-

Dashboard page
-
Recording page on landing
-
Recording page with generated prompt
-
Reports page
-
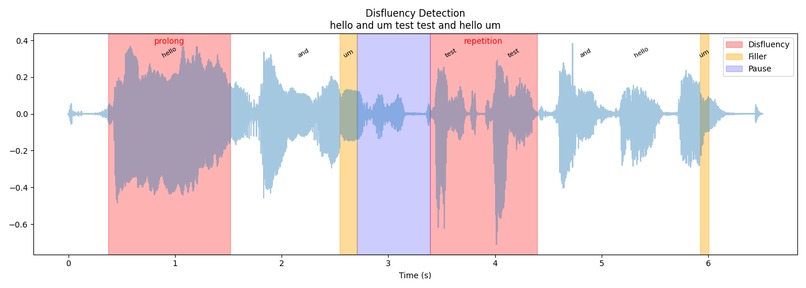
Example output of disfluency model
-
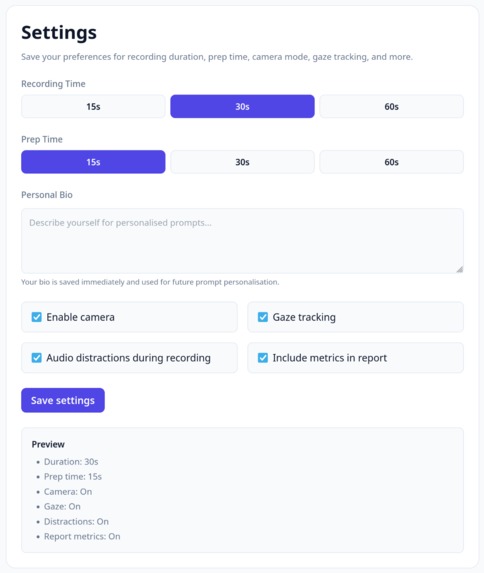
Settings page
-
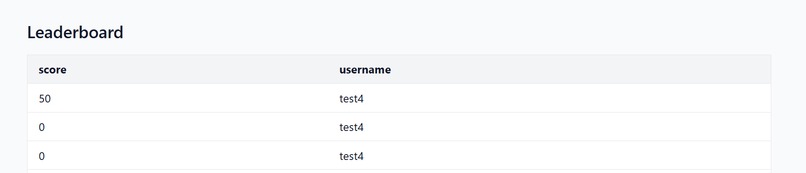
Leaderboard page
-
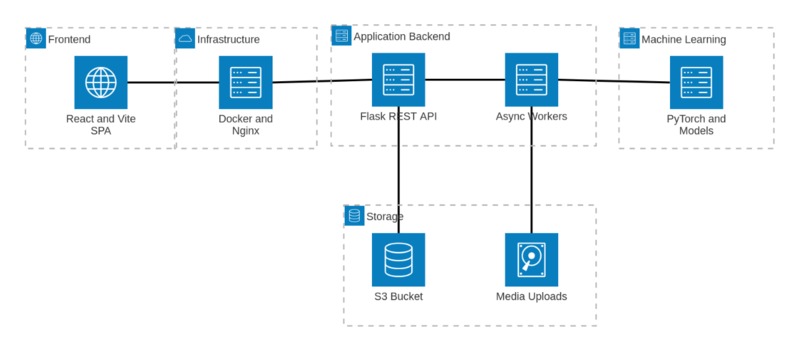
Data flow diagram for Rhetorix
-
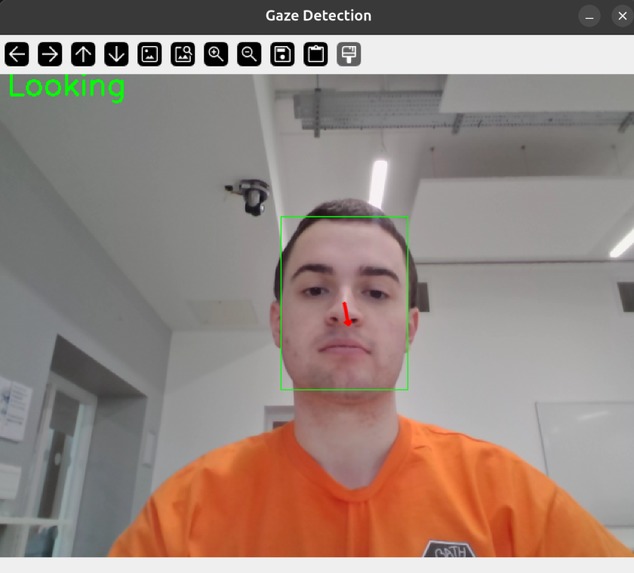
Gaze Tracking Example 1
-
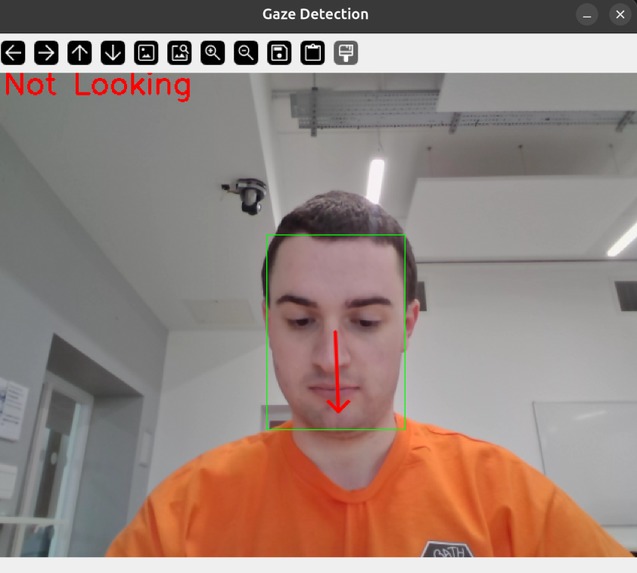
Gaze Tracking Example 2
-
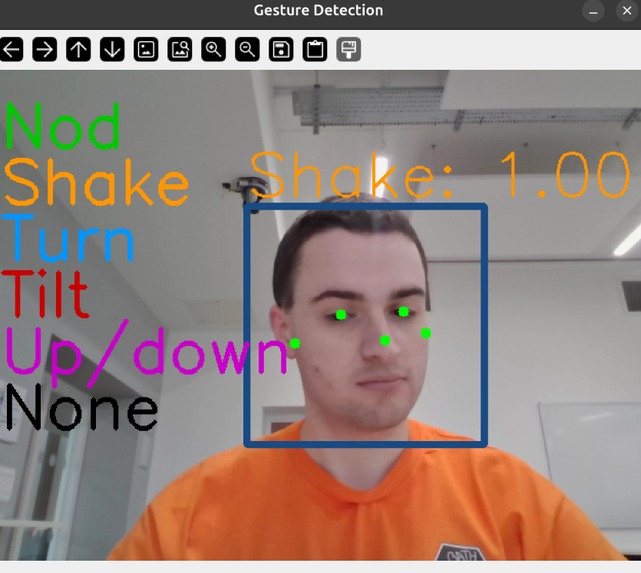
Gesture Tracking Example











Inspiration
Recently, there has been a massive trend online of people challenging themselves to speak for 60 seconds straight without using a single filler word or breaking their train of thought. While it is a brilliant exercise, the setup is tedious—you have to record yourself, manually time it, and painstakingly watch it back to count your mistakes. We wanted to eliminate that friction. Rhetorix was born out of the desire to make this exercise instantly accessible and highly quantifiable, providing a rigorous, easy-to-use tool that tests your focus without any of the setup hassle 😇.
What it does
Rhetorix is an AI-driven public speaking coach designed to simulate high-pressure environments. With minimal setup, users are dropped directly into a "pressure drill". The application provides a random prompt and actively tries to break the user's focus by triggering random audio distractions.
As the user speaks, our integrated machine learning backend works in real-time. It automatically transcribes the audio, scores the speaking pace (Words Per Minute), counts filler words, and tracks the user's eye contact with the camera. The moment the time is up, Rhetorix delivers instant, actionable feedback via a custom multimodal timeline, allowing users to see exactly where their focus slipped or their pace faltered.
How we built it
We engineered Rhetorix as a modern full-stack application, separating concerns between a lightning-fast frontend and a heavy-duty, threaded machine learning backend.
⚡ The Frontend Interface: Built using React 18 and TypeScript, bundled with Vite for maximum performance. We used Tailwind CSS and Lucide Icons to design a clean, distraction-free UI. To handle the live video feed, we integrated react-webcam, and for the complex data visualisation at the end of the session, we heavily customised Recharts.
🏭 The Backend Architecture: We deployed a Flask REST API running via Gunicorn and Werkzeug. Data persistence and user authentication are handled by a lightweight SQLite database managed through SQLAlchemy. We heavily utilised Python threading to manage background processing workers, ensuring the UI remains unblocked while media files are uploaded and analysed.
🧠 The Machine Learning Pipeline: This is the core engine of Rhetorix. Instead of relying solely on generic LLM APIs, we implemented a custom multimodal AI stack. We use PyTorch and Hugging Face Transformers for core inference. Audio processing and sample-rate conversion are handled by librosa and soxr, passing data to WhisperX for lightning-fast speech transcription and pyannote for voice analytics.
👁️ Computer Vision: For gaze tracking, we integrated custom face-detection dependencies and a bespoke UNet architecture alongside OpenCV to track eye contact mathematically, rather than just estimating it.
🚀 Deployment: The entire application is containerised using Docker and Docker Compose, with an Nginx reverse proxy routing traffic on our hosting environment.
Challenges we ran into
Building a multimodal analytics tool in a constrained timeframe presented several major hurdles:
🥊 Infrastructure Wrestling: Setting up our Docker environments and getting the containers to communicate perfectly on an AWS EC2 instance proved to be a significant DevOps challenge, especially when handling media chunk uploads.
🤖 Running Custom AI Locally: Integrating and running bespoke computer vision models - specifically our mathematically rigorous gaze-tracking AI - was incredibly complex. Unlike pinging an external LLM API, we had to manage ONNX runtimes, PyTorch dependencies, and local model checkpoints directly within our backend environment.
📈 Synthesising the Output: We collected a massive amount of dense data (audio transcriptions, temporal WPM fluctuations, binary gaze arrays). Translating this raw mathematical output into a meaningful, intuitive user experience was tough. We ultimately solved this by engineering a custom, colour-coded multimodal timeline chart that overlays all metrics onto a single visual axis.
Accomplishments
Delivering a Functional MVP: We successfully built and integrated a highly complex full-stack architecture before the deadline.
Implementing State-of-the-Art ML: We didn't just build a wrapper; we successfully deployed cutting-edge, local machine learning and computer vision models to solve a real-world problem.
Team Synergy: We came together as a team of complete strangers who had never met before this event. Figuring out how to communicate, merge code, and trust each other's expertise was incredibly rewarding 🙌.
What we learned
The Power of Delegation: We quickly realised that sticking strictly to our designated roles (frontend, backend, ML, DevOps) was absolutely essential. Trusting each other to execute our specific parts of the architecture was the only way to complete the task in time.
Insights into the AI Landscape: Implementing these models required us to dive deep into the latest machine learning research papers. Parsing the underlying structural and mathematical logic of these state-of-the-art models gave us a profound understanding of the current shifts happening in this field 🔎.
What's next for Rhetorix
We see massive potential for Rhetorix to evolve from a hackathon MVP into a comprehensive training platform:
👋 Advanced Analytics: Integrating spatial mapping to track hand gesturing and body language alongside voice and gaze.
📣 Actionable Coaching: Evolving the results dashboard to not just display data, but to provide concrete, AI-generated suggestions for improvement based on the multimodal output.
💸 Commercialisation: Turning Rhetorix into a fully-fledged SaaS product. This includes introducing subscription tiers, premium options for human expert review, and gamifying the pressure drill with leaderboards and streaks to build long-term practice habits.
Built With
- amazon-ec2
- amazon-web-services
- docker
- flask
- flask-cors
- gunicorn
- html
- lucide-react
- numpy
- openai
- opencv
- pandas
- postcss
- python
- pytorch
- react
- react-webcam
- s3
- scikit-learn
- scipy
- sql
- sqlalchemy
- sqlite
- tailwind
- typescript
- vite
- werkzeug




Log in or sign up for Devpost to join the conversation.