Using GPT-5.2
GPT-5.2 is our best general-purpose model, part of the GPT-5 flagship model family. Our most intelligent model yet for both general and agentic tasks, GPT-5.2 shows improvements over the previous GPT-5.1 in:
- General intelligence
- Instruction following
- Accuracy and token efficiency
- Multimodality—especially vision
- Code generation—especially front-end UI creation
- Tool calling and context management in the API
- Spreadsheet understanding and creation
Unlike the previous GPT-5.1 model, GPT-5.2 has new features for managing what the model "knows" and "remembers to improve accuracy.
This guide covers key features of the GPT-5 model family and how to get the most out of GPT-5.2.
Explore coding examples
Click through a few demo applications generated entirely with a single prompt, without writing any code by hand. Note that these examples were either generated by GPT-5.2 or our previous flagship model, GPT-5.
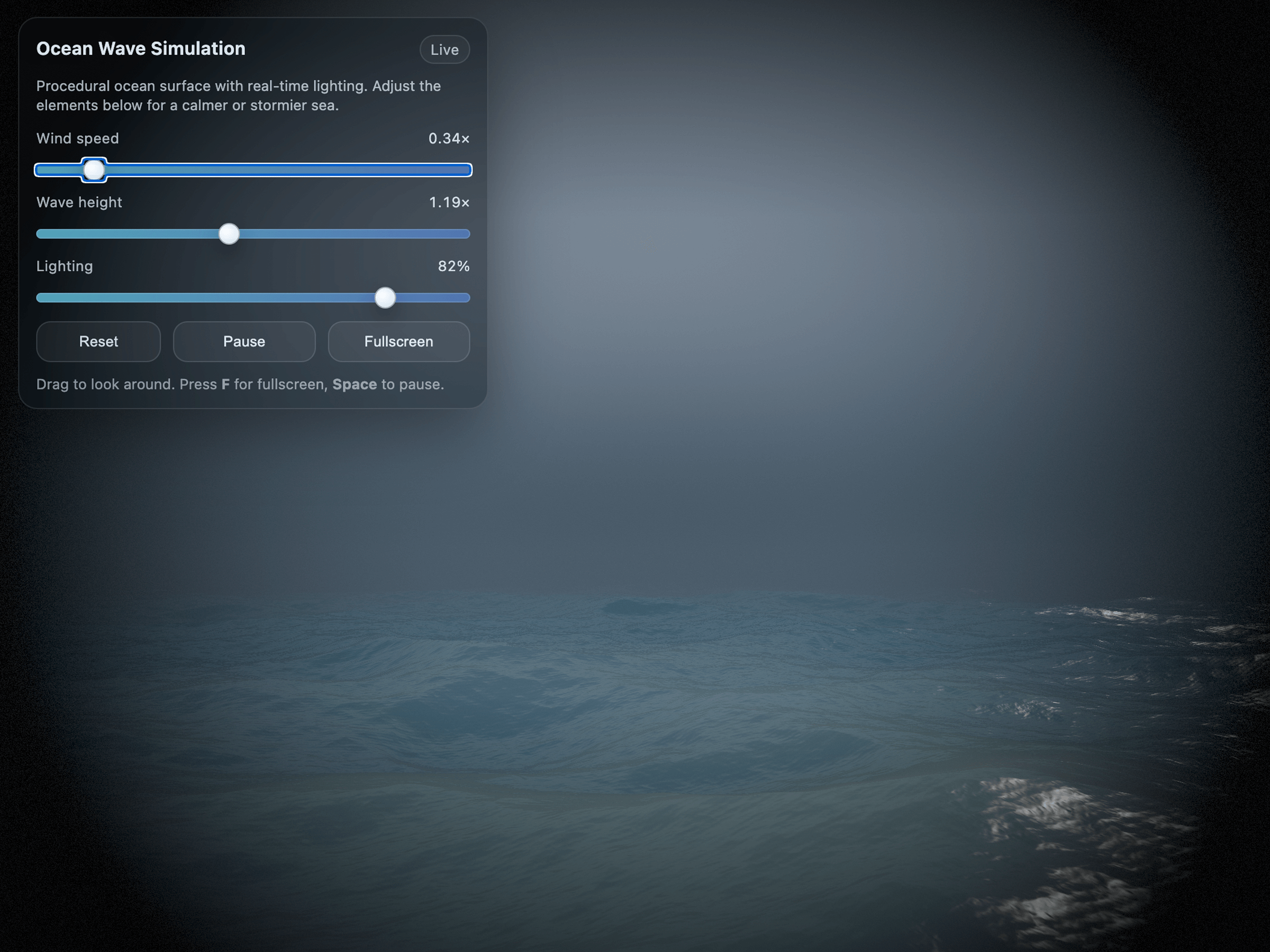

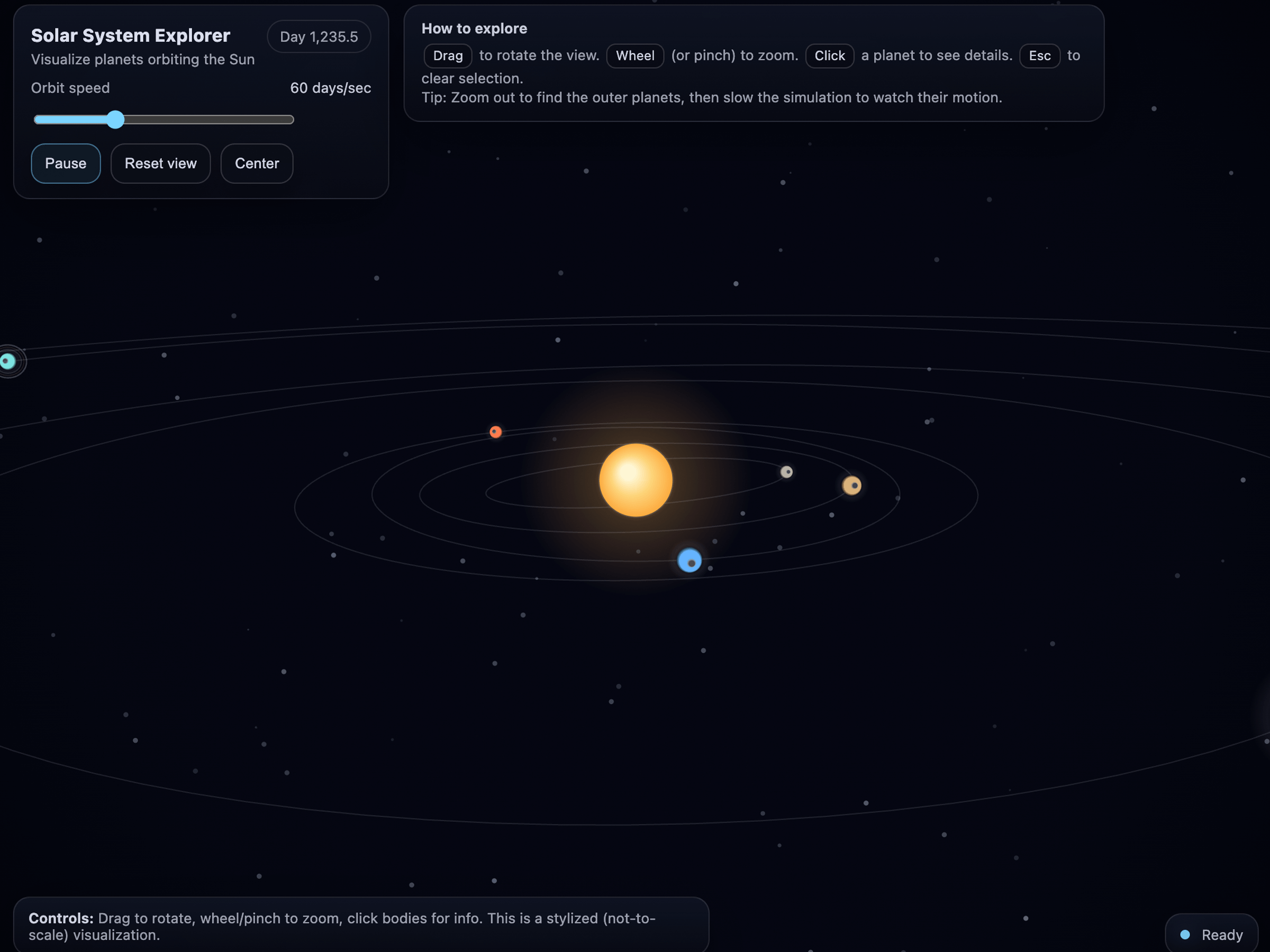
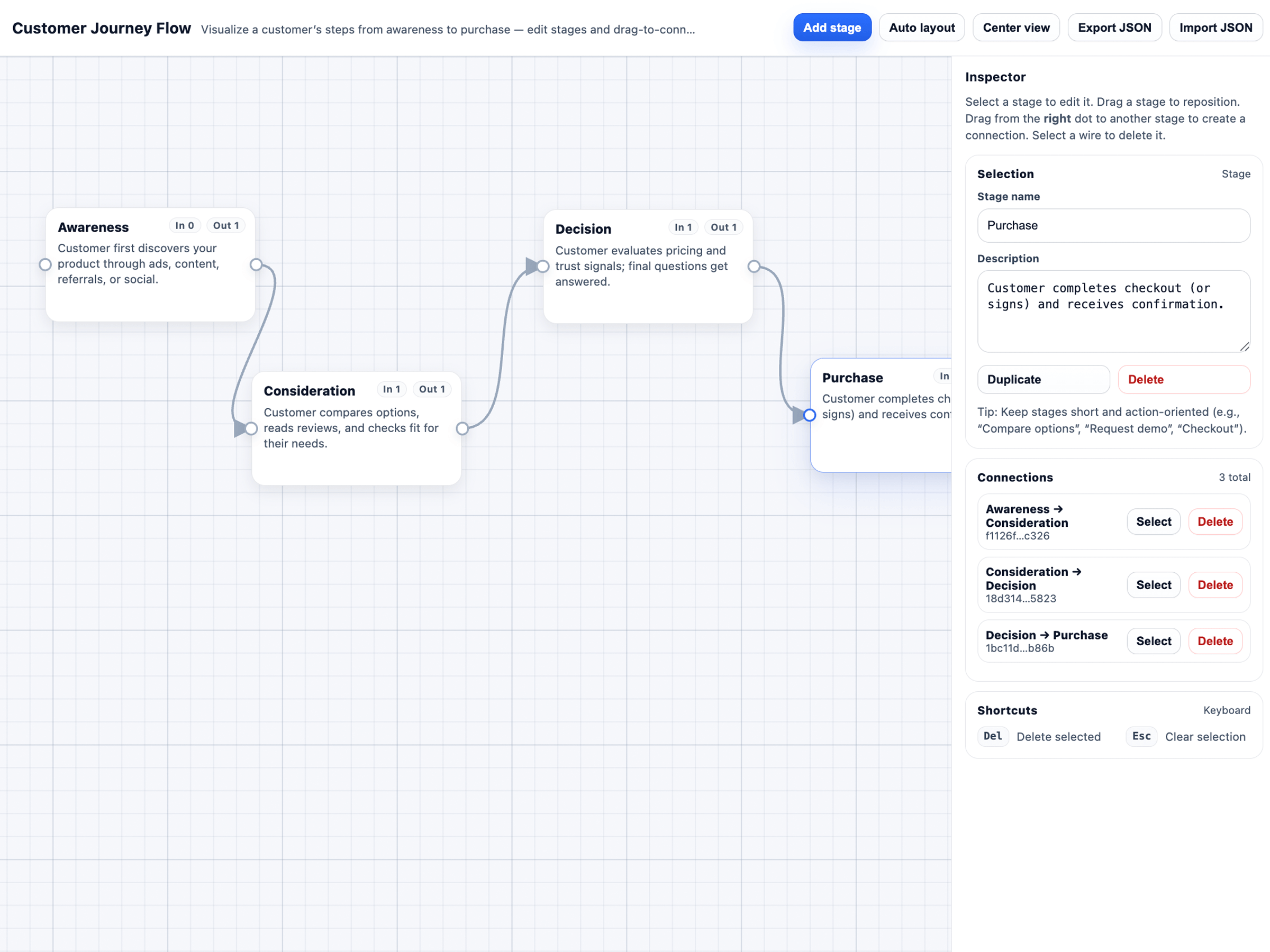
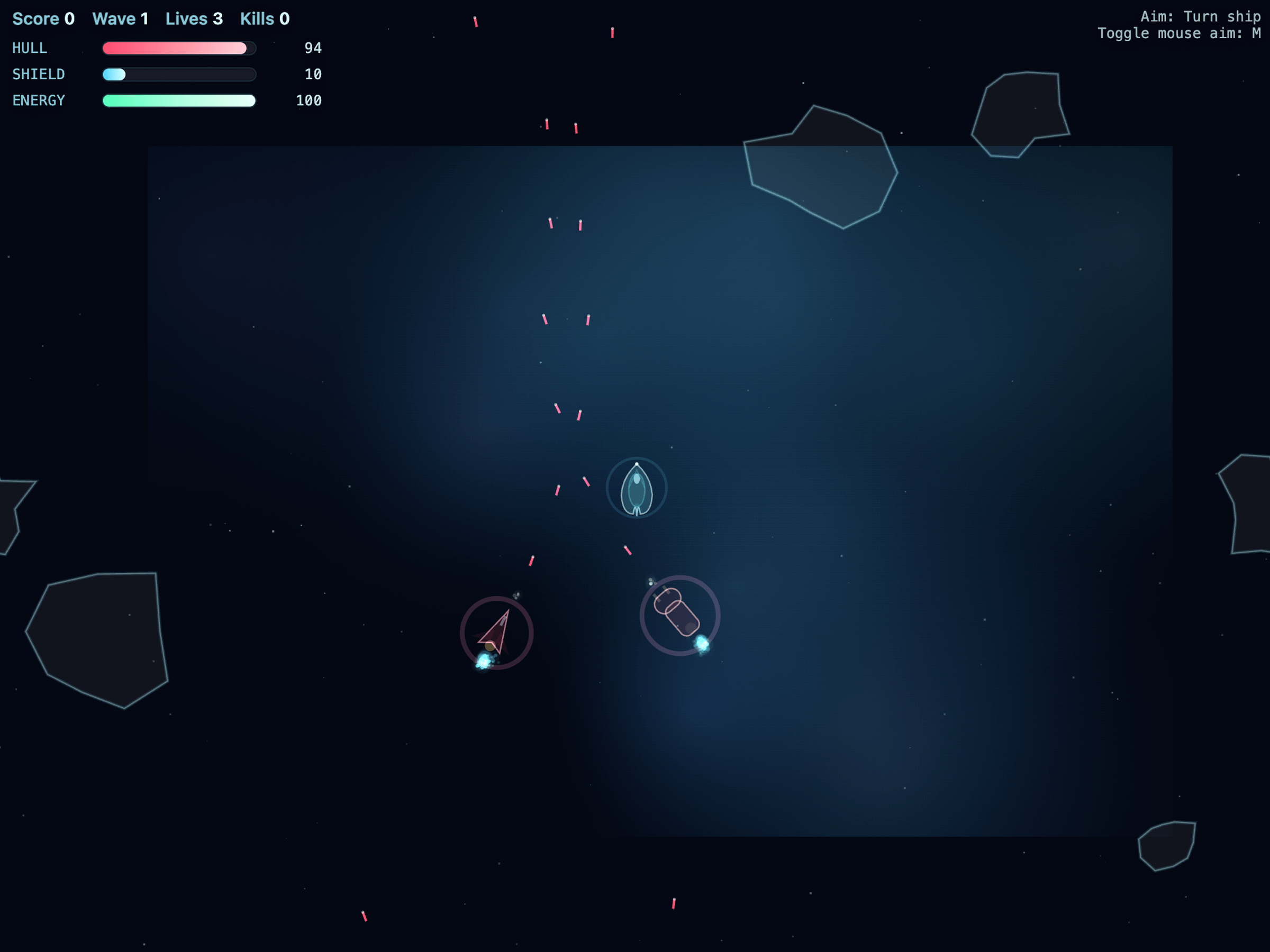
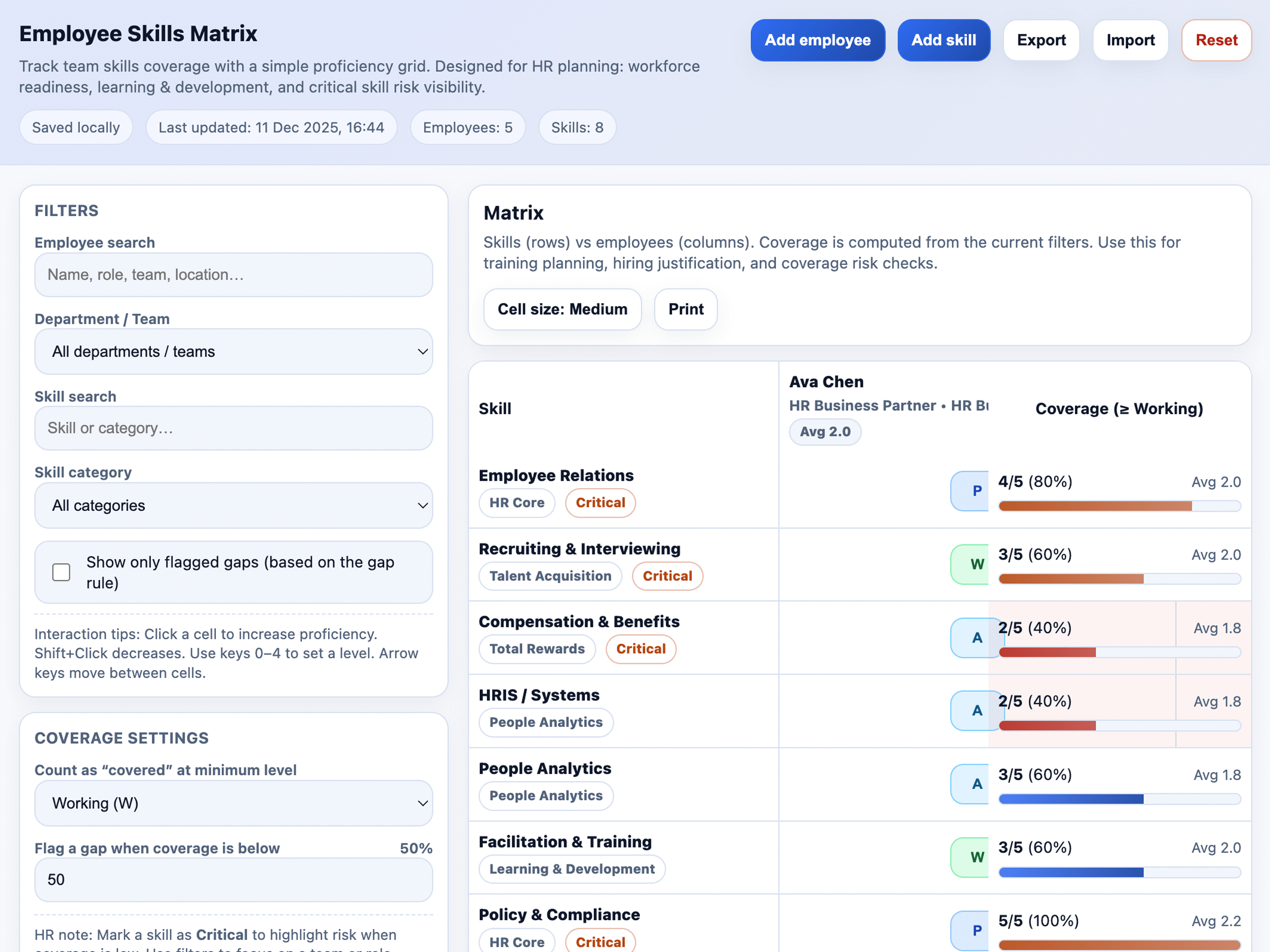
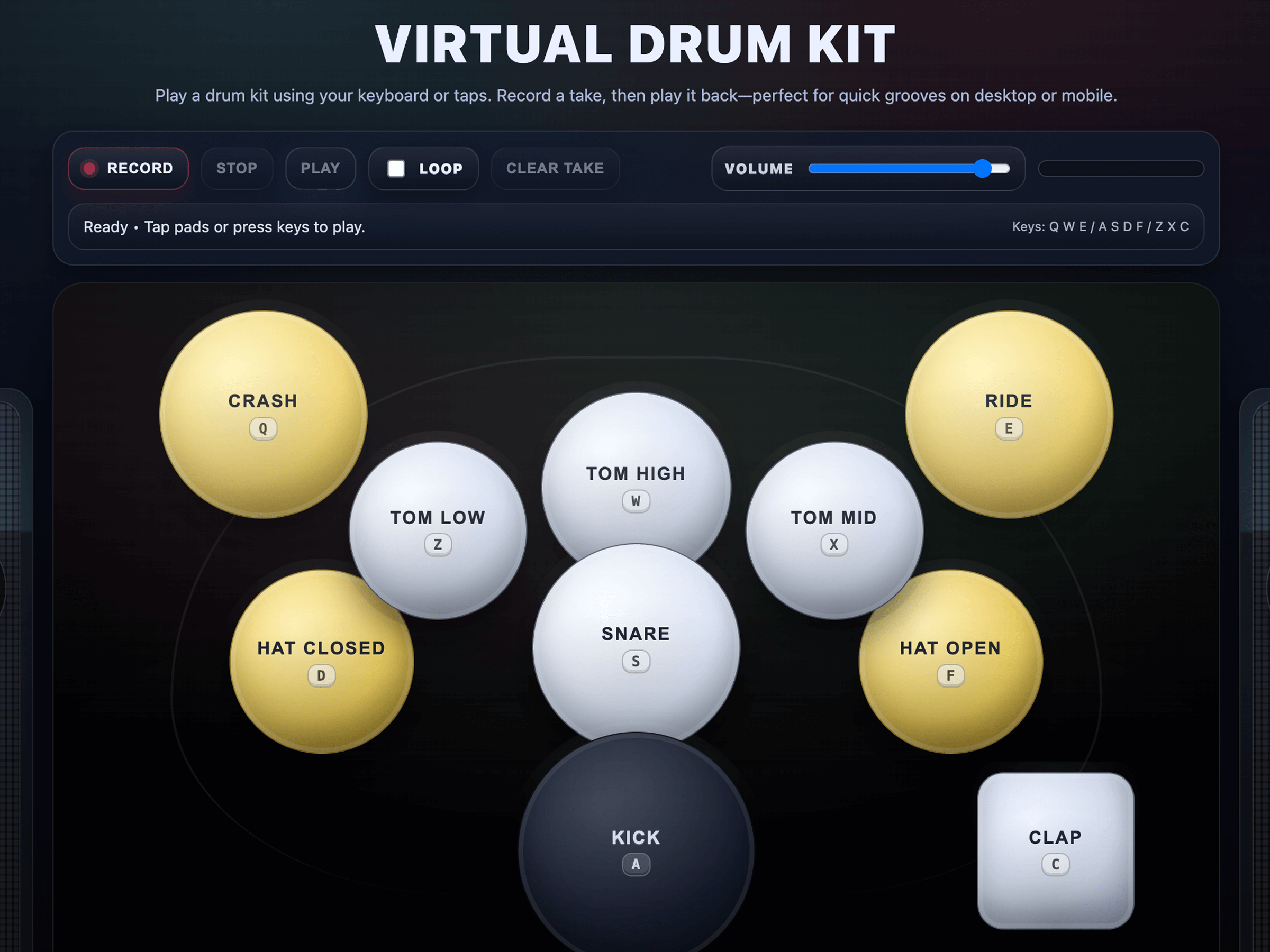
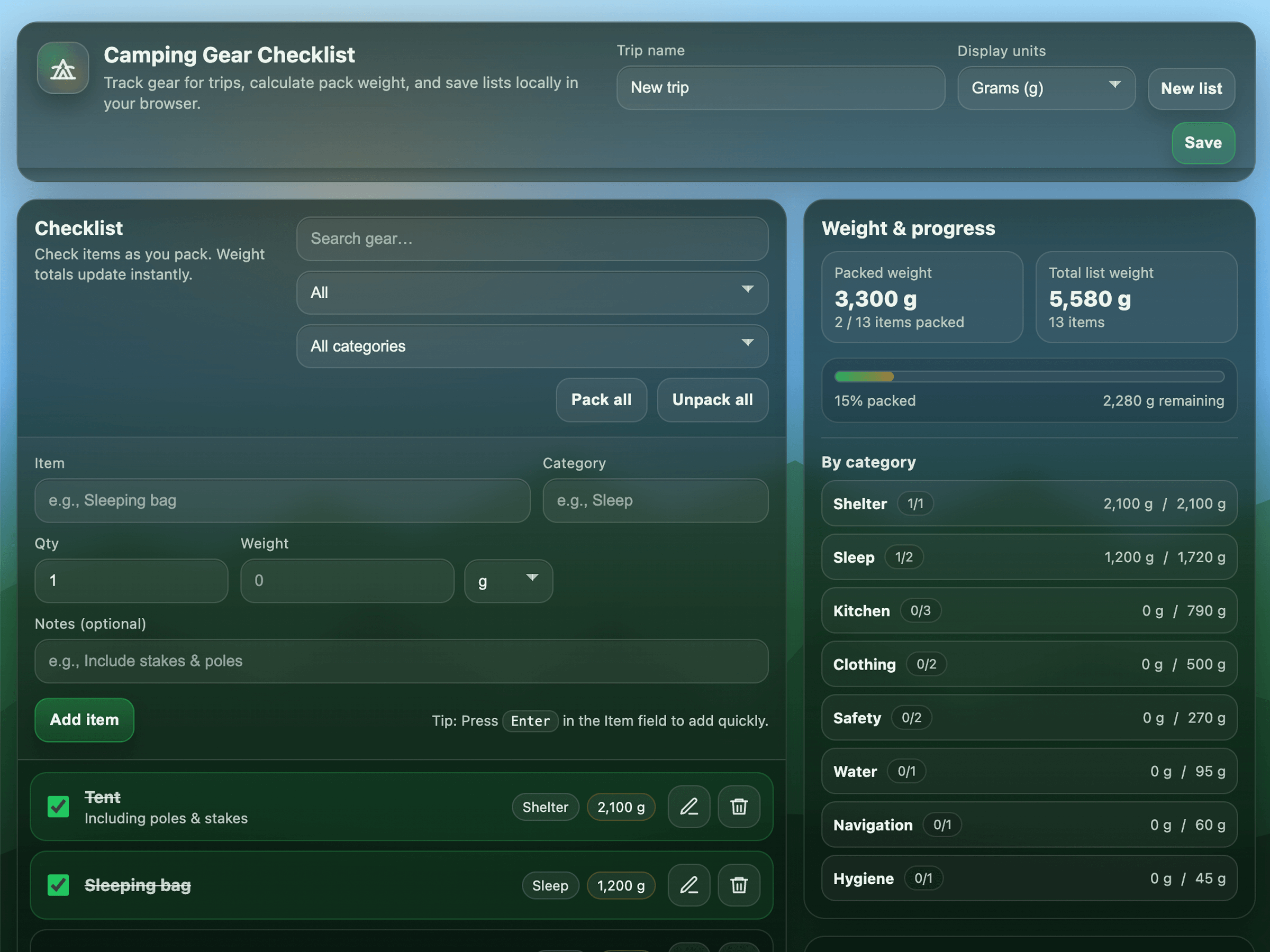
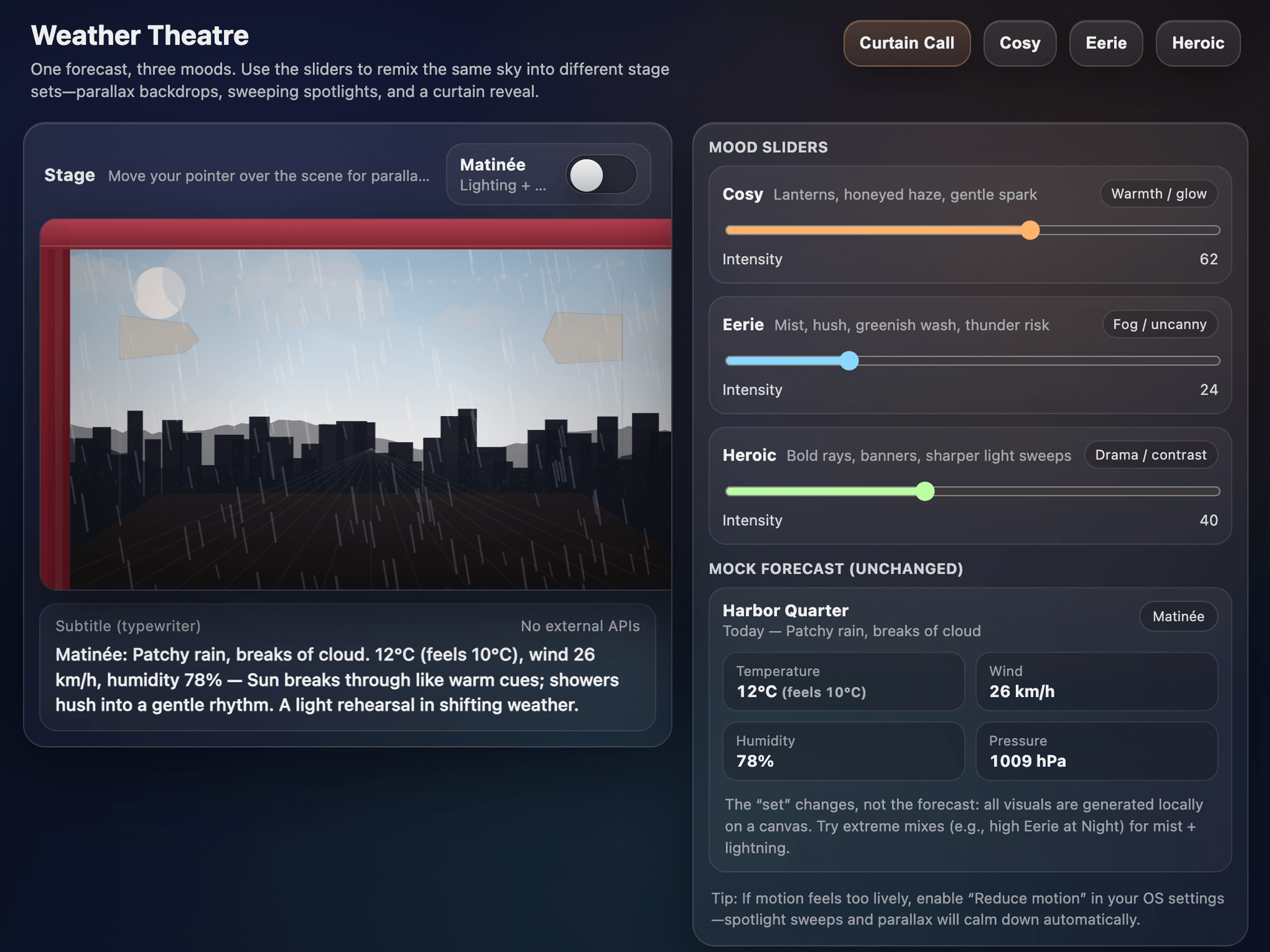

Meet the models
There are three new models. In general, gpt-5.2 is best for your most complex tasks that require broad world knowledge. It replaces the previous gpt-5.1 model. The model powering ChatGPT is gpt-5.2-chat-latest. Third, gpt-5.2-pro uses more compute to think harder and provide consistently better answers.
For a smaller model, use gpt-5-mini.
To help you pick the model that best fits your use case, consider these tradeoffs:
| Variant | Best for |
|---|---|
gpt-5.2 | Complex reasoning, broad world knowledge, and code-heavy or multi-step agentic tasks |
gpt-5.2-pro | Tough problems that may take longer to solve but require harder thinking |
gpt-5.1-codex-max | Companies building interactive coding products; full spectrum of coding tasks |
gpt-5-mini | Cost-optimized reasoning and chat; balances speed, cost, and capability |
gpt-5-nano | High-throughput tasks, especially simple instruction-following or classification |
New features in GPT-5.2
Just like GPT-5.1, the new GPT-5.2 has API features like custom tools, parameters to control verbosity and reasoning, and an allowed tools list. What's new in 5.2 is a new xhigh reasoning effort level, concise reasoning summaries, and new context management using compaction.
This guide walks through some of the key features of the GPT-5 model family and how to get the most out of 5.2 in particular.
For coding tasks, GPT-5.1-Codex-Max is a faster, more capable, and more token-efficient coding variant, with an xhigh reasoning option. Its new built-in compaction capability provides native long-running task support.
Lower reasoning effort
The reasoning.effort parameter controls how many reasoning tokens the model generates before producing a response. Earlier reasoning models like o3 supported only low, medium, and high: low favored speed and fewer tokens, while high favored more thorough reasoning.
With GPT-5.2, the lowest setting is none to provide lower-latency interactions. This is the default setting in GPT-5.2. If you need more thinking, slowly increase to medium and experiment with results.
With reasoning effort set to none, prompting is important. To improve the model's reasoning quality, even with the default settings, encourage it to “think” or outline its steps before answering.
1
2
3
4
5
6
7
8
9
10
11
12
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.1",
input="How much gold would it take to coat the Statue of Liberty in a 1mm layer?",
reasoning={
"effort": "none"
}
)
print(response)Verbosity
Verbosity determines how many output tokens are generated. Lowering the number of tokens reduces overall latency. While the model's reasoning approach stays mostly the same, the model finds ways to answer more concisely—which can either improve or diminish answer quality, depending on your use case. Here are some scenarios for both ends of the verbosity spectrum:
- High verbosity: Use when you need the model to provide thorough explanations of documents or perform extensive code refactoring.
- Low verbosity: Best for situations where you want concise answers or simple code generation, such as SQL queries.
GPT-5 made this option configurable as one of high, medium, or low. With GPT-5.2, verbosity remains configurable and defaults to medium.
When generating code with GPT-5.2, medium and high verbosity levels yield longer, more structured code with inline explanations, while low verbosity produces shorter, more concise code with minimal commentary.
1
2
3
4
5
6
7
8
9
10
11
12
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
input="What is the answer to the ultimate question of life, the universe, and everything?",
text={
"verbosity": "low"
}
)
print(response)You can still steer verbosity through prompting after setting it to low in the API. The verbosity parameter defines a general token range at the system prompt level, but the actual output is flexible to both developer and user prompts within that range.
Using tools with GPT-5.2
GPT-5.2 has been post-trained on specific tools. See the tools docs for more specific guidance.
The apply patch tool
The apply_patch tool lets GPT-5.2 create, update, and delete files in your codebase using structured diffs. Instead of just suggesting edits, the model emits patch operations that your application applies and then reports back on, enabling iterative, multistep code editing workflows. Read the docs.
Under the hood, this implementation uses a freeform function call rather than a JSON format. In testing, the named function decreased apply_patch failure rates by 35%.
Shell tool
Local shell is supported in GPT-5.2. The shell tool allows the model to interact with your local computer through a controlled command-line interface. Read the docs to learn more.
Custom tools
When the GPT-5 model family launched, we introduced a new capability called custom tools, which lets models send any raw text as tool call input but still constrain outputs if desired. This tool behavior remains true in GPT-5.2.
Learn about custom tools in the function calling guide.
Freeform inputs
Define your tool with type: custom to enable models to send plaintext inputs directly to your tools, rather than being limited to structured JSON. The model can send any raw text—code, SQL queries, shell commands, configuration files, or long-form prose—directly to your tool.
1
2
3
4
5
{
"type": "custom",
"name": "code_exec",
"description": "Executes arbitrary python code",
}Constraining outputs
GPT-5.2 supports context-free grammars (CFGs) for custom tools, letting you provide a Lark grammar to constrain outputs to a specific syntax or DSL. Attaching a CFG (e.g., a SQL or DSL grammar) ensures the assistant's text matches your grammar.
This enables precise, constrained tool calls or structured responses and lets you enforce strict syntactic or domain-specific formats directly in GPT-5.2's function calling, improving control and reliability for complex or constrained domains.
Best practices for custom tools
- Write concise, explicit tool descriptions. The model chooses what to send based on your description; state clearly if you want it to always call the tool.
- Validate outputs on the server side. Freeform strings are powerful but require safeguards against injection or unsafe commands.
Allowed tools
The allowed_tools parameter under tool_choice lets you pass N tool definitions but restrict the model to only M (< N) of them. List your full toolkit in tools, and then use an allowed_tools block to name the subset and specify a mode—either auto (the model may pick any of those) or required (the model must invoke one).
Learn about the allowed tools option in the function calling guide.
By separating all possible tools from the subset that can be used now, you gain greater safety, predictability, and improved prompt caching. You also avoid brittle prompt engineering, such as hard-coded call order. GPT-5.2 dynamically invokes or requires specific functions mid-conversation while reducing the risk of unintended tool usage over long contexts.
| Standard Tools | Allowed Tools | |
|---|---|---|
| Model's universe | All tools listed under "tools": […] | Only the subset under "tools": […] in tool_choice |
| Tool invocation | Model may or may not call any tool | Model restricted to (or required to call) chosen tools |
| Purpose | Declare available capabilities | Constrain which capabilities are actually used |
1
2
3
4
5
6
7
8
9
"tool_choice": {
"type": "allowed_tools",
"mode": "auto",
"tools": [
{ "type": "function", "name": "get_weather" },
{ "type": "function", "name": "search_docs" }
]
}
}'For a more detailed overview of all of these new features, see the accompanying cookbook.
Preambles
Preambles are brief, user-visible explanations that GPT-5.2 generates before invoking any tool or function, outlining its intent or plan (e.g., “why I'm calling this tool”). They appear after the chain-of-thought and before the actual tool call, providing transparency into the model's reasoning and enhancing debuggability, user confidence, and fine-grained steerability.
By letting GPT-5.2 “think out loud” before each tool call, preambles boost tool-calling accuracy (and overall task success) without bloating reasoning overhead. To enable preambles, add a system or developer instruction—for example: “Before you call a tool, explain why you are calling it.” GPT-5.2 prepends a concise rationale to each specified tool call. The model may also output multiple messages between tool calls, which can enhance the interaction experience—particularly for minimal reasoning or latency-sensitive use cases.
For more on using preambles, see the GPT-5 prompting cookbook.
Migration guidance
GPT-5.2 is our best model yet, and it works best with the Responses API, which supports for passing chain of thought (CoT) between turns. Read below to migrate from your current model or API.
Migrating from other models to GPT-5.2
While the model should be close to a drop-in replacement for GPT-5.1, there are a few key changes to call out. See the GPT-5.2 prompting guide for specific updates to make in your prompts.
Using GPT-5 models with the Responses API provides improved intelligence because of the API's design. The Responses API can pass the previous turn's CoT to the model. This leads to fewer generated reasoning tokens, higher cache hit rates, and less latency. To learn more, see an in-depth guide on the benefits of the Responses API.
When migrating to GPT-5.2 from an older OpenAI model, start by experimenting with reasoning levels and prompting strategies. Based on our testing, we recommend using our prompt optimizer—which automatically updates your prompts for GPT-5.2 based on our best practices—and following this model-specific guidance:
- gpt-5.1:
gpt-5.2with default settings is meant to be a drop-in replacement. - o3:
gpt-5.2withmediumorhighreasoning. Start withmediumreasoning with prompt tuning, then increase tohighif you aren't getting the results you want. - gpt-4.1:
gpt-5.2withnonereasoning. Start withnoneand tune your prompts; increase if you need better performance. - o4-mini or gpt-4.1-mini:
gpt-5-miniwith prompt tuning is a great replacement. - gpt-4.1-nano:
gpt-5-nanowith prompt tuning is a great replacement.
GPT-5.2 parameter compatibility
The following parameters are only supported when using GPT-5.2 with reasoning effort set to none:
temperaturetop_plogprobs
Requests to GPT-5.2 or GPT-5.1 with any other reasoning effort setting, or to older GPT-5 models (e.g., gpt-5, gpt-5-mini, gpt-5-nano) that include these fields will raise an error.
To achieve similar results with reasoning effort set higher, or with another GPT-5 family model, try these alternative parameters:
- Reasoning depth:
reasoning: { effort: "none" | "low" | "medium" | "high" | "xhigh" } - Output verbosity:
text: { verbosity: "low" | "medium" | "high" } - Output length:
max_output_tokens
Migrating from Chat Completions to Responses API
The biggest difference, and main reason to migrate from Chat Completions to the Responses API for GPT-5.2, is support for passing chain of thought (CoT) between turns. See a full comparison of the APIs.
Passing CoT exists only in the Responses API, and we've seen improved intelligence, fewer generated reasoning tokens, higher cache hit rates, and lower latency as a result of doing so. Most other parameters remain at parity, though the formatting is different. Here's how new parameters are handled differently between Chat Completions and the Responses API:
Reasoning effort
1
2
3
4
5
6
7
8
9
10
11
curl --request POST \
--url https://api.openai.com/v1/responses \
--header "Authorization: Bearer $OPENAI_API_KEY" \
--header 'Content-type: application/json' \
--data '{
"model": "gpt-5.2",
"input": "How much gold would it take to coat the Statue of Liberty in a 1mm layer?",
"reasoning": {
"effort": "none"
}
}'1
2
3
4
5
6
7
8
9
10
11
12
13
14
curl --request POST \
--url https://api.openai.com/v1/chat/completions \
--header "Authorization: Bearer $OPENAI_API_KEY" \
--header 'Content-type: application/json' \
--data '{
"model": "gpt-5.2",
"messages": [
{
"role": "user",
"content": "How much gold would it take to coat the Statue of Liberty in a 1mm layer?"
}
],
"reasoning_effort": "none"
}'Verbosity
1
2
3
4
5
6
7
8
9
10
11
curl --request POST \
--url https://api.openai.com/v1/responses \
--header "Authorization: Bearer $OPENAI_API_KEY" \
--header 'Content-type: application/json' \
--data '{
"model": "gpt-5.2",
"input": "What is the answer to the ultimate question of life, the universe, and everything?",
"text": {
"verbosity": "low"
}
}'1
2
3
4
5
6
7
8
9
10
11
curl --request POST \
--url https://api.openai.com/v1/chat/completions \
--header "Authorization: Bearer $OPENAI_API_KEY" \
--header 'Content-type: application/json' \
--data '{
"model": "gpt-5.2",
"messages": [
{ "role": "user", "content": "What is the answer to the ultimate question of life, the universe, and everything?" }
],
"verbosity": "low"
}'Custom tools
1
2
3
4
5
6
7
8
9
10
11
curl --request POST --url https://api.openai.com/v1/responses --header "Authorization: Bearer $OPENAI_API_KEY" --header 'Content-type: application/json' --data '{
"model": "gpt-5.2",
"input": "Use the code_exec tool to calculate the area of a circle with radius equal to the number of r letters in blueberry",
"tools": [
{
"type": "custom",
"name": "code_exec",
"description": "Executes arbitrary python code"
}
]
}'1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
curl --request POST --url https://api.openai.com/v1/chat/completions --header "Authorization: Bearer $OPENAI_API_KEY" --header 'Content-type: application/json' --data '{
"model": "gpt-5.2",
"messages": [
{ "role": "user", "content": "Use the code_exec tool to calculate the area of a circle with radius equal to the number of r letters in blueberry" }
],
"tools": [
{
"type": "custom",
"custom": {
"name": "code_exec",
"description": "Executes arbitrary python code"
}
}
]
}'Prompting guidance
We specifically designed GPT-5.2 to excel at coding and agentic tasks. We also recommend iterating on prompts for GPT-5.2 using the prompt optimizer.
Craft the perfect prompt for GPT-5.2 in the dashboard
Learn full best practices for prompting GPT-5 models
See prompt samples specific to frontend development for GPT-5 family of models
GPT-5.2 is a reasoning model
Reasoning models like GPT-5.2 break problems down step by step, producing an internal chain of thought that encodes their reasoning. To maximize performance, pass these reasoning items back to the model: this avoids re-reasoning and keeps interactions closer to the model's training distribution. In multi-turn conversations, passing a previous_response_id automatically makes earlier reasoning items available. This is especially important when using tools—for example, when a function call requires an extra round trip. In these cases, either include them with previous_response_id or add them directly to input.
Learn more about reasoning models and how to get the most out of them in our reasoning guide.
Further reading
GPT-5.1-Codex-Max prompting guide
GPT-5 model family: new features guide
Comparison of Responses API vs. Chat Completions
FAQ
-
How are these models integrated into ChatGPT?
In ChatGPT, there are three models: GPT‑5.2 Instant, GPT‑5.2 Thinking, and GPT-5.2 Pro. Based on the user's question, a routing layer selects the best model to use. Users can also invoke reasoning directly through the ChatGPT UI.
All three ChatGPT models (Instant, Thinking, and Pro) have a new knowledge cutoff of August 2025. For users, this means GPT-5.2 starts with a more current understanding of the world, so answers are more accurate and useful, with more relevant examples and context, even before turning to web search.
-
Will these models be supported in Codex?
Yes,
gpt-5.1-codex-maxis the model that powers Codex and Codex CLI. You can also use this as a standalone model for building agentic coding applications. -
How does GPT-5.2 compare to GPT-5.1-Codex-Max?
GPT-5.1-Codex-Max was specifically designed for use in Codex. Unlike GPT-5.2, which is a general-purpose model, we recommend using GPT-5.1-Codex-Max only for agentic coding tasks in Codex or Codex-like environments, and GPT-5.2 for use cases in other domains. GPT-5.1-Codex-Max is only available in the Responses API and supports
none,medium,high, andxhighreasoning effort settings as well function calling, structured outputs, compaction, and theweb_searchtool. -
What is the deprecation plan for previous models?
Any model deprecations will be posted on our deprecations page. We'll send advanced notice of any model deprecations.