Build Better Models, Faster.
Your model development cycle takes 10x longer than it should because your data is scattered across five systems that don't talk to each other. LanceDB is the AI-native Multimodal Lakehouse, the unified foundation to accelerate training dataset development.

Tomorrow's AI is being built on LanceDB today














.svg)


No items found.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
No items found.
One table for all your training data. performant for any workload.
Developing the right dataset is critical for model quality. Feeding that dataset to the GPU efficiently is essential for cost-effective training at scale. Doing both without being mired in low level details gives you the data flywheel to improve models fast.

70% MFU
Dedicated fast training storage with low-overhead random access. Global shuffles and ad-hoc transforms without sacrificing GPU utilization. No object store throttling.


Automated pre-processing
5 lines of code runs thousands of nodes. Declarative feature pipelines. Automatic embedding updates. Add any new feature without rewriting existing data.
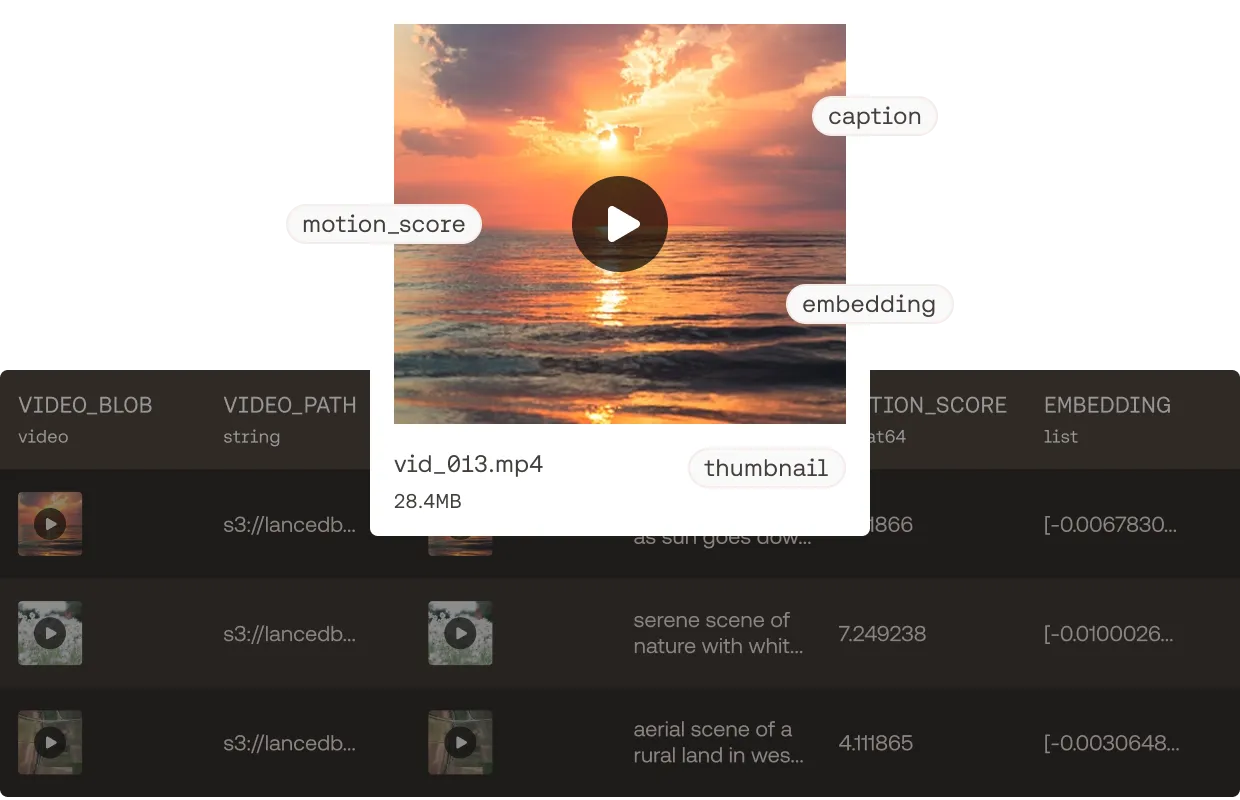

10x faster data experimentation
Parallelize feature variants with agents. Automatic versioning. Branch, roll back, tag, all without duplicating data.
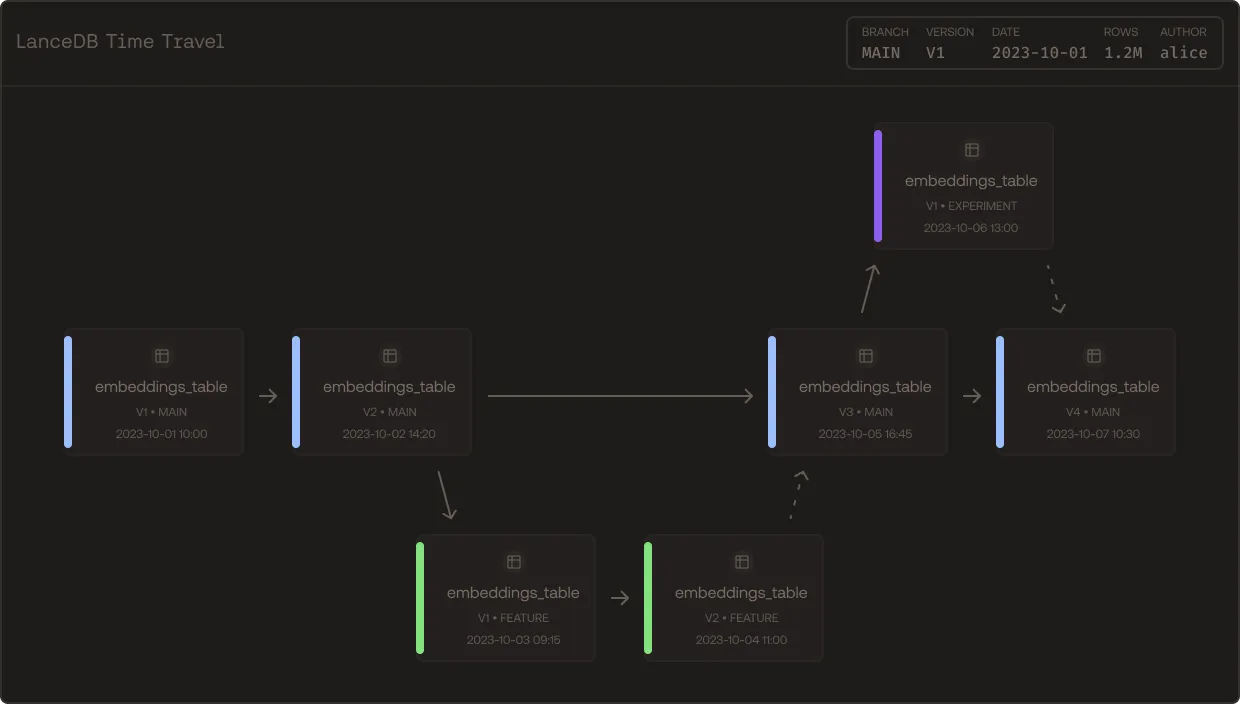

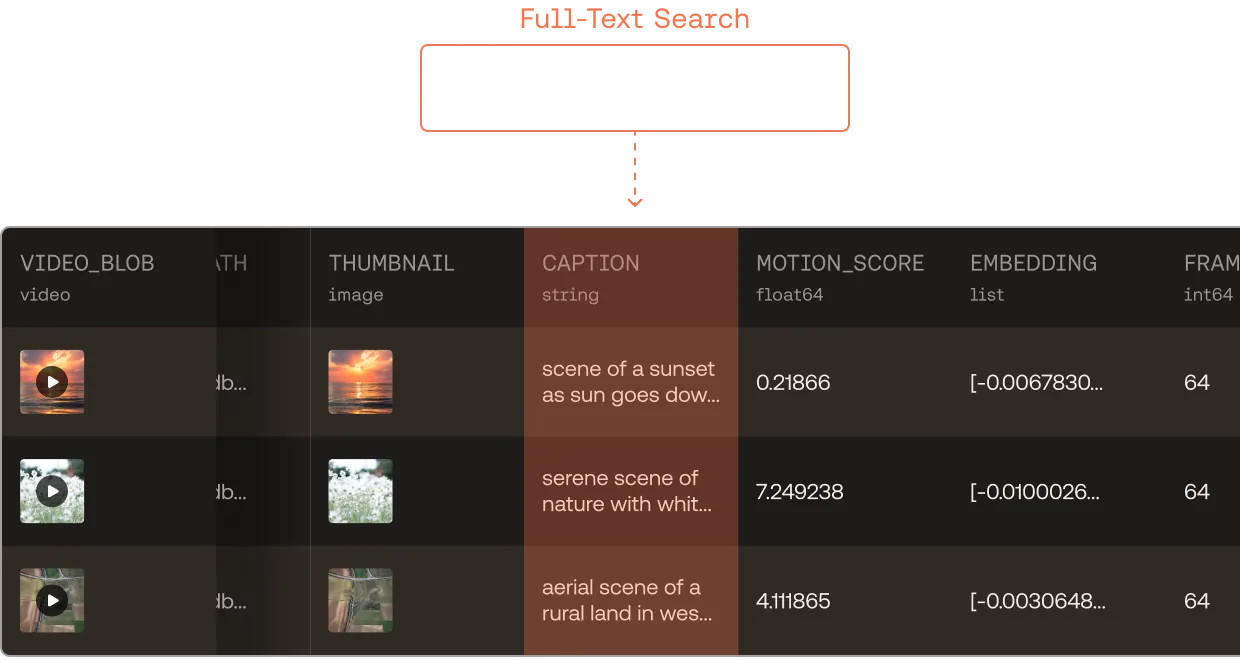
All your data in one place. Searchable at trillion row scale
Search over raw bytes, enriched features, metadata, and embeddings live together. Horizontally scalable to 100K QPS for massively parallel agents. Built on the new open source standard for multimodal data.
Iterate on your training dataset,
not your
spark job
YAML files
K8s config
Feature Store
Search index
A single platform for curation, feature engineering, retrieval, and training at massive scale. No data sync jobs. No ad-hoc scripts. No losing GPU utilization waiting for shuffle and load.

Curation
Find the optimal distribution. Deduplicate hundreds of billions of rows. Identify edge cases for labeling. All from the same place.

Feature Engineering
Write Python UDFs locally. Plug and run at petabyte scale with automatic updates. Add columns without rewriting the table. Built for agents and humans.

Training
Accelerated training from the same table you explored and curated. Get up to 70% MFU with no egress bottleneck.

Search & Analytics
Vector/semantic, full-text, and hybrid search combined with SQL filters against one table. The unified layer for production-grade agentic retrieval.
Built for Petabyte Exabyte Scale
Production-proven infrastructure powering the world’s most demanding AI training workloads.
up to 70%
Model FLOPS Utilization
100K+
Queries per second
100B+
Rows in a single table
Trusted in Production By

“Lance transformed our model training pipeline at Runway. The ability to append columns without rewriting entire datasets, combined with fast random access and multimodal support, lets us iterate on AI models faster than ever. For a company building cutting-edge generative AI, that speed of iteration is everything.”
“Lance has been a significant enabler for our multimodal data workflows. Its performance and feature set offer a dramatic step up from legacy formats like WebDataset and Parquet. Using Lance has freed up considerable time and energy for our team, allowing us to iterate faster and focus more on research.”
“Law firms, professional service providers, and enterprises rely on Harvey to process a large number of complex documents in a scalable and secure manner. LanceDB’s search/retrieval infrastructure has been instrumental in helping us meet those demands.”
Migrating full-text search from ElasticSearch to LanceDB reduced our p90 latency by over 90%. The integration with Spark allows us to continue iterating on this system faster than ever!
“Midjourney generates breathtaking imagery for millions of users worldwide. Vector search is critical infrastructure that allows us to better serve our users. We evaluated multiple solutions and LanceDB was the only one that could meet the high-traffic and large scale requirements we had. We couldn't be happier with our decision.”
LanceDB transformed how we handle context at scale. While other vector databases hit cost and performance walls, LanceDB scales effortlessly with our growth—from startup to enterprise. Its multimodal capabilities and deployment flexibility were game-changers, enabling us to deliver the depth of analysis our customers expect while maintaining sub-second response times across millions of code reviews.
Ready To 10x Your Model Training Lifecycle?
Contact Sales