The theory of error-correcting codes and more broadly, information theory, originated in Claude Shannon’s monumental work A mathematical theory of communication, published over 60 years ago in 1948. Shannon’s work gave a precise measure of the information content in the output of a random source in terms of its entropy. The noiseless coding theorem or the source coding theorem informally states that 
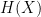


More directly relevant to this course is Shannon’s noisy coding theorem which considered communication of a message (say consisting of 






We will return to Shannon’s probabilistic viewpoint and in particular his noisy coding theorem in a couple of lectures, but we will begin by introducing error-correcting codes from a more combinatorial/geometric viewpoint, focusing on aspects such as the minimum distance of the code. This viewpoint was pioneered by Richard Hamming in his celebrated 1950 paper Error detecting and error correcting codes. The Hamming approach is more suitable for tackling worst-case/adversarial errors, whereas the Shannon theory handles stochastic/probabilistic errors. This corresponds to a rough dichotomy in coding theory results — while the two approaches have somewhat different goals and face somewhat different limits and challenges, they share many common constructions, tools, and techniques. Further, by considering meaningful relaxations of the adversarial noise model or the requirement on the encoder/decoder, it is possible to bridge the gap between the Shannon and Hamming approaches. (We will see some results in this vein during the course.)
The course will be roughly divided into the following interrelated parts. We will begin by results on the existence and limitations of codes, both in the Hamming and Shannon approaches. This will highlight some criteria to judge when a code is good, and we will follow up with several explicit constructions of “good” codes (we will encounter basic finite field algebra during these constructions). While this part will mostly have a combinatorial flavor, we will keep track of important algorithmic challenges that arise. This will set the stage for the algorithmic component of the course, which will deal with efficient (polynomial time) algorithms to decode some important classes of codes. This in turn will enable us to approach the absolute limits of error-correction “constructively,” via explicit coding schemes and efficient algorithms (for both worst-case and probabilistic error models).
Codes, and ideas behind some of the good constructions, have also found many exciting “extraneous” applications such as in complexity theory, cryptography, pseudorandomness and explicit combinatorial constructions. (For example, in the spring 2009 offering of 15-855 (the graduate complexity theory course), we covered in detail the Sudan-Trevisan-Vadhan proof of the Impagliazzo-Wigderson theorem that 

We now look at some simple codes and give the basic definitions concerning codes. But before that, we will digress with some recreational mathematics and pose a famous “Hat” puzzle, which happens to have close connections to the codes we will soon introduce (that’s your hint, if you haven’t seen the puzzle before!)
Guessing hat colors
The following puzzle made the New York Times in 2001.
No communication of any sort is allowed, except for an initial strategy session before the game begins. Once they have had a chance to look at the other hats, the players must simultaneously guess the color of their own hats or pass. The group wins the game if at least one player guesses correctly and no players guess incorrectly.
One obvious strategy for the players, for instance, would be for one player to always guess “red” while the other players pass. This would give the group a 50 percent chance of winning the prize. Can the group achieve a higher probability of winning (probability being taken over the initial random assignment of hat colors)? If so, how high a probability can they achieve?
(The same game can be played with any number of players. The general problem is to find a strategy for the group that maximizes its chances of winning the prize.)
1. A simple code
Suppose we need to store 64 bit words in such a way that they can be correctly recovered even if a single bit per word gets flipped. One way is to store each information bit by duplicating it three times. We can thus store 21 bits of information in the word. This would permit only about a fraction 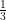
Hamming in 


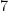

This transformation can equivalently be represented as a mapping from 


![{[x_1\hspace{2pt} x_2\hspace{2pt} x_3\hspace{2pt} x_4]^T}](https://s0.wp.com/latex.php?latex=%7B%5Bx_1%5Chspace%7B2pt%7D+x_2%5Chspace%7B2pt%7D+x_3%5Chspace%7B2pt%7D+x_4%5D%5ET%7D&bg=ffffff&fg=000000&s=0&c=20201002)


It is easy to verify that two distinct 









2. Some basic definitions
Let us get a few simple definitions out of the way.
Definition 1 (Hamming distance) The Hamming distance between two strings
and
of the same length over a finite alphabet
, denoted
, is defined as the number of positions at which the two strings differ, i.e.,
. The fractional Hamming distance or relative distance between
is given by
.
It is trivial to check that the Hamming distance defines a metric on 
Definition 2 (Hamming weight) The Hamming weight of a string
. Note that
.
Given a string 


Definition 3 (Code) An error correcting code or block code
, we say that
-ary code. When
, we say that
Associated with a code is also an encoding map
which maps the message set
, identified in some canonical way with
say, to codewords belonging to
We now define two crucial parameters concerning a code: its rate which measures the amount of redundancy introduced by the code, and its minimum distance which measures the error-resilience of a code quantified in terms of how many errors need to be introduced to confuse one codeword for another.
Definition 4 (Rate) The rate of a code
, denoted
, is defined by
Thus,
; this terminology will make sense once we define linear codes shortly. Note that a
has
codewords.

Definition 5 (Distance) The minimum distance, or simply distance, of a code
, is defined to be the minimum Hamming distance between two distinct codewords of
In particular, for every pair of distinct codewords in
, is the normalized quantity
, where

Example 1 The parity check code, which maps
bits by appending the parity of the message bits, is an example of distance
.
Example 2 The Hamming code discussed earlier is an example of distance 3 code, and has rate
.
The following simple fact highlights the importance of distance of a code for correcting (worst-case) errors. The proof follows readily from the definition of minimum distance.
Lemma 6 For a code, the following statements are equivalent:
.
symbol errors.
symbol errors.
3. Linear codes
A general code might have no structure and not admit any representation other than listing the entire codebook. We now focus on an important subclass of codes with additional structure called linear codes. Many of the important and widely used codes are linear.
Linear codes are defined over alphabets 

Definition 7 (Linear code) If
is a subspace of
As 

Definition 8 (Generator matrix and encoding) Let
be a linear code of dimension
is said to be a generator matrix for
The generator matrix(thought of as a column vector) as the codeword
. Thus a linear code has an encoding map
which is a linear transformation
.
Comment: Many coding texts define the “transpose” version, where the rows of the 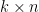
Note that a linear code admits many different generator matrices, corresponding to the different choices of basis for the code as a vector space.
Notation: A ![{[n,k]_q}](https://s0.wp.com/latex.php?latex=%7B%5Bn%2Ck%5D_q%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{[n,k,d]_q}](https://s0.wp.com/latex.php?latex=%7B%5Bn%2Ck%2Cd%5D_q%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Example 3 Some simple examples of binary linear codes:
- The binary parity check code: This is an
code consisting of all vectors in
of even Hamming weight.
- The binary repetition code: This is an
code consisting of the two vectors
and
.
- The Hamming code discussed above is a
linear code.
Exercise 1 Show that for a linear code

Exercise 2 (Systematic or standard form) Let
where
is the
identity matrix and
is some
matrix.
A generator matrix in the form 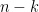
![{[7,4,3]}](https://s0.wp.com/latex.php?latex=%7B%5B7%2C4%2C3%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
3.1. Parity check matrices
The following is a good way to flex your basic linear algebra muscles (Exercise 2 is a useful way to proceed):
Exercise 3 Prove that
of full row rank such that

In other words, 
Lemma 9 If
3.2. Hamming code revisited
The Hamming code is best understood by the structure of its parity check matrix. This will also allow us to generalize Hamming codes to larger lengths.
We defined the ![{C_{\rm Ham} = [7, 4, 3]_2}](https://s0.wp.com/latex.php?latex=%7BC_%7B%5Crm+Ham%7D+%3D+%5B7%2C+4%2C+3%5D_2%7D&bg=ffffff&fg=000000&s=0&c=20201002)

If we define the matrix

then one can check that 

Correcting single errors with the Hamming code: Suppose that 

A more slick (and faster) way to correct 
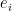


Definition 10 (Syndrome) The vector
is said to be the syndrome of
Generalized Hamming codes: Define 




Now we can define the

to be the binary code with parity check matrix
Lemma 11
is an
code.
Proof: Since 


Despite its simplicity, the Hamming code is amazing in that it is optimal in the following sense.
Lemma 12 If
It follows that the Hamming code
and minimum distance at least

Proof: This is a special case of the “Hamming volume” (upper) bound on the size of codes. For each 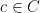




giving the desired upper bound on 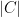



The obvious generalization of the above argument to arbitrary distances
Lemma 13 (Hamming bound) Let

Note that for equality to hold in (2) something remarkable must happen. Hamming balls of radius 
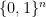
By Lemma 12, Hamming codes are perfect. It turns out that perfect codes are a rare phenomenon. The following theorem (which is beyond the scope of this course) enumerates all (binary) perfect codes:
Theorem 14 (Tietavainen and van Lint) The following are all the binary perfect codes:
- The Hamming codes
- The
Golay code
- The trivial codes consisting of just one codeword, or the whole space, or the repetition code
for odd
The Golay code 



![{{\mathbb F}_2[X]/(X^{23}-1)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+F%7D_2%5BX%5D%2F%28X%5E%7B23%7D-1%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
3.3. Dual of a code
Since a linear code is a subspace of 
Definition 15 (Dual code) If
, is a linear code over
where
is the dot product over
and

Using Exercise 3, verify the following.
Exercise 4
- If
linear code.
.
- If
is a generator matrix for
. Equivalently, if
is a parity check matrix for
Unlike vector spaces over 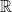






Exercise 5 For every even
A rather mysterious phenomenon in coding theory is that for many constructions of good codes, their dual also has some nice properties. We will now discuss the dual of the Hamming code, a code called the Hadamard code which has been highly influential and played a fundamental role in the computer-scientists’ study of coding theory.
3.4. Hadamard code
The dual of the Hamming code 

![{[2^r-1,r]_2}](https://s0.wp.com/latex.php?latex=%7B%5B2%5Er-1%2Cr%5D_2%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Definition 16 (Hadamard code) The binary Hadamard code
is a
linear code whose
generator matrix has all
by a string in
consisting of the dot product
for every
. The Hadamard code can also be defined over
with its dot product with every vector in
We note that the Hadamard code is the most redundant linear code in which no two codeword symbols are equal in every codeword. Hadamard codes have excellent distance property:
Lemma 17 The Hadamard code
.
Proof: We prove that for 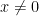





We will later see that binary codes cannot have relative distance more than 
Comment: The first order Reed-Muller code is a code that is closely related to the Hadamard code. Linear algebraically, it is simply the subspace spanned by the Hadamard code and the all 




![{[2^r,r+1,2^{r-1}]_2}](https://s0.wp.com/latex.php?latex=%7B%5B2%5Er%2Cr%2B1%2C2%5E%7Br-1%7D%5D_2%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Code families and Asymptotically good codes
The Hamming and Hadamard codes exhibit two extremes in the trade-off between rate and distance. Hamming codes have rate approaching
To formulate this question formally, and also because our focus in this course is on the asymptotic behavior of codes for large block lengths, we consider code families. Specifically, we define a family of codes to be an infinite collection 
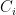
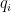
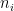


We have defined the alphabet sizes 
The notions of rate and relative distance naturally extend to code families. The rate of an infinite family of codes 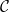

The (relative) distance of a family of codes

A 
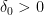


In this terminology, the question raised above concerning (binary) codes with both good rate and good distance, can be phrased as: “Are there asymptotically good binary code families?”
For a code family, achieving a large rate and large relative distance are naturally conflicting codes, and there are fundamental trade-offs between these. We will study some of these in the course. A good deal is known about the existence (or even explicit construction) of good codes and as well as limitations of codes, but the best possible asymptotic trade-off between rate and relative distance for binary codes remains a fundamental open question. In fact, the asymptotic bounds have seen no improvement since 1977!
[This post was typseset using the LaTeX to WordPress-HTML converter LaTeX2WP.]


A self-orthogonal code is a code such that
such that  and not the other way around. This has been corrected in the notes.
and not the other way around. This has been corrected in the notes.
Comment by Venkat Guruswami — January 21, 2010 @ 3:27 pm |
extra-ordinary notes
Comment by Gurmeet Singh — February 27, 2010 @ 3:31 am |
[…] systematic to dual to quantum gates Posted on August 10, 2011 by [email protected] from https://errorcorrectingcodes.wordpress.com/2010/01/12/lecture-material-1-introduction-linear-codes/ […]
Pingback by systematic to dual to quantum gates | Peter's ruminations — August 10, 2011 @ 7:51 pm |