Thomas Wimmer1,2, Prune Truong3, Marie-Julie Rakotosaona3, Michael Oechsle3, Federico Tombari3,4, Bernt Schiele1 Jan Eric Lenssen1
1Max Planck Institute for Informatics, 2ETH Zurich, 3Google, 4TU Munich
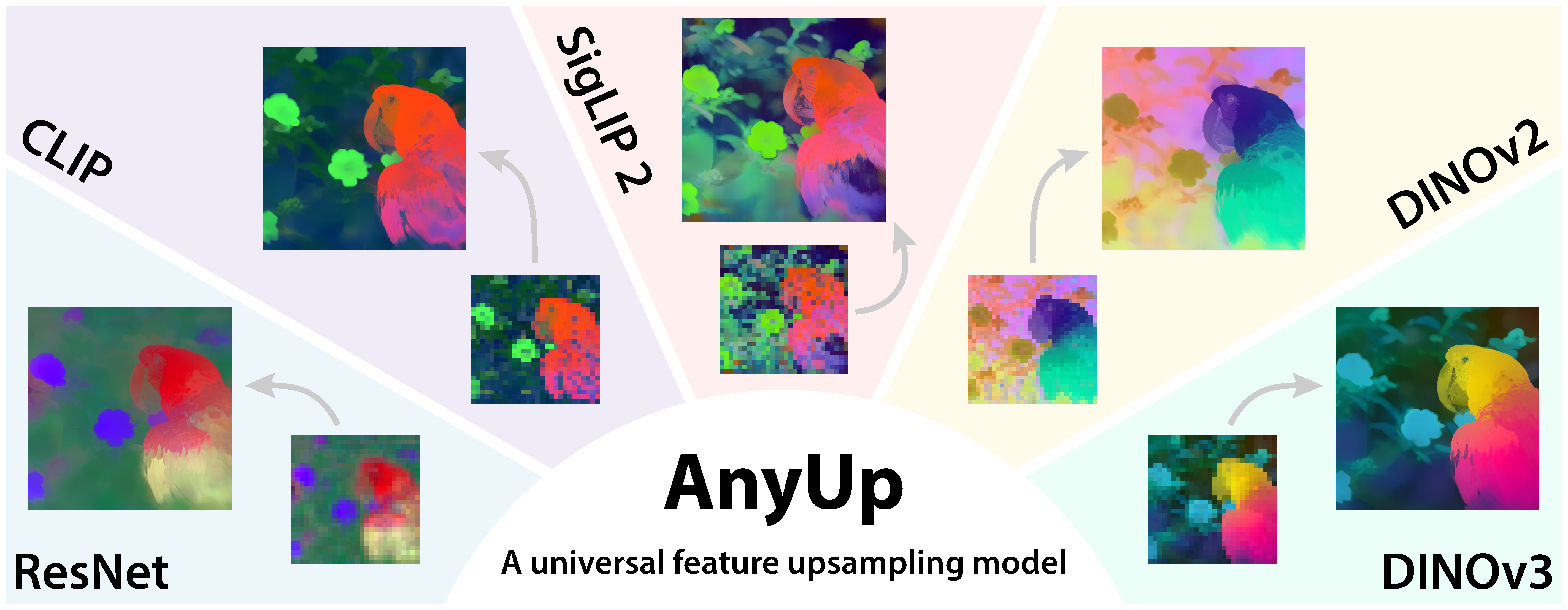
Abstract:
We introduce AnyUp, a method for feature upsampling that can be applied to any vision feature at any resolution, without encoder-specific training. Existing learning-based upsamplers for features like DINO or CLIP need to be re-trained for every feature extractor and thus do not generalize to different feature types at inference time. In this work, we propose an inference-time feature-agnostic upsampling architecture to alleviate this limitation and improve upsampling quality. In our experiments, AnyUp sets a new state of the art for upsampled features, generalizes to different feature types, and preserves feature semantics while being efficient and easy to apply to a wide range of downstream tasks.
🔔 News:
[11/25] We added a more efficient (both memory and speed-wise) NATTEN-based version of the
window attention module used in AnyUp. You can load the new model by specifying use_natten=True when loading the model
from torch.hub. Please note, that this model variant uses slightly different windows than the original AnyUp model,
which was used for all experiments in the paper. If you want to use it in your project, you have to install NATTEN in
addition to PyTorch. Follow the official install instructions for your CUDA version.
[11/25] We further added multi-backbone training to our codebase, which allows training a single AnyUp model
with multiple different feature extractors. This improves generalization to unseen backbones at inference time.
To use this feature, please load the pre-trained model with torch.hub.load('wimmerth/anyup', 'anyup_multi_backbone').
[11/25] We added installation of anyup as package for local development. Please see the instructions for
installation below.
Upsample features from any model, at any layer without having to retrain the upsampler. It's as easy as this:
import torch
# high-resolution image (B, 3, H, W)
hr_image = ...
# low-resolution features (B, C, h, w)
lr_features = ...
# load the AnyUp upsampler model (here we use the NATTEN-based version trained on multiple backbones)
upsampler = torch.hub.load('wimmerth/anyup', 'anyup_multi_backbone', use_natten=True)
# upsampled high-resolution features (B, C, H, W)
hr_features = upsampler(hr_image, lr_features)Notes:
- The
hr_imageshould be normalized to ImageNet mean and std as usual for most vision encoders. - The
lr_featurescan be any features from any encoder, e.g. DINO, CLIP, or ResNet.
The hr_features will have the same spatial resolution as the hr_image by default.
If you want a different output resolution, you can specify it with the output_size argument:
# upsampled features with custom output size (B, C, H', W')
hr_features = upsampler(hr_image, lr_features, output_size=(H_prime, W_prime))If you have limited compute resources and run into OOM issues when upsampling to high resolutions, you can use the
q_chunk_size argument to trade off speed for memory:
# upsampled features using chunking to save memory (B, C, H, W)
hr_features = upsampler(hr_image, lr_features, q_chunk_size=10)If you are interested in the attention that is used by AnyUp to upsample the features, we included an optional
visualization thereof in the forward pass (only available if use_natten=False):
# matplotlib must be installed to use this feature
# upsampled features and display attention map visualization (B, C, H, W)
hr_features = upsampler(hr_image, lr_features, vis_attn=True)To use the model proposed in the original AnyUp paper (without NATTEN and trained on a single backbone, DINOv2 ViT-S), load it with
upsampler = torch.hub.load('wimmerth/anyup', 'anyup')Installation
Install anyup as package for local development:
micromamba create -n anyup python=3.12 -y
micromamba activate anyup
pip install uv
# Install the correct PyTorch version for your CUDA setup, e.g. for CUDA 11.8 and PyTorch=2.9.0:
uv pip install torch==2.9.0 torchvision==0.24.0 --index-url https://download.pytorch.org/whl/cu128
# Install the correct NATTEN version for your CUDA / PyTorch setup, e.g. for CUDA 11.8 and PyTorch=2.9.0:
uv pip install natten==0.21.1+torch290cu128 -f https://whl.natten.org
# Install the remaining dependencies and anyup as package (call from the root of the repository):
uv pip install -e .Install the required dependencies for training without installing anyup as package:
micromamba create -n anyup python=3.12 -y
micromamba activate anyup
pip install uv
# Install the correct PyTorch version for your CUDA setup, e.g. for CUDA 11.8 and PyTorch=2.9.0:
uv pip install torch==2.9.0 torchvision==0.24.0 --index-url https://download.pytorch.org/whl/cu128
# Install the correct NATTEN version for your CUDA / PyTorch setup, e.g. for CUDA 11.8 and PyTorch=2.9.0:
uv pip install natten==0.21.1+torch290cu128 -f https://whl.natten.org
# Install the remaining dependencies needed for training:
uv pip install einops matplotlib numpy timm plotly tensorboard hydra-core rich scikit-learnTraining your own AnyUp model
If you want to train your own AnyUp model on custom data or with different hyperparameters, you can do so by running
the train.py script. We use hydra for configuration management, so you can easily modify
hyperparameters in the corresponding config files.
We trained our model on the ImageNet dataset, which you will have to download and put into ./data/imagenet before
running the training script. We further use information on the image resolutions in ImageNet, which can be created
using the comput_sizes_index.py script. You can also download this file directly from the releases and put it into
./data/cache/train.sizes.tsv.
Evaluation followed the protocols of JAFAR for semantic segmentation and Probe3D for surface normal and depth estimation. Note that we applied a small fix to the probe training in JAFAR (updating LR scheduling to per epoch instead of per iteration). Therefore, we re-ran all experiments with baselines to ensure a fair comparison.
Acknowledgements: We built our implementation on top of the JAFAR repository and thank the authors for open-sourcing their code. Other note-worthy open-source repositories include: LoftUp, FeatUp, and Probe3D.
If you find our work useful in your research, please cite it as:
@article{wimmer2025anyup,
title={AnyUp: Universal Feature Upsampling},
author={Wimmer, Thomas and Truong, Prune and Rakotosaona, Marie-Julie and Oechsle, Michael and Tombari, Federico and Schiele, Bernt and Lenssen, Jan Eric},
journal={arXiv preprint arXiv:2510.12764},
year={2025}
}