-
-
Jarvis_FINAL

💡 Inspiration
We are living in the golden age of LLMs, yet most of them are trapped inside a browser tab or a chatbox. We asked ourselves: "Why can our AI write Shakespeare, but can't see what's on my screen or organize my files without a complex integration?"
The inspiration for Jarvis_FINAL came from the desire to break the "fourth wall" between the AI and the Operating System. We wanted to move from Generative AI (which creates text) to Agentic AI (which executes actions). We envisioned an entity that lives natively in the Linux environment, sees what I see, hears what I hear, and acts as a true co-pilot, not just a consultant.
🤖 What it does
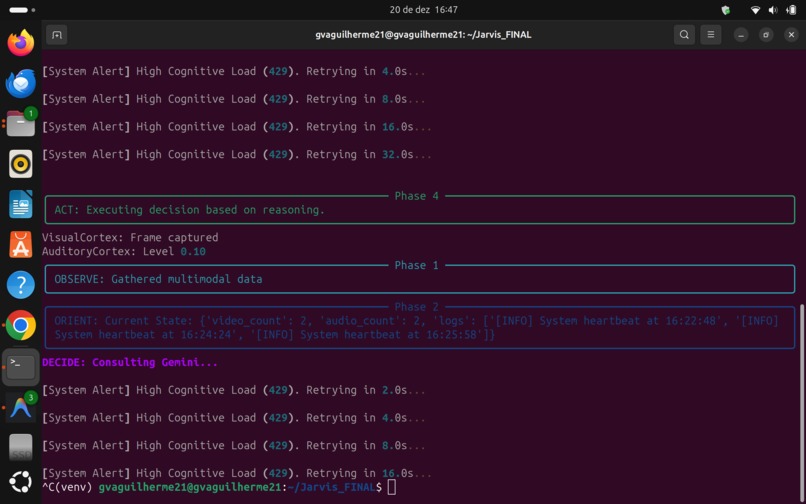
Jarvis is a local, autonomous agent built on the OODA Loop military doctrine (Observe, Orient, Decide, Act). Unlike standard assistants that wait for a prompt, Jarvis runs in a continuous asynchronous loop:
- Observe: It constantly ingests multimodal data (Screenshots of the desktop, Microphone audio, System Logs) using local hardware hooks.
- Orient: It uses Gemini 3's Multimodal capabilities to understand the context. It doesn't just read text; it sees error messages on the terminal or hears a command.
- Decide: Leveraging Gemini 3's reasoning capabilities, it formulates a plan. It decides if it needs to act or just keep watching.
- Act: It executes code, runs terminal commands, or manipulates files directly on the host machine.
⚙️ How we built it
The project is a hybrid of high-performance local computing and cloud-based reasoning, running on an Alienware M18 (i9 + RTX 4070) with Native Linux Ubuntu.
- The Core: Written in Python using
asyncioto ensure the "sensory" threads (Vision/Audio) never block the "cognitive" thread (Gemini). - The Brain: We utilized the Google GenAI SDK to interface with Gemini 3. We specifically leverage the model's large context window to maintain a "Short-Term Memory" of the session logs.
- The Body: We used standard Linux libraries (
cv2for vision,sounddevicefor audio,subprocessfor action) to give the AI hands and eyes. - The Interface: A rich terminal UI (using the
richlibrary) that visualizes the agent's thought process in real-time.
🧠 Gemini 3 Integration
Gemini 3 is not just a backend; it is the Cognitive Core of the architecture.
- We use Gemini 3 Pro for complex reasoning (The "Decide" phase), passing it a structured context of the system's state.
- We rely on its Multimodal nature to interpret screenshots and logs simultaneously, reducing the need for complex OCR or pre-processing code. The model simply "looks" at the problem.
🚧 Challenges we ran into
The biggest challenge was Latency vs. Concurrency.
- Problem: When the agent sends a request to the LLM, the local script would typically "freeze," making the agent blind and deaf for a few seconds.
- Solution: We engineered a robust asynchronous architecture. The
SensoryInputManagerruns on a separate loop from theCognitiveCore. This allows Jarvis to continue "recording" the environment even while waiting for Gemini's response, ensuring no context is lost.
🏆 Accomplishments that we're proud of
- Building a truly autonomous loop that doesn't crash on the first error.
- Implementing a Self-Correction mechanism: If Jarvis tries a bash command that fails, it feeds the
stderroutput back into Gemini 3, which analyzes the error and suggests a fix in the next iteration. - Running this natively on Linux, proving that high-end consumer hardware + Gemini API is a viable path for AGI development.
🚀 What's next for Jarvis_FINAL
- Long-Term Memory: Integrating a Vector Database (ChromaDB) so Jarvis remembers preferences across reboots.
- Active Computer Vision: Giving Jarvis control over the mouse and keyboard to interact with GUI applications, not just the terminal.
- Voice Synthesis: Making Jarvis speak back with low-latency TTS.


Log in or sign up for Devpost to join the conversation.