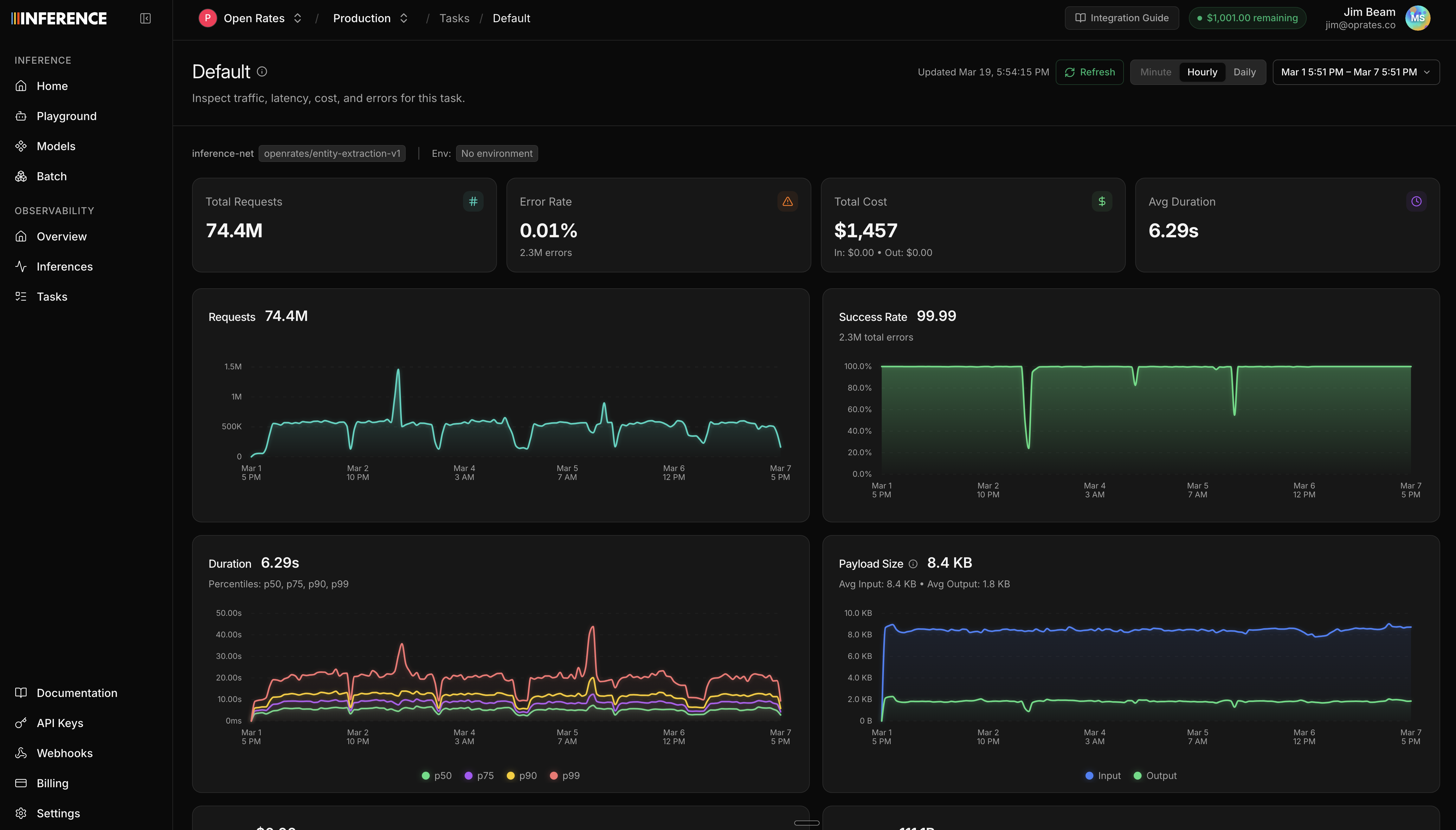
- Capture and observe production traffic. Use models from any provider.
- Create and run evals against production data to understand your application.
- Create datasets and fine-tune models from observed traffic to create better, task-specific models.
- Deploy models behind a stable production endpoint to use in your application.
Quickstart
Capture Traffic (Start Here)
Route LLM traffic through Inference.net and observe your first request
API Quickstart
Make your first calls to models deployed on Inference.net
Search models
Browse the model catalog before you pick an API or deployment path.
Meet with Us
Met with to our research team to discuss your use case and get help.