-
-
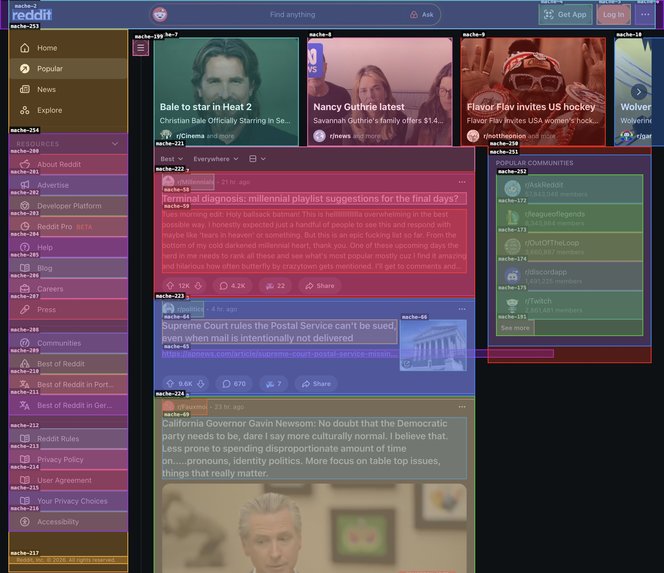
SVG Overlay sent to orient Gemini, built using FFT over pixel coloration and canny / sobel edge detection

Inspiration
Every UI navigation agent today works the same way: take a screenshot, guess which pixel to click, hope for the best. When the guess is wrong, retry with a new screenshot. I'd recently built Mache, an open-source tool that projects structured data (code ASTs, SQLite databases, JSON) into semantic file-systems for coding agents. Then I realized: the DOM is an AST too. What if Gemini's vision could map a webpage into a filesystem, and an agent could navigate it with ls and cat instead of guessing coordinates?
What it does
X-Ray is a universal agent-computer interface that translates the visual web into a deterministic POSIX filesystem. By mapping DOM elements to a virtual file structure, it allows AI agents to navigate web pages using reliable CLI commands (ls, cat, act) instead of fragile pixel coordinates or complex XPaths.
A Chrome extension captures a scaled JPEG screenshot and tags interactive elements with stable IDs, enriching each with DOM breadcrumb paths and accessibility tree metadata via CDP. Gemini 2.5 Flash uses its multimodal vision to identify 3-7 semantic zones (e.g., /header/nav, /main/post_feed, /footer) and synthesize CSS selectors for list zones. Those zones are mounted as a virtual filesystem via the Mache engine. A second Gemini agent - the Navigator - traverses that filesystem using ls, cat, act, and scroll tools to resolve user intents like "click the first story" to a specific, deterministic DOM element. No pixel coordinates, no guessing, no fragile XPaths.
With Gemini Live API integration, users can speak naturally: "click the third trending repo" and hear "Done" - the entire tool-use loop executes silently while Gemini's native voice handles the conversation.
How I built it
X-Ray is a single Go binary (agentd) with three internal components, connected to a Chrome extension:
The Cartographer (Stage 1): Gemini Vision maps a scaled JPEG screenshot + tagged DOM summary into a strict JSON schema of semantic zones. Each summary line includes DOM breadcrumb paths (
div.post > h3.title > a) and accessibility metadata (AXRole,AXName) from the browser's computed accessibility tree via CDP. Uses structured output mode (ResponseSchema) so the model literally cannot hallucinate field names or IDs. For list zones, it outputs both primary item IDs and a CSSitem_selectorfor dynamic scroll resolution.The Mache Engine: Translates the Cartographer's JSON into a virtual in-memory filesystem. Each zone becomes a directory with
description,mache_id,children, and_c/subdirectories for individual elements. The Navigator sees clean paths like/main/story_list/_c/mache-13instead ofdiv[4]/span/button.The Navigator (Stage 2): A Gemini function-calling agent with four tools:
ls(list directory),cat(read file),act(execute browser action),scroll(load more content). It resolves "click the first story" in 3-4 tool calls by traversing the filesystem top-down. For items beyond the viewport, it scrolls and retries - up to 8 iterations.
Features
Voice Mode: The Gemini Live API streams audio bidirectionally. The user speaks, Gemini calls the same
ls/cat/acttools, and responds with voice. Tool execution is muted server-side - no narration of "I'm now looking at the directory..." - just silence, then "Done."The Chrome Extension: A Manifest V3 extension with
content.js(injectsdata-mache-idtags, generates DOM breadcrumb paths, evaluates CSS selectors after scroll, executes actions),background.js(WebSocket to agentd, scaled JPEG screenshot capture, CDP accessibility tree enrichment), and an offscreen document for persistent voice sessions.Infrastructure: Deployed on Google Cloud Run via automated deploy script. All Gemini calls go through the Google GenAI SDK (Go). Per-tab sessions ensure switching between tabs preserves each tab's schema.
Challenges I ran into
The Cartographer attempt sent raw HTML (200KB+) to Gemini and took over 3 minutes on GitHub's trending page. Gemini was drowning in token ingestion, not reasoning. I replaced the raw HTML with a flattened interactive element summary (~10KB, down from 200KB+) -
ID | Parent | Tag | Text | Path | AXRole | AXNameper element - and let Gemini rely purely on its vision for layout understanding. ThePathbreadcrumb gives the Cartographer structural context (2-3 levels of DOM ancestry with CSS classes), whileAXRole/AXNameprovide the browser's computed accessibility semantics via CDP. Latency dropped from over 3 minutes to 3-10 seconds.Granularity. The Cartographer identifies zones, not individual elements. "Click the first story" resolved to the story list container, not the first link. I solved this by adding parent-aware child resolution: the summary tracks parent-child relationships, and the engine mounts up to 200 children per zone with LLM-identified primary items (the main clickable element in each repeating group). Now ordinal counting ("click the 3rd story") works correctly across any site.
Scrolling. Primary items are identified by mache-id on initial page load, but after scrolling, new content gets new IDs not in the original list. I solved this with dynamic CSS selectors: each summary line includes a DOM breadcrumb path (
div.post > h3.title > a), and the Cartographer uses these structural patterns to synthesize a CSS selector per zone (e.g.,article.w-full > shreddit-post.block > a[data-mache-id]). After scrolling, the browser evaluates this selector natively viaquerySelectorAlland returns fresh IDs - no second LLM call needed. The LLM identifies what matters visually; the browser executes it deterministically.Chrome's MV3 service worker lifecycle. Service workers die after ~30s of inactivity, killing the WebSocket. A keep-alive alarm every 24 seconds solves this. For voice, MV3 popups close on blur - terrible for streaming audio. I used an offscreen document instead, which persists independently with
getUserMediaandAudioContextaccess.
Accomplishments I'm proud of
Zero hallucinated IDs across all test pages (Hacker News, GitHub, Wikipedia, eBay, Reddit/Lobsters). Every mache_id the Cartographer returns is validated against actual DOM elements - if any are hallucinated, the schema is regenerated automatically.
The architecture proves that multimodal vision and structural grounding aren't competing approaches - vision generates the structure, and the structure enables deterministic action. The Navigator never guesses; it traverses a filesystem that was built from what Gemini actually saw.
The hybrid scroll architecture - where the LLM identifies visual patterns and the browser executes them deterministically - is genuinely novel. Most agents either re-invoke the LLM after every scroll (slow, expensive) or use fragile heuristics that break across sites. X-Ray's approach runs querySelectorAll with an LLM-synthesized selector, getting the best of both worlds.
I also built Mache as standalone open-source infrastructure before this challenge - the projection engine that makes this possible isn't a one-off hack, it's a general-purpose tool for any agent that needs to reason over structured data.
What I learned
LLMs reason better when information is projected into the shape they think in.
A filesystem with /main/news_feed and /sidebar/filters is strictly more navigable than 200KB of nested divs - for the same reason cd functions/HandleRequest/ beats grep -r "HandleRequest" . in a codebase. The DOM is a delivery mechanism for browsers. Agents need a different projection of the same data.
The most powerful pattern is decoupling perception from execution. Use the expensive vision model once to identify what matters (semantic zones, structural patterns), then delegate all subsequent work to cheap, deterministic operations (filesystem traversal, querySelectorAll). This is why infinite scroll costs nearly zero after the initial schema - the LLM already told the browser what to look for.
Temperature matters more than prompt engineering. Running both agents at 0.1 gave us near-deterministic behavior: the same page + intent produces the same action across runs. This is critical for a voice-driven UI agent where users expect reliability.
Gemini's native voice is genuinely good at tool-use conversations. The hardest part wasn't getting it to call tools - it was getting it to stop narrating its internal thought process ("I am now looking at the directory..."). Server-side audio suppression during tool-execution loops created a clean, silent UX: the user speaks, there's a brief pause, then just "Done."
What's next for X-Ray
The core architecture - vision-to-filesystem projection, deterministic navigation, and dynamic scroll resolution - is complete and working across Reddit, Hacker News, GitHub, Wikipedia, eBay, and Lobsters. Extensions we're exploring:
Schema caching so repeat visits to the same site layout skip the Cartographer entirely. Local SLM for the Navigator's tool loop - the ls/cat/act/scroll function-calling pattern is simple enough for a small model, which would eliminate API latency for the action-resolution step. Write-back support - not just reading the web, but filling forms with structural guarantees that the right fields get the right data. And deeper Mache integration: projecting the DOM into an actual NFS mount so any Unix tool can explore a webpage.





Log in or sign up for Devpost to join the conversation.