Downloaded 24 times

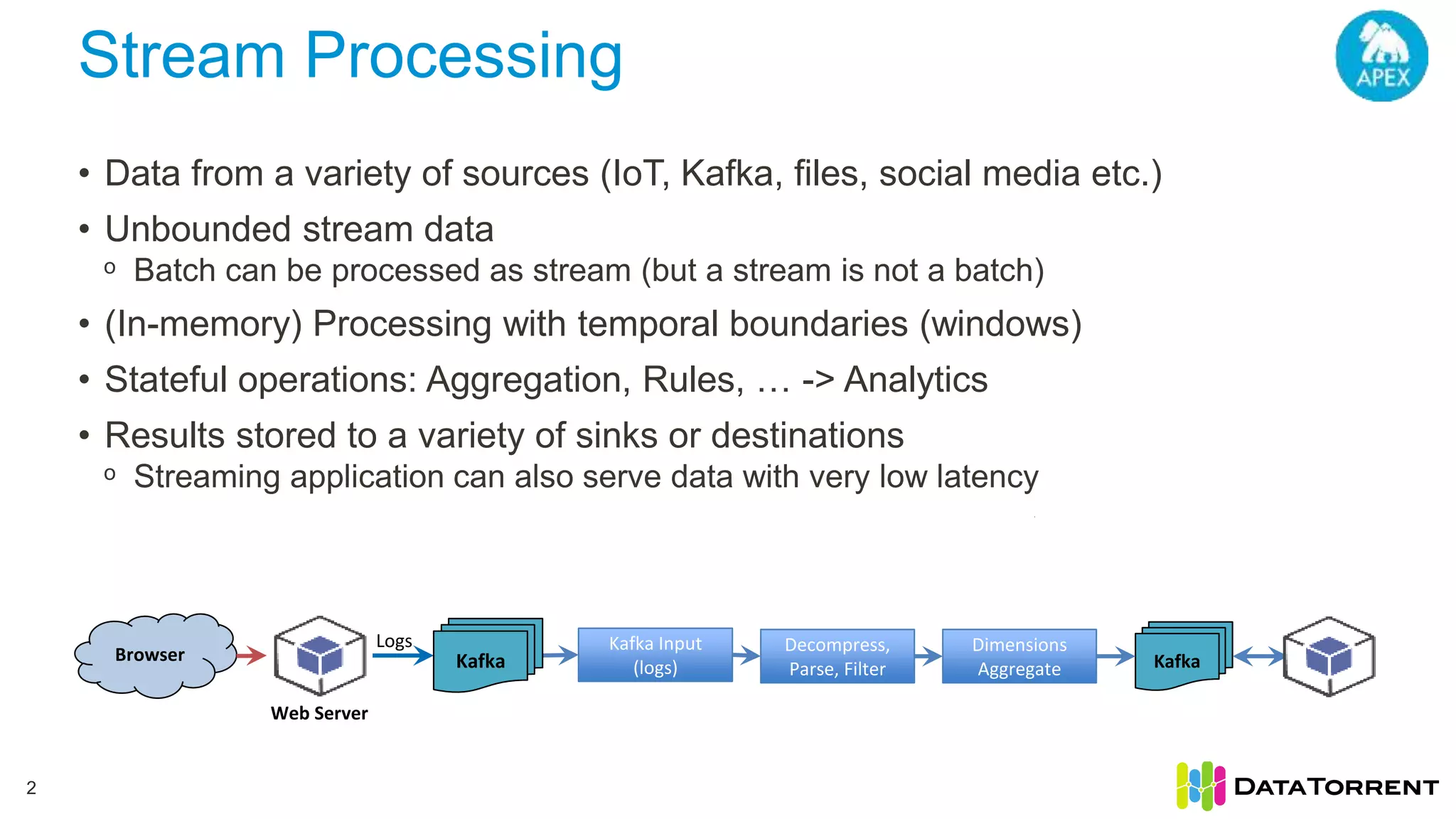



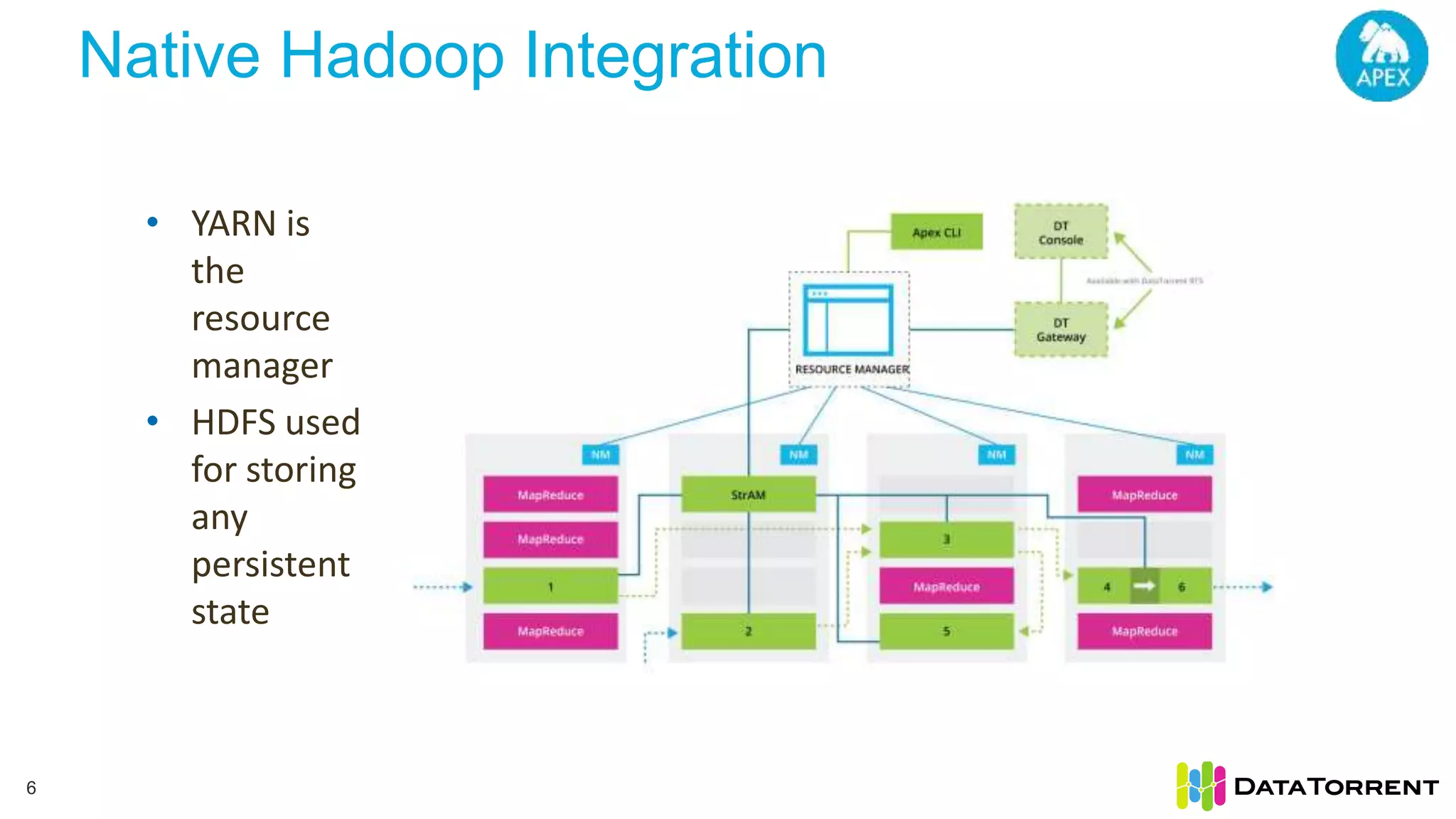
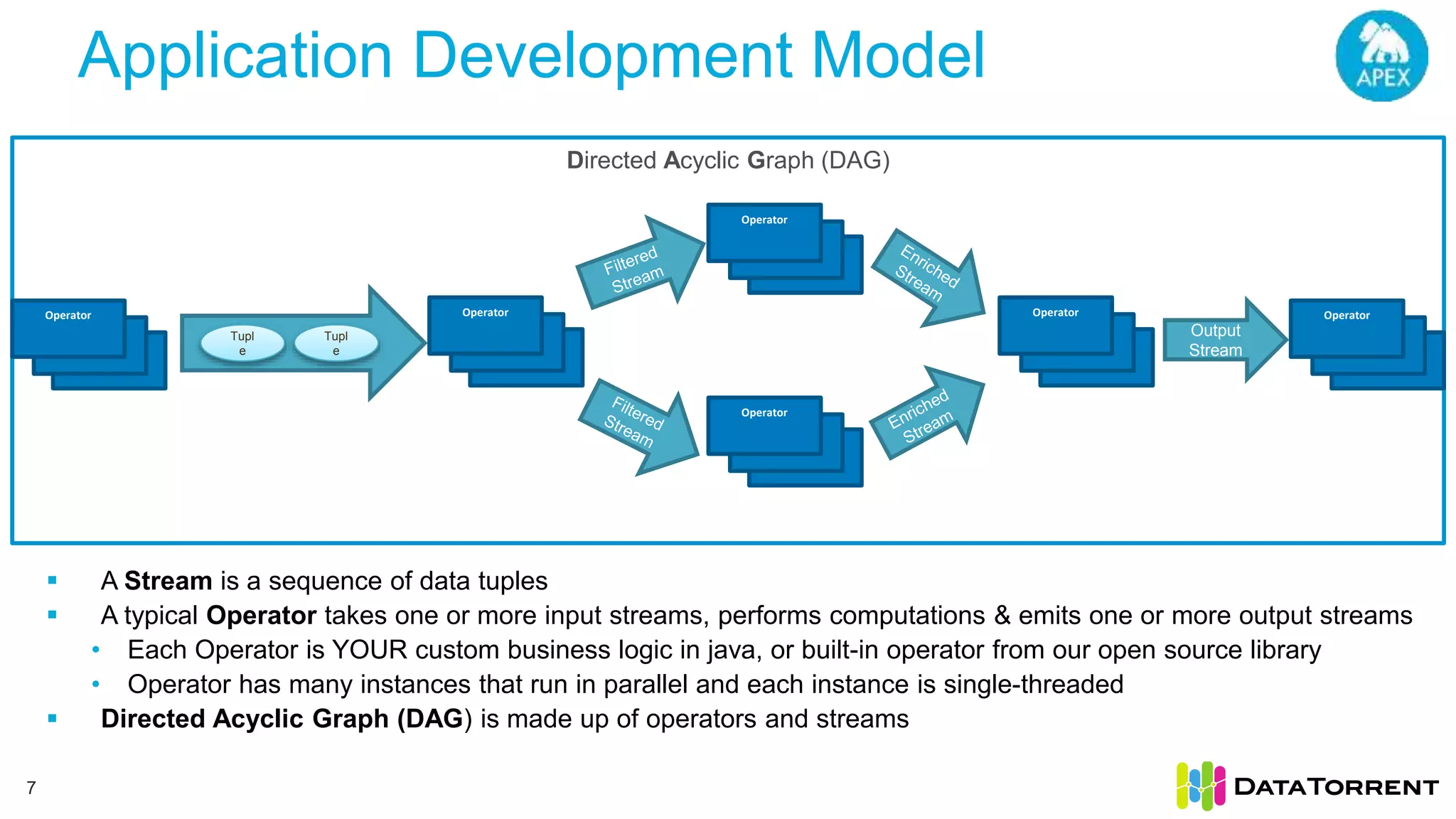
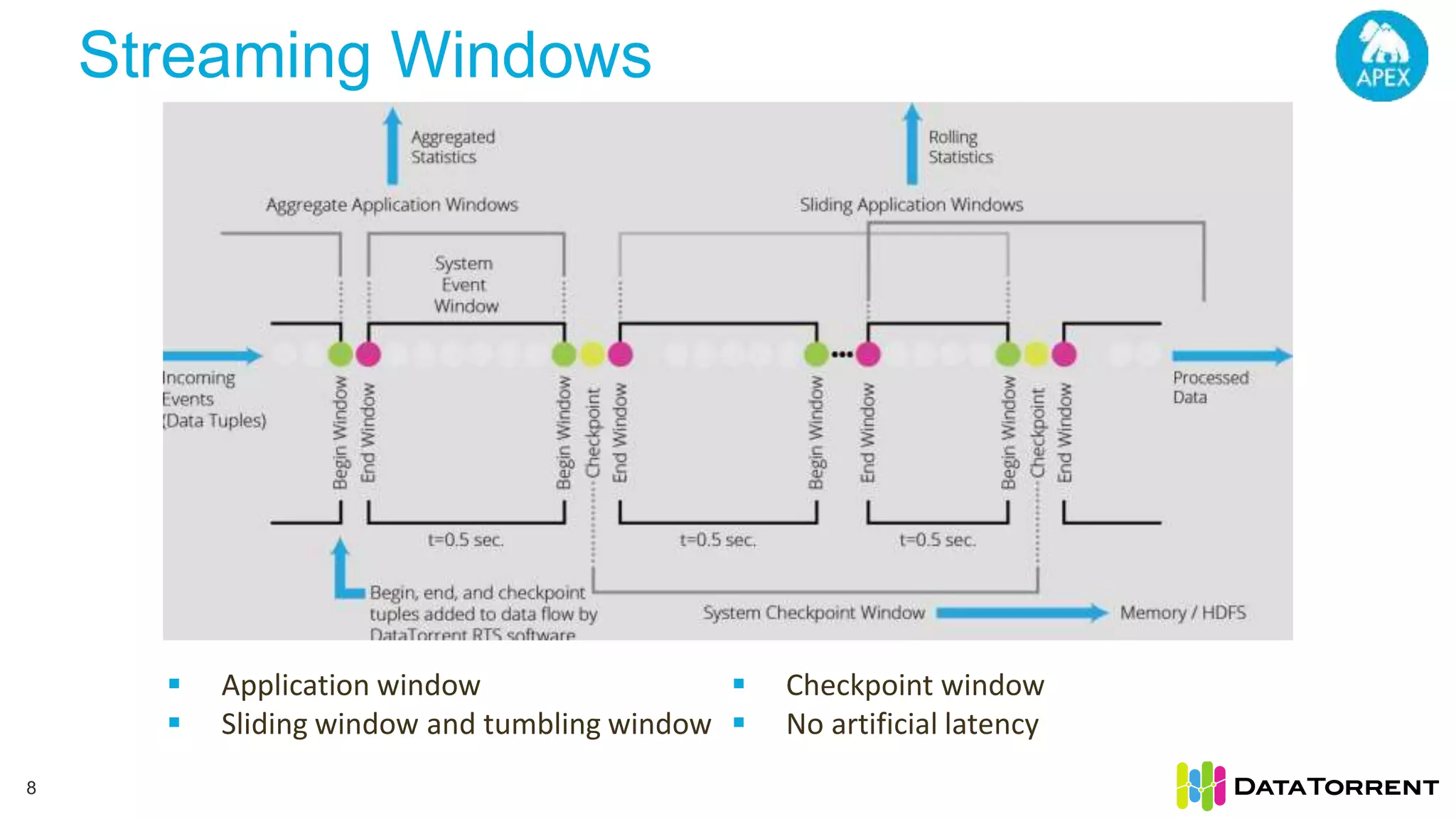

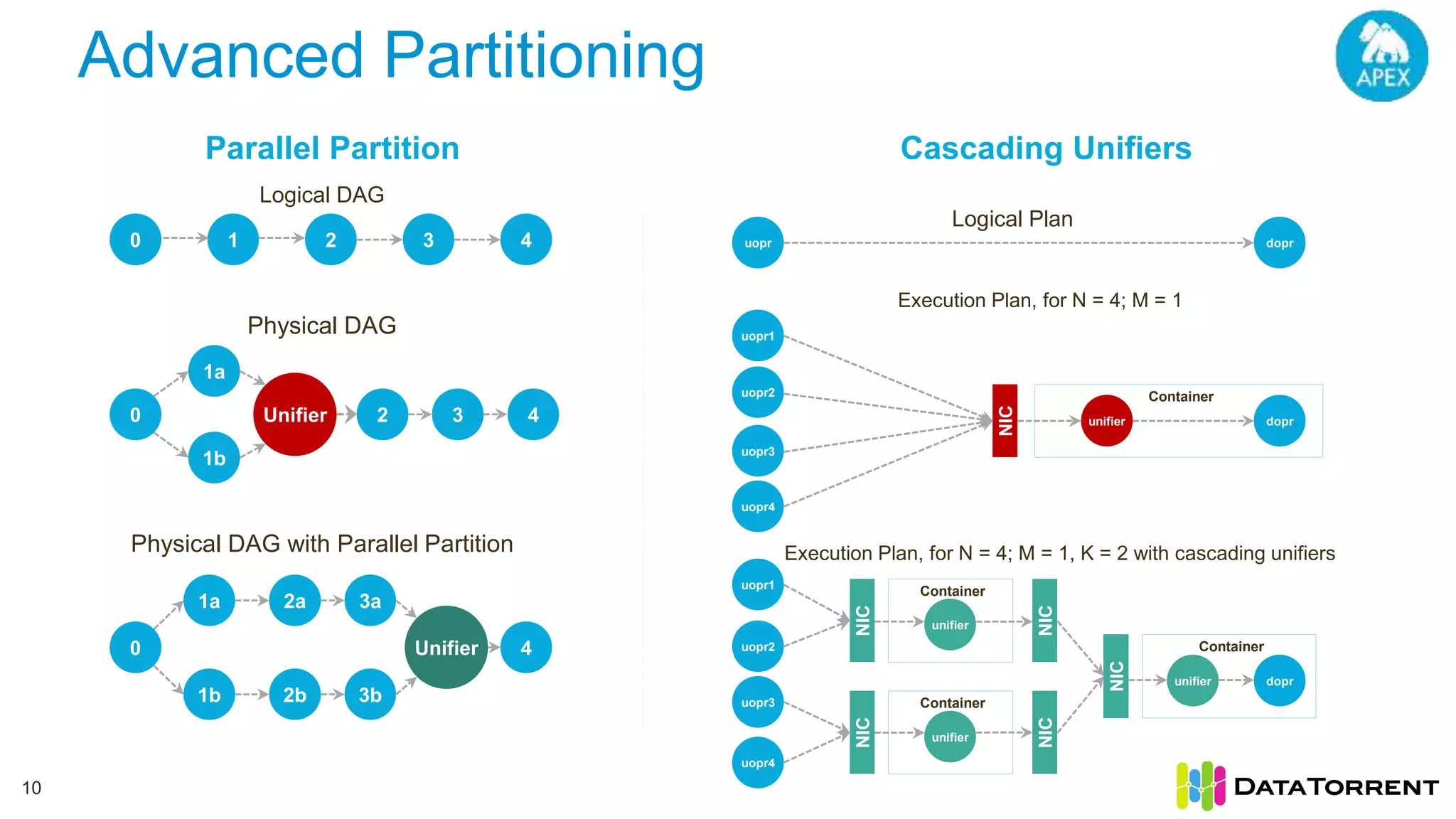

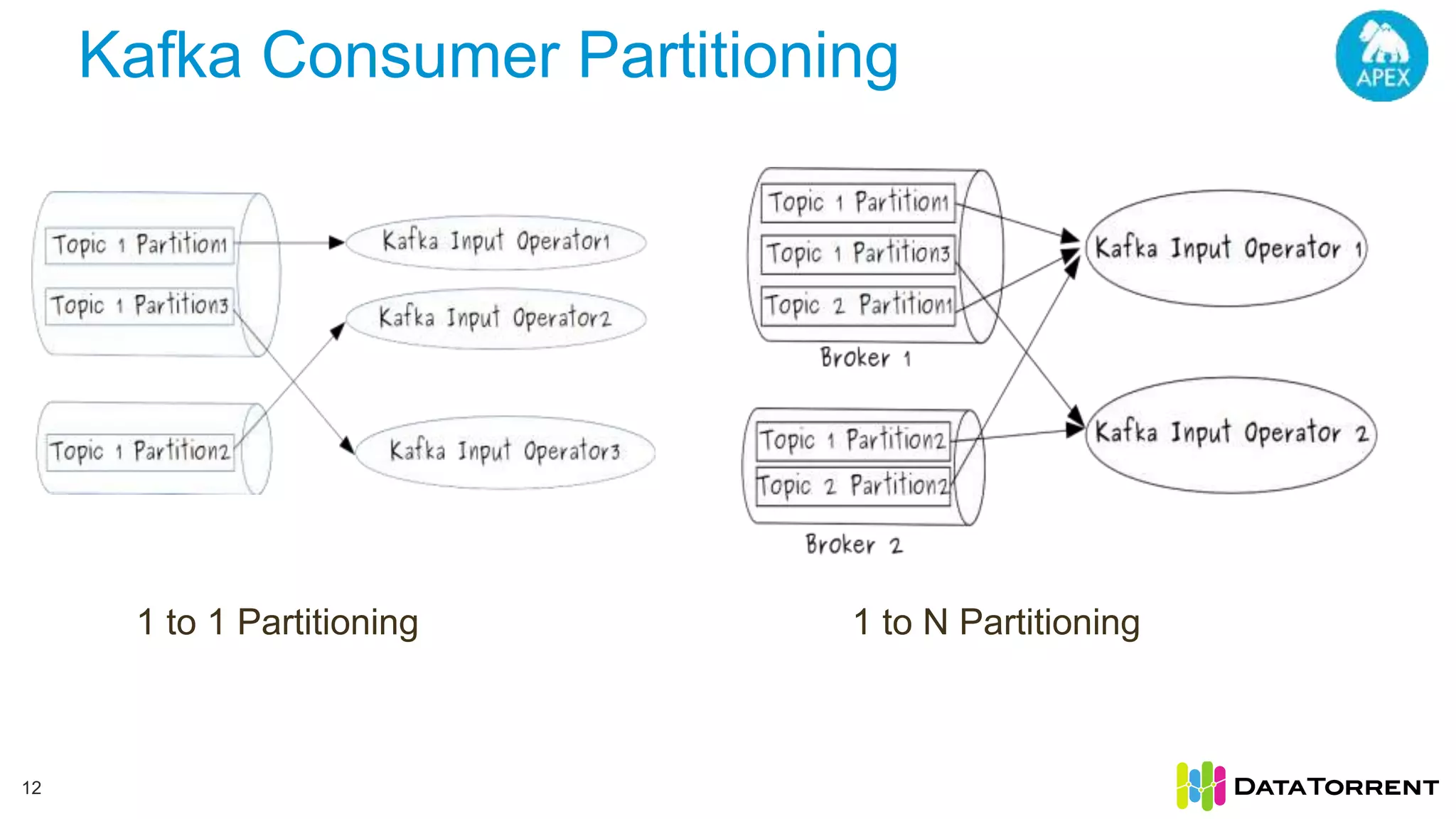

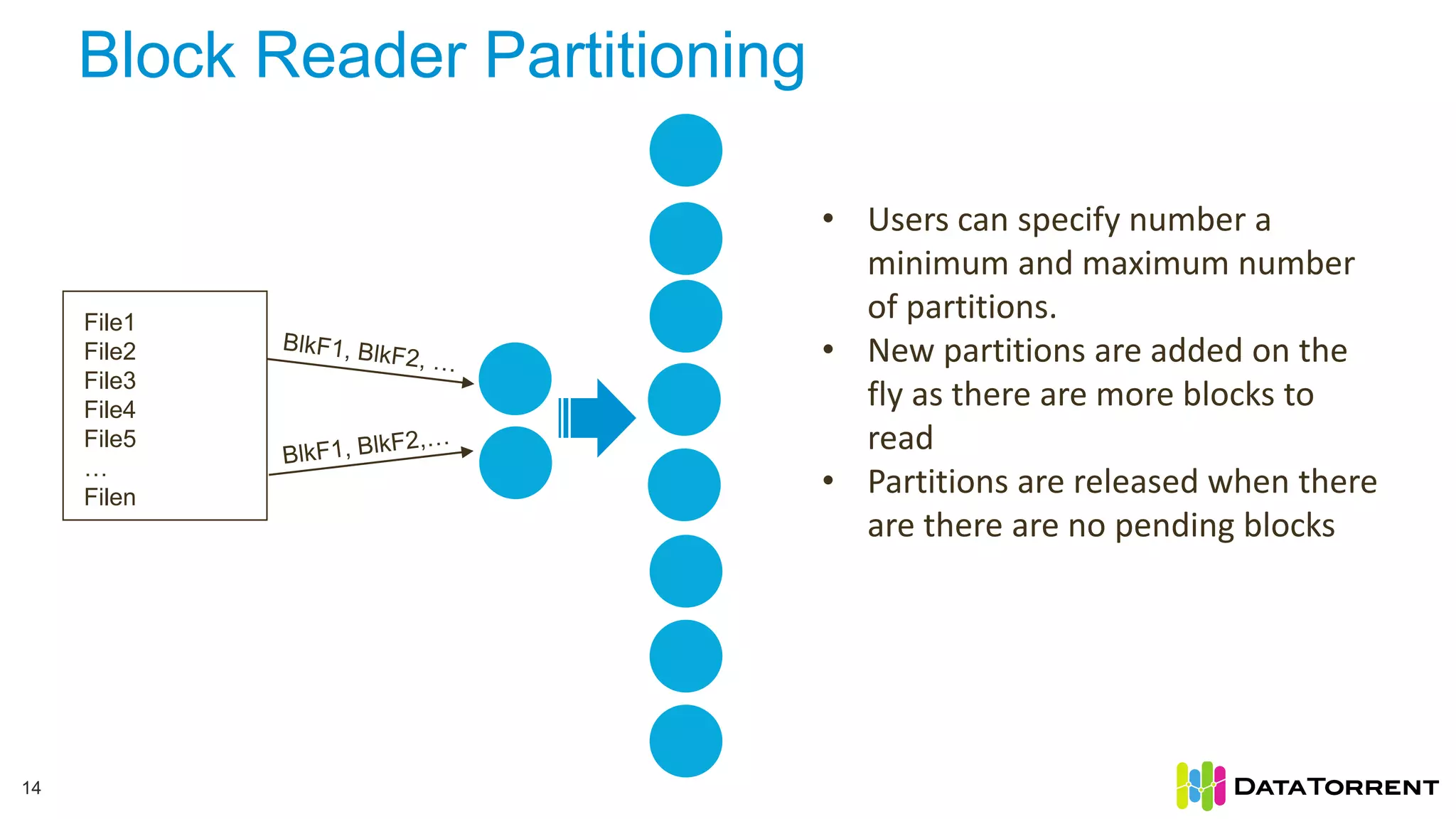




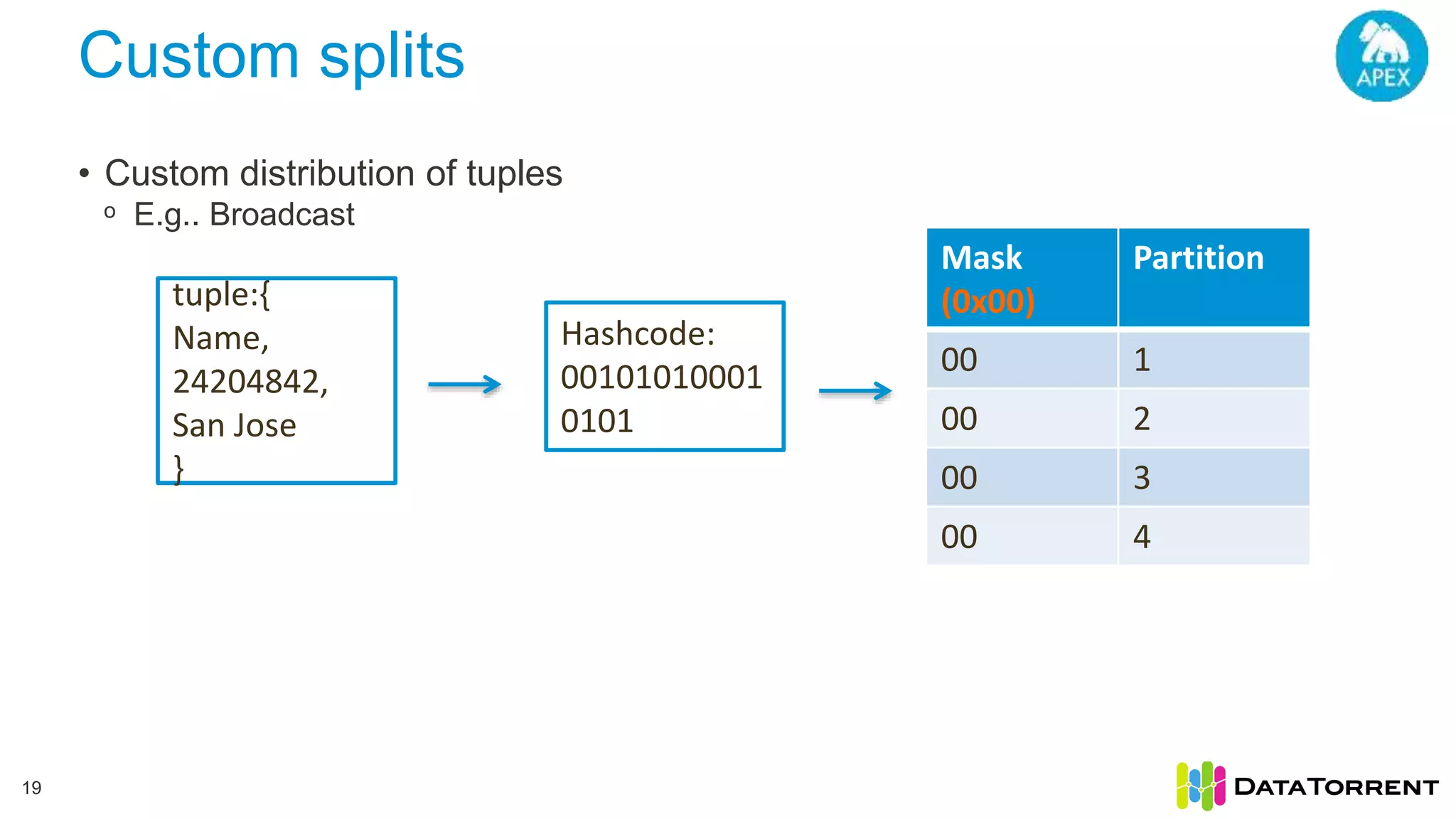



The document discusses smart partitioning with Apache Apex, an in-memory stream processing platform designed for high throughput and low latency data processing from various sources. It highlights features such as dynamic partitioning, support for diverse partitioning schemes, and the ability to scale applications while ensuring fault tolerance and reliability. Additionally, it details the architecture and development model, including partitioning mechanisms that enable efficient data handling and processing.























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










