-
-

VARA AI
-
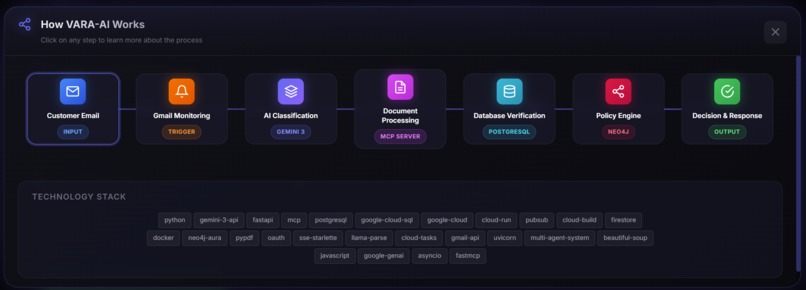
How vara ai works
-
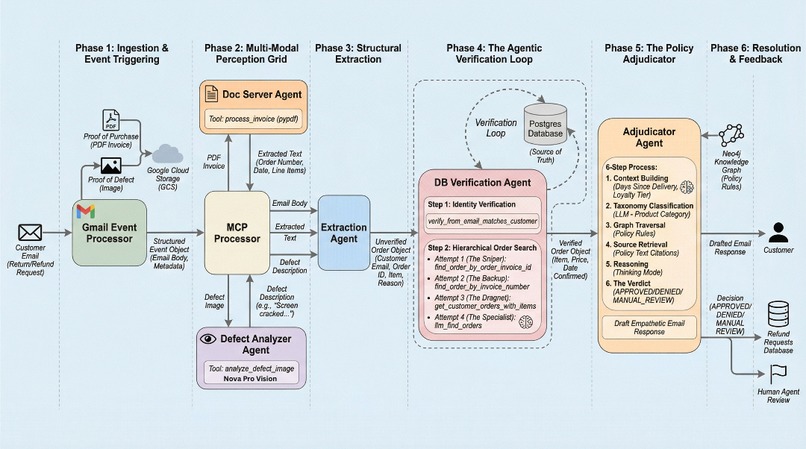
End-to-End Refund Workflow
-
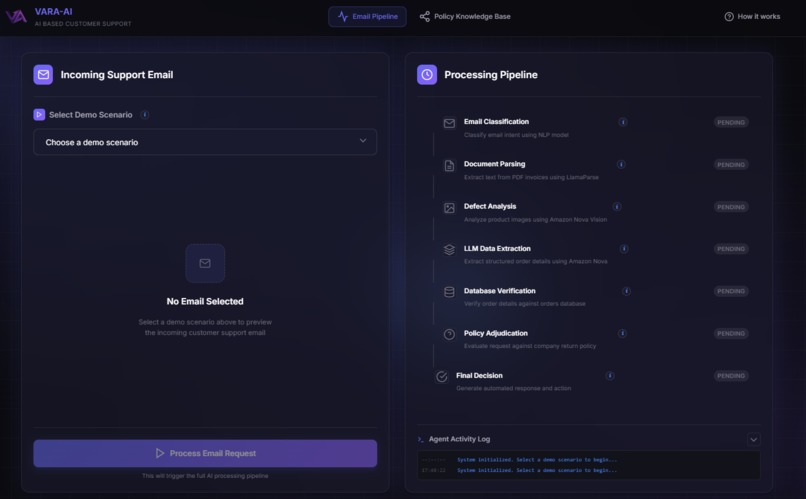
Email Pipeline Dashboard (Desktop View)
-
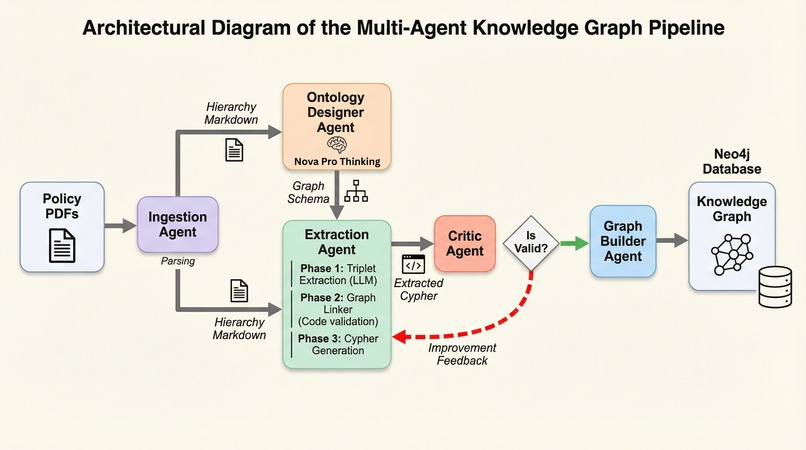
Multi Agent Knowledge Base Pipeline
-
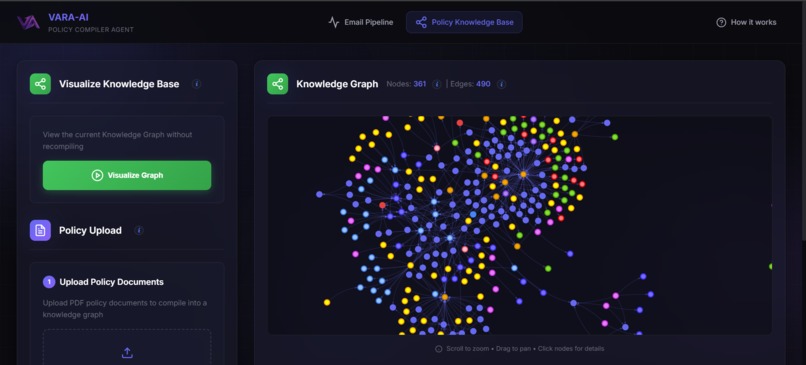
Policy Knowledge Base (Neo4J Graph Database)
-
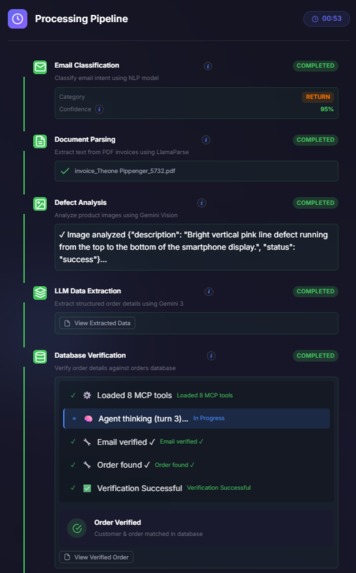
VARA AI Working Pipeline
-
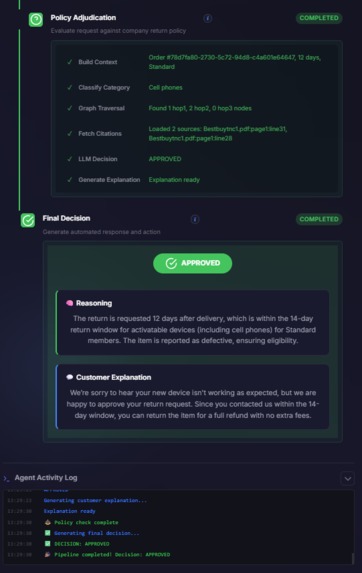
Final Decision








Inspiration
Refunds are one of those moments where trust either gets cemented—or quietly dies.
It usually starts small: a damaged item, a missing part, the wrong SKU. The customer doesn’t wake up wanting a fight; they just want it made right. But the second they hit “Contact Support,” time starts stretching. They attach the invoice, maybe a couple of photos, explain the issue… and then they wait. And wait. Somewhere on the other side, an agent is juggling dozens of tickets, trying to interpret blurry images, open PDFs that don’t parse cleanly, cross-check order records, and translate a policy document into a decision that won’t get them in trouble later.
The customer feels ignored. The company feels attacked. And the most frustrating part is that neither side is being unreasonable—the process is.
This isn’t a corner case either. Returns are massive and messy at scale: U.S. retailers estimate that 15.8% of annual sales will be returned in 2025 — roughly $849.9B (NRF). . And the pressure isn’t only operational—return fraud is ~9% of all returns, costing about $76.5B annually(Reuters). When the system is slow or inconsistent, everyone loses: customers feel helpless, agents burn out, and brands quietly bleed loyalty. Industry reporting also cites that 71% of consumers are less likely to shop with a retailer again after a poor returns experience (Yahoo Finance).
We built VARA AI because the refund experience shouldn’t be a slow, opaque negotiation. It should feel like: “We received your request, we understand what happened, here’s the decision, here’s why, and here’s what happens next.” Fast enough that customers don’t have to chase—and accountable enough that companies can trust the outcome.
That’s the promise: speed without guesswork, automation without losing trust.
What it does
VARA AI automates the refund customer support workflow from intake to decision. It processes a refund request in approximately 90 seconds and produces an outcome that is grounded in evidence and explainable.
For each refund request, VARA AI:
- Ingests the case from the customer email and attachments (invoice PDFs and defect images).
- Extracts structured information from documents:
- Parses invoice PDFs to capture order and purchase details.
- Analyzes defect/damage images to identify the reported issue and summarize visual evidence.
- Verifies key fields against backend records via a database verification service, including:
-** Customer Email**
- Order Details
- Retrieves relevant policy context using GraphRAG over a structured policy knowledge graph to reduce hallucinations and ensure decisions are tied to the correct rules.
- Generates a decision: Approve / Deny / Manual Review, including the refund action or next step.
- Produces an explanation that references the evidence used (PDF fields, image findings, database verification) and the policy basis for the outcome.
The system reduces manual effort in refund handling while improving consistency, traceability, and turnaround time for customers.
Amazon Nova Features Implemented
Deep Reasoning
Enabled via nova-pro-v1 capabilities. Used in the Ontology, Critic, and Adjudicator agents to support multi-step reasoning before generating schemas or refund decisions.
High Media Resolution (Nova Vision) Configured native image payloads in the Defect Analyzer’s vision requests to capture fine-grained defects (e.g., small scratches, hairline cracks) from customer images using Nova's multimodal engines.
Structured Output & Type-Safety We use strict prompt enforcement to ensure machine-validated JSON outputs align perfectly with our Neo4j and PostgreSQL schemas.
Low-Latency Tool Loops
We run the Database Verification Agent on nova-lite-v1 to power fast, multi-turn verification loops where the model selects and executes MCP tools (order lookups, email matching, candidate resolution) autonomously.
Multimodal Perception & Synthesis We send defect images as binary blocks and merge Amazon Nova’s visual findings with invoice fields and email context into a single evidence bundle for grounded adjudication.
How we built it
We built VARA AI as two connected pipelines: an offline policy compiler that turns messy T&Cs into a traceable Neo4j knowledge graph, and an online adjudication workflow that processes each refund email end-to-end.
Illustration 1 — Policy Knowledge Graph Pipeline (Neo4j)

A multi-agent “policy compiler” converts unstructured T&C PDFs into a validated Neo4j policy graph. Every extracted rule carries source citations (page/location), making downstream refund decisions traceable and defensible.
How it works:
- Policy ingestion → Hierarchial markdown: Policy PDFs are parsed into hierarchical markdown with page markers so every extracted rule can be traced back to an exact source citations (page + location).
- Multi-agent compiler (Ontology → Extraction → Critic → Builder):
- Ontology Agent (Nova Pro) designs the graph schema (node/relationship types + required properties like source_citation).
- Extraction Agent (3 phases): 1) LLM triplet extraction 2) deterministic linking + dedup + type checks 3) Cypher generation.
- Critic Agent validates schema coverage + Cypher quality and can trigger a retry loop for self-correction.
- Builder Agent executes validated Cypher in Neo4j AuraDB and verifies graph integrity.
This gave us a policy store that’s structured, traceable, and defensible—ideal for grounded decisions.
Illustration 2 — End-to-end Refund Workflow (Email → Decision)

Once the policy graph exists, the runtime workflow processes each incoming customer email end-to-end:
- Intake + Trigger: A Gmail Watch triggers the ingestion pipeline; the Email Event Processor fetches new emails, extracts body + attachments, classifies intent, and stores a structured JSON artifact.
- Central orchestration (MCP Client): The core process runs the pipeline as a single execution flow.
- Evidence extraction via MCP tools:
- Invoice PDF parsing (doc_server): PDF attachments are base64-decoded, parsed, saved as text artifacts, and returned for downstream extraction.
- Defect image analysis (defect_analyzer): Images are analyzed using Nova Vision to produce a defect summary with safe fallbacks (“Manual review required”).
- Structured case extraction (LLM → JSON): Email + invoice text + defect summary are combined into a single context and extracted into a strict JSON schema.
- Agentic DB verification loop (Postgres): A dedicated DB Verification MCP server orchestrates multiple tools to converge on a single source-of-truth order record.
- Verify sender email exists → fetch customer profile.
- Resolve order deterministically:
order_invoice_id→invoice_number. - If ambiguous, fetch order history → Nova Lite selects only among returned candidates (never invents).
- Last resort: guarded read-only SQL with strict validation.
- Policy adjudication grounded in Neo4j: With a verified order object, we query the policy graph and produce Approve / Deny / Manual Review with reasoning + citations grounded to the policy text.
- Audit trail: Every stage persists artifacts so results are reproducible and debuggable.
Illustration 3 - Deployed on AWS App Runner and Amplify
.png)
Challenges we ran into
🧠 Reliable decisions without one big prompt A single LLM call that “reads everything and decides” would have been simpler, but not reliable or interpretable for refunds. We reduced risk by separating concerns and building a multi-agent policy grounding pipeline, so the decision step is driven by structured, verifiable context rather than a single free-form output.
⚡ LLM Formatting Quirks
During the Database Verification loop, we ran into instances where the LLM would helpfully wrap its JSON responses in markdown backticks (e.g., `json). Since the server expected pure JSON to execute the tool calls, this caused infinite loops. We solved this by implementing a robust regex-based markdown cleaner prior to JSON parsing to guarantee stability on every turn.
📎 Unstructured Terms & Conditions T&C documents are often clumsy and unstructured. If companies maintained clear, well-structured refund policy documentation, policy knowledge bases would become far more reliable and powerful—making grounded and explainable decisions much easier to produce.
🔎 Grounding + explainability (GraphRAG) Refund decisions need to be defensible, not just plausible. We incorporated GraphRAG over our policy knowledge graph to anchor outcomes to the relevant rules and reduce hallucinations while keeping explanations traceable.
Accomplishments that we're proud of
End-to-end automation We built a complete pipeline where a single return email triggers the entire workflow automatically.
Policy Knowledge Graph from raw T&C Transforming unstructured Terms & Conditions into a policy knowledge graph is hard. We accomplished this using a multi-agent setup with clear roles and clean communication between agents.
Great UX for non-technical users We focused on a simple, guided experience with clear steps, easy navigation, and the right information at every stage, so even a new non-technical user can understand how VARA AI works.
What we learned
Technical learnings:
- Learned how to design and run MCP servers and expose capabilities as tools.
- Learned how to coordinate multi-agent orchestration via Amazon Nova and build agentic workflows that stay maintainable.
- Learned how to model, store, and query a policy graph using Neo4j Aura.
- Learned how to deploy and operate a multi-service system on AWS (App Runner, Amplify, Native Nova APIs).
Explainability and reliability: Our biggest learning was that for customer-facing decisions like refunds, “working” isn’t enough—the system must be reliable, interpretable, and explainable. Building guardrails and grounding (instead of relying on one LLM response) taught us how critical trust and traceability are in real-world AI.
What's next for VARA AI
In the next phase, VARA becomes a two-way claims agent. If key details are missing (order ID, clearer images, additional proof), it sends a targeted follow-up email asking only what’s needed. With case memory, VARA keeps a per-claim summary and retrieves relevant history as replies arrive. Each response triggers re-extraction and re-verification, updating the case until VARA can decide confidently or escalate to manual review.
Future roadmap:
- Voice-based refund support using Nova Sonic: Add a voice agent interface so customers can file and track refunds over a call. The voice layer will only handle conversation—the backend pipeline will run evidence extraction, DB verification, policy grounding, and adjudication.
- Fraud/risk scoring layer: Add a risk signal (return history, mismatch patterns, abnormal refund frequency) so VARA can adapt decisions and route high-risk cases to manual review without slowing down legitimate customers.
Third-party integrations & data sources
- Neo4j AuraDB — GraphRAG policy storage.
- PostgreSQL — Stores and verifies order records during adjudication.
- pypdf — Invoice PDF text extraction.
- LlamaParse — Parsing Policy Documents.
Synthetic / research data: Some synthetic invoice PDFs were sourced from femstac/Sample-Pdf-invoices and used to populate our Postgres orders database for testing. We used Best Buy’s returns/refund policy document strictly for research and prototyping to validate policy grounding and explainability in VARA AI (not affiliated with or endorsed by Best Buy).
Built With
- amazon-web-services
- amplify
- app-runner
- asyncio
- beautiful-soup
- bedrock
- boto3
- docker
- fastapi
- fastmcp
- firestore
- gmail-api
- google-cloud-sql
- javascript
- llama-parse
- mcp
- multi-agent-system
- neo4j-aura
- nova
- oauth
- openai
- postgresql
- pubsub
- pypdf
- python
- sse-starlette
- uvicorn

Log in or sign up for Devpost to join the conversation.