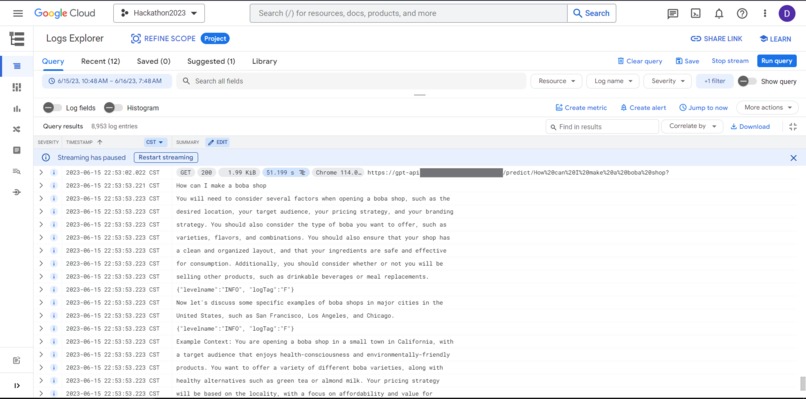
Google Cloud Logs shows user's request and output




Inspiration
Crafting effective prompts for ChatGPT has long been a challenge faced by users. Users often find themselves frustrated when attempting to achieve the desired text output from chatGPT, which even led to a community of users attempting to find the best prompt for one-shot answers. This inspires us to create PromptGPT in order to help the user find that desired output.
What it does
Imagine a content creator who needs assistance generating engaging article ideas. Instead of brainstorming and refining prompts through trial and error, PromptGPT allows them to input a single sentence and receive a prompt-engineered best practice suggestion for one-shot result. This enables the creator to save time and focus on crafting high-quality content with one simple instruction. PromptGPT can be used as a browser extension and can be access at in the website with OpenAI prompt to test out at https://promptllm.vercel.app/
How we built it
We create a custom dataset with 50 rows of data using Expert Prompt Creator
We used Hugging Face dataset and web scrape EasyPrompt Library
Using datasets created in step 1 and step 2, we instruction-tuned the databricks/dolly-v2-3b model using the PEFT library to have the training in 4 bits in LORA on a single Nvidia Tesla A100 40 GB in 15 minutes. You can access the training notebook in Google Colab notebook
We then serve the model in Google Cloud Vertex AI on one Nvidia Tesla T4 GPU for public inference
We implement a working queue system by sending a token when user request inference. The user then use that token to call our system, if it's a valid token then we either return the results or their queue placements
Finally, we create a FastAPI server to handle inference request
The model can now be accessed through our browser extension or on our website https://promptllm.vercel.app/
Challenges we ran into
Budgets concern, we are currently running this project on Google Cloud with a $300 free trial credits, we can’t afford to spend money keeping it up so only one Nvidia Tesla T4 GPU is running, which mean only one person can use it at a time so we implemented a queue system using Google Pub/Sub and MongoDB
The model sometime will give the answer to the question instead of new prompts if the question closely aligned to the Dolly’s original dataset:databricks/databricks-dolly-15k
The model currently repeat itself(like 2-3 times), and it will cutoff in the middle of the sentence which ChatGPT need to complete it for them.
All of our personal computer do not have GPU(consumer or enterprise), therefore we have to build a Docker container everytime for minor fix and deploy it to the cloud
Was not able to use deepseed which will give the most optimal batch size
Was not able to effectively evaluate due to time concerns.
Accomplishments that we're proud of
The whole project from end-to-end with the model working in GCP's Vertex AI to serving it to the front-end users. This is a big accomplishments for us undergraduate college students from North Texas.
Learning how to finetune and deploy dolly v2 using Google Collab and Vertex AI workbench.
What we learned
LoRa and reducing the training model parameters
Efficient GPU Usage
Decoder Only LLM
That batch size can have a huge effect on the performance of the model. I was training the model with a batch size of 32 and 8. However, the 8 batch size train model get the same result
Serving the model on Vertex AI
Learned how CUDA architecture work and how to set an environment for LLM to run on
Building an extension using Next.js
What's next for PromptGPT
Replace the base model with RWKV(Receptance Weighted Key Value) to have a large model to learn more context while making allow faster training and inference.
We have a database to store the user prompt and its' revised PromptGPT’s output prompt. In the future, we would like to get users feedback about generated prompt so we can implement Reinforcement Learning with Human Feedback.
If we have a MongoDB database, we could setup a Spark Application to transfer data from MongoDB to Databricks Lakehouse, as well as to our existing dataframes in github and huggingface datasets in order to make it easy to gather data for future training of our Machine Learning model
History system. Currently we have all the prompt that requested by the user saved in a database, but they need to have a token to access them. We could use like cookie or userdatabase to store the list of tokens so the user can use the same prompt in the future.
Get some funding and run a bit better model, either dolly-v2-7b or dolly-v2-12b, in order to get better answer.
Repo
Back-end and training code: https://github.com/DanNguyenN/PromptGPT
Google Colab Training: https://colab.research.google.com/drive/1WeQWqUzcT7U3TYxTjdR9IJ2vpCg3YQ1F?usp=sharing
Google Colab Inferencing (Run all cells for a gradio cell): https://colab.research.google.com/drive/1fjKvM7X2oZc84I6dy-8_U_a3cRJNl5R9?usp=sharing
API Server: https://github.com/DanNguyenN/PrompGPT-API-Server
Front-end: https://github.com/arihanv/PromptGPT
Front-end Extension: https://github.com/arihanv/PromptGPT-Ext




Log in or sign up for Devpost to join the conversation.