
Atlanta-Milan-Tokyo 🙂

Mau digimanin juga, Tokyo emang jauh dari mana-mana sih 😛
Atlanta-Milan-Tokyo 🙂
Mau digimanin juga, Tokyo emang jauh dari mana-mana sih 😛

Akhirnya, setelah penantian panjang merkhavia berhasil menjawarai pencarian google dengan kata kunci “merkhavia”. Yeiy..berkahramadhan, hehe 😛
Semoga menjadi motivasi buat terus ngisi blog ini ya.. 😀
*ngutip dari postingan pertama
Jadi merkhavia ini awalnya ditemukan sebagai “merhavia” (מרחביה) yang (sepertinya) artinya adalah “penjuru dunia”, diambil dari bahasa hebrew. Kenapa bahasa hebrew? karena kami suka menggunakan ungkapan seperti heu, heuheu, dan hebrew.. *what a reason*
nah tapi, karena “merhavia” ternyata sudah occupied (nama kota di salah satu tempat, ga begitu terkenal juga sih kayaknya, kita juga awalnya ga tau), sehingga memperkecil peluang blog ini ditemukan di google dengan kata kunci itu, akhirnya kita (lo aja kali), melakukan modifikasi seenak udel, sehingga jadilah “merkhavia“… hehehe
**postingan super ga penting
***penting gitu
****iya deh, penting-penting
Ciao Tutti!!!
Setelah tertimpa badai ujian hidup, akhirnya saya kembali muncul di sini, hahaha!!! Sebenernya judulnya ini adalah terjemahan dari kata “Dining Philosopher”, emang sih asa ga pantes banget pas diterjemahin, tapi ya udahlah. Ceritanya saya mesti ngambil kuliah dari departemen saya, trus saya beneran bingung mau ambil apa, karena banyakan emang ga nyambung sama riset saya, karena memang biasanya topik riset kan specialized banget. Walhasil saya mengambil kuliah dari Computer Science yang berjudul “Modeling Time in Computing”. Isi kuliahnya adalah seputar Petri Net, Automata, Transisi, dan Formalisme Logika. Asing? Lumayan sih sebenernya, tetapi tetep ada nyambung-nyambungnya sama Sistem Embedded kok. Tugas akhirnya adalah kami disuruh memilih beberapa permasalahan untuk dipecahkan solusinya gitu. Salah satu masalah yang saya pilih adalah masalah “Dining Philosophers” atau “Para Filsuf di Meja Makan” (dengan standar terjemahan yang rendah tentu saja :P). Idenya adalah seperti ini, coba liat gambar gagal di bawah ini.

Sebelum saya deskripsikan permasalahannya, ada baiknya saya deskripsikan dulu gambar apakah di atas ini. Lingkaran besar adalah meja makan, 5 lingkaran kecil adalah piring, dan garis lurus adalah garpu. Oke, saya tahu, kalau saya tidak jelaskan sebelumnya pasti ga ada yang ngerti ini gambar apa #baper. 😦 Piring ini merujuk ke setiap filsuf juga. Setiap filsuf akan bergantian untuk makan dan berpikir. Syaratnya adalah, peristiwa makan hanya bisa dilakukan dengan kedua garpu di sebelah kanan dan kiri filsuf. Kebayang kan, dalam satu waktu maksimal hanya 2 filsuf yang bisa makan secara bersamaan. Ada 2 kondisi yang harus kita hindari.
1. Deadlock
Hal ini terjadi ketika dalam waktu yang bersamaan, semua filsuf mengambil garpu di sebelah kiri mereka atau di sebelah kanan mereka. Masing-masing filsuf hanya memiliki 1 garpu dan semuanya tidak bisa makan. Ketika mencapai state ini, masalah menjadi tidak bersolusi alias deadlock.
2. Starving
Kelaparan ini terjadi ketika penjadwalan untuk makan dan berpikir terjadi secara tidak seimbang. Misalnya waktu awal filsuf 3 dan filsuf 0 makan, waktu berikutnya filsuf 4 dan filsuf 2 makan, waktu berikutnya filsuf 3 dan filsuf 0 makan, dan seterusnya. Ada 1 filsuf yang sama sekali tidak mendapatkan jadwal untuk makan, yaitu filsuf 1. Pada peristiwa ini, filsuf 1 akan mengalami kelaparan dan hal ini merupakan hal yang tidak diinginkan untuk terjadi.
Solusi
Akan segera saya update. Hahaha. (gia)
Kali ini saya lagi pengen bahas soal estimasi frekuensi, estimasi maximum likelihood, dan Cramer Rao Bound. Emang rada ga ada hujan ga ada angin sih (ga juga sih, di sini anginnya lagi kenceng banget), tapi saya sendiri lagi pengen bahas ini. Pokoknya pengen aja *naon pisan*. Mulai dari mana ya, dari definisi modelnya dulu saja. Berikut adalah model umum sebuah sistem, mungkin karena topiknya adalah pemrosesan sinyal dengan statistik, anggap saja bahwa ini adalah pemodelan sinyal, yang sebenarnya bisa digeneralisasi ke model yang lainnya juga.
dengan 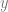
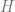


Anggap saja kita akan mengestimasi frekuensi dari sinyal sinusoidal. Berarti 
Asumsikan bahwa 
Pertama-tama kita lakukan optimasi terpisah antara
Sekarang mari kita mulai dari analisis fungsi Log-likelihood, yang sebelumnya kita observasi PDF dari y diketahui x.
Wah, ribet bingits ternyata. Itulah gunanya fungsi Log-likelihood, yaitu melakukan simplifikasi terhadap keribetan di atas menjadi:
Setelah itu, untuk mencari nilai x yang membuat fungsi Log-likelihood-nya maksimal, kita harus menghilangkan semua variable yang tidak relevan dengan x, seperti konstanta-konstanta, sehingga menjadi:
Kok max-nya jadi min? Iya, karena nilai x-nya kan jadi pengurangan, berarti kalau mau nilainya makin fungsi likelihood-nya semakin besar, nilai x-nya harus semakin kecil dong. Lanjut.
Seperti biasa, untuk mencari nilai maksimal atau minimal suatu fungsi, bisa kita lakukan penurunan terhadap variabel yang kita inginkan, yaitu
Ketemu deh nilai
Setelah ketemu nilai
Dijamin pusing, hehe. Engga juga kok, kita bisa melakukan beberapa simplifikasi, yaitu dengan mengasumsikan 




Bentuk di atas dapat dijabarkan menjadi bentuk quadratic seperti di bawah ini.
Jadi ![\omega_{ML}=arg \underset{\omega}{min}[tr\{P(\omega)yy^{T}\}]](https://s0.wp.com/latex.php?latex=%5Comega_%7BML%7D%3Darg+%5Cunderset%7B%5Comega%7D%7Bmin%7D%5Btr%5C%7BP%28%5Comega%29yy%5E%7BT%7D%5C%7D%5D&bg=ffffff&fg=666666&s=0&c=20201002)
P.S.: Rehat dulu bentarrr >_< (gia)
Semua pasti sudah menyadari tentang hukum kekekalan (massa atau energi, yang sebenarnya saya kurang tahu masih valid atau tidak). Hukum-hukum tersebut tidak jauh dari output = input. Well, kalau mau banyak output, ya harus banyak input. Seringkali kita dihadapkan dengan keharusan pilihan untuk banyak-banyak menulis. Sebenarnya saya belum di fase harus banyak menulis, namun saya sedang memulai untuk rajin membaca, di mana untuk orang-orang seperti saya, membaca yang berat-berat bukan sebuah kebiasaan saya sejak kecil. Lain halnya dengan rekan saya yang satunya, yang itu tuuuh. Baginya, membaca memang sudah kewajiban kebiasaan semenjak kecil, sehingga ketika dihadapkan pada paper dan jurnal yang berjibun, ah cincay baday. Iri. Banget.
Akhirnya, saya mulai menghadapi kenyataan untuk membaca banyak paper (yang sebenarnya jurnal sih) karena saya tidak mempunyai pilihan lain. Pertama kali harus menghadapi tantangan ini, di tengah-tengah membaca jurnal selalu timbul rasa bosan dan ngantuk. Hal itu saya sadari karena saya tidak memiliki kemauan yang besar maupun pemahaman apa-apa soal isi jurnal tersebut. Mulai bosan dengan kebosanan saya membaca jurnal, saya merasa saya harus menemukan cara agar saya bisa memahami jurnal-jurnal tersebut. Oke. Fokus. Pertama harus fokus dan tanamkan rasa ingin tahu yang tinggi dalam diri kita, baca dengan teliti dan hati-hati. Jangan sampai ada pengetahuan yang tertinggal. Kata profesor saya, kata-kata yang ditulis dalam jurnal itu memang ditulis dengan alasan, bukan untuk di-skip. Oke, Prof. Siap grak. Sebelumnya, ada baiknya kita meninggalkan semua hal duniawi seperti media sosial agar pikiran tetap fokus dan tidak mudah terdistraksi. Buat diri kita senyaman mungkin dalam membaca jurnal. Mulai membaca. Kepikiran hal lain-lain seperti sudah mematikan kompor apa belum, sekarang jam berapa, nanti makan siang apa, ingin mengecek email? Wajar. Abaikan, sesungguhnya itu bisikan setan *halah*. Kembali ke layar laptop. Terus membaca dan membaca, hingga akhirnya kita benar-benar ingin tahu soal jurnal tersebut. Salah satu ciri-ciri bahwa kita mulai tertarik dengan isi jurnal adalah, setiap menemukan [1], [2], [3], dan seterusnya, kita akan segera ke referensi/bibliography, dan mencari paper/jurnal tersebut, kemudian membacanya, terus, terus, seperti rantai setan *tidak perlu semuanya sih, yang penting saja mungkin ya*.
Oke, sampailah pada kesimpulan: “the more I study, the more I realize that I understand nothing”. Ingin menyerah? Sebenarnya iya. Namun terkadang rasa ingin tahu mengalahkan rasa ingin menyerah itu, haha. Sekian. (gia)
Yak, ini adalah salah satu kelas master yang mesti saya ikuti, hiksss. Ga enaknya lagi jadwal kuliahnya pagi-pagi banget, komparasinya sama aja di Indonesia kuliah jam 6 pagi T.T makanya pertemuan pertama skip akibat err, gatau kalau mulai kuliahnya minggu kemaren, ahahaha. Failed? Superrr. Dan begitu masuk kuliah pertama (yang sebenernya pertemuan kedua), saya langsung ‘disuguhi’ judul: Geometrical Representation of the Signal. Dueng!!! Asa baru denger yang ginian selama hidup. Logis banget sih, tapiii, ide ini terlalu keren sumpahhh. Walaupun bab ini sebenernya ada juga di buku kuliahnya Bu Andrea Goldsmith yang super keren. Anyway, jangan pernah nyoba masuk kelas ini kalau masih 0 sama aljabar linear, bukannya gimana-gimana sih, tapi masa yang diomongin tiba-tiba subspace, basis, dan linear independence. Lah itu kalau saya sebulan lalu ga baca-baca soal aljabar linear pastilah ga ngerti apa-apa banget haha. Saya juga pengen sih nulis sedikit tentang aljabar linear di merkhavia, namun… *lalu php* Tapi beneran keren, bab Geometrical Representation of the Signal ditaruh di awal itu beneran ide yang bagus, soalnya kita jadi kebayang ruang sinyal itu seperti apa, hehe.
Pertama, sinyal dalam bentuk waveform di ruang waktu merepresentasikan titik di ruang sinyal. Kayaknya mesti dikasih definisi nih *yaeyalah*. Hmmm… Saya pengen ngasih contoh sih dengan menggunakan konstelasi 8-PSK (8-Phase Shift Keying). Kuncinya adalah ada 8 titik pada ruang sinyal yang memiliki amplitude yang sama, hanya dibedakan oleh fasenya saja. Misalnya kita punya himpunan sinyal yang terdiri dari 8 waveform, yaitu:
Serta memiliki basis orthonormal, yaitu:
Merasa asing ga dengan istilah basis orthonormal? Awalnya saya juga lho. Tetapi istilah ini merupakan istilah dasar di kuliah aljabar linear, istilah yang super penting. Jadiii, kita uraikan satu per satu kata-katanya. Haha, basis dan orthonormal.
Basis
Basis adalah himpunan dari vektor yang linear independen, yang pada kombinasi linearnya dapat merepresentasikan seluruh vektor pada ruang vektor yang diberikan/didefinisikan? Wait wait, ini kok horror amat ya pake istilah linear independen segala? Apa sih linear independen itu? Jadi gini deh *berhubung bakal ribet banget kalau pakai digambar segala, saya mengajak pembaca untuk membayangkan saja*, misalkan kita punya 2 vektor 


Orthonormal
Well, orthonormal itu sebenarnya gabungan antara orthogonal dan normal, maksudnya berarti vektornya saling tegak lurus dan ternormalisasi. Misalnya kedua vektor yang kita bahas sebelumnya, yaitu 

Kebayang ga kira-kira sinyalnya? Kuncinya kalau pengen kebayang sih, ganti aja t (huruf kecil) dengan angka, misalnya 1-10 ya. Ntar bisa kita plot satu per satu gambarnya. Duh sesungguhnya jujur dari lubuk hati yang terdalam, saya pengen loh plot satu2, tapiii…
P.S.: Gantung dulu bentar yakkk, kalau interest silahkan di-follow, insyaAllah di-update terus hehe (gia)
Halo, sedikit sharing tentang salah satu mata kuliah yang sedang hangat di sini: Probabilistic Robotics
Oke, apa sih ini ilmu probabilitas robotics?
Sederhananya, ini adalah ilmu mengaplikasikan ilmu probabilitas ke dalam robotika.
Mengapa harus ada ilmu probabilitas dalam robotika?
Simpelnya, dalam dunia ini kan tidak ada yang pasti, bahkan indera manusia saja banyak yang suka salah sangka. Apalagi sensor robot? Dengan ilmu probabilitas ini, kita jadi bisa mengukur seberapa besar keyakinan kita terhadap pencitraan robot.
Sensor robot memangnya suka salah sangka?
Betul! bahkan sensor yang mahal sekalipun seperti sensor laser. Bisa saja kita menghitung jarak dari sini ke suatu titik, yaitu jarak X, namun ternyata aslinya bukan X karena sebenarnya laser tersebut menembus permukaan kaca, jadi dia menganggap jarak yang dideteksi itu lebih jauh.
Di sini lah ilmu probabilitas robotika berperan. Kita bisa menganalisa data dan dari analisa tersebut, kita bisa tahu seberapa besar keyakinan kita terhadap data tersebut.
Pada kasus tersebut, kita bisa menganalisa dari data sensor laser tersebut yang menembus permukaan kaca, sehingga kita berikan keyakinan yang rendah terhadap pembacaan sensor itu.
kenapa harus yakin ? memangnya kenapa gak bisa langsung aja percaya dengan pembacaan data sensor itu?
Ya nggak lah! seandainya kamu naik pesawat yang pembacaan sonar nya cuma memiliki keyakinan 40% bahwa di depan sana tidak ada gunung, apa kamu tidak khawatir? berarti 60% nya yakin kan kalo di depan ada gunung? Tentu hal ini amat membahayakan penumpang
Oh, oke, jadi manfaatnya ilmu ini apa?
Dengan sensor yang standard seperti sensor ultrasonik, bukan sensor super mahal seperti laser, kita bisa mendapatkan hasil pencitraan yang akurat karena kita bisa memilih hasil dengan keyakinan yang tinggi, dan hasil ini amat membantu kita dalam memutuskan langkah apa yang akan diambil si robot setelahnya.
Oke, saya dapat idenya, implementasi ke lebih technical nya gimana?
Banyak implementasi dari ilmu ini yang sudah diaplikasikan. Karena kita bisa mengukur keyakinan kita akan suatu pembacaan sensor, dengan mengakumulasikan pembacaan tersebut kita bisa menggunakannya dalam berbagai aplikasi seperti mapping dan localization seperti localization monte-carlo, particle filtering, online learning, atau SLAM.
Ada contoh lain gak? Riset terkini di bidang ini apa sih?
Google Driverless Car intinya adalah aplikasi ilmu ini. Professor yang terkemuka di bidang ini adalah Sebastian Thrun, dia adalah professor Stanford & CMU yang merancang Stanford Driverless Car yang memenangkan Darpa Challenge pada tahun 2005. Dia juga yang memimpin riset driverless car di Google.
Wow gokil! ada referensi lain nggak?
Ada, Sebastian Thrun punya web site juga http://www.probabilistic-robotics.org/
Kalo mau belajar lebih mendalam, ini PDF bukunya: http://people.ufpr.br/~danielsantos/ProbabilisticRobotics.pdf
Oke udah kebayang kan ide awalnya ini seperti apa?
Nanti dilanjutkan dengan pembahasan yg lebih mendalam ya 😀
Halo semua, saya orang ketiga di blog ini. Salam kenal.
Beberapa minggu yang lalu (*hampir sebulan mungkin), rekan saya memberikan sebuah contoh yang cukup menarik dalam tulisannya tentang Pemrosesan Sinyal Statisik, yaitu masalah power di meja makan. Di post saya yang pertama ini, saya ingin mencoba menuliskan cara saya *menyerang* masalah tersebut.
Berikut adalah problem statement dari masalah power tersebut. Misalkan 









Kesan pertama saya saat membaca problem statement di atas adalah masalah ini masih terlalu umum. Informasi yang bisa kita gunakan dari problem statement ini masih terlalu sedikit. Mari kita coba lebih menyederhanakan masalah ini.
Pertama, karena 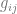



Yang kedua, lagi – lagi karena kita berada di meja makan, rasanya masuk akal juga jika kita asumsikan bahwa jika saya saat ini ada di suatu grup, saya dapat menyampaikan pesan ke semua grup lainnya, walaupun pesan tersebut mungkin harus melewati lebih dari satu grup sebelum sampai ke grup yang saya tuju. Sebagai contoh, misalkan grup 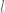
Dengan menambahkan dua asumsi ini, kita memiliki cukup informasi untuk menyelesaikan masalah ini. Jadi, masalah ini sekarang berbunyi sebagai berikut. Misalkan
Nah, pertanyaannya sekarang, kita mau mulai dari mana? Ada baiknya kita mulai dari eksistensi 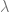

Akan tetapi, kita tidak hanya ingin 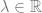
Akan tetapi, ada hipotesis tambahan untuk Teorema Perron-Frobenius versi kedua ini, yaitu matriks 


Sayangnya, ini semua masih belum cukup. Kita menginginkan lebih dari sekedar ![\lambda \in (0, 1]](https://s0.wp.com/latex.php?latex=%5Clambda+%5Cin+%280%2C+1%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![\rho(G) \in (0, 1]](https://s0.wp.com/latex.php?latex=%5Crho%28G%29+%5Cin+%280%2C+1%5D&bg=ffffff&fg=666666&s=0&c=20201002)
Karena seluruh elemen diagonal dari matriks 

Kita bisa berhenti sampai di sini, tapi mari lanjutkan sedikit lagi. Kita memang sudah dapat memberikan solusi (yang cukup umum) untuk masalah ini, tetapi adakah kasus spesial untuk masalah ini? Adakah kasus yang cukup spesial sehingga kita dapat menemukan pasangan eigenvalue–eigenvector dalam bentuk closed form? Kalau ada yang punya ide, mangga di-share di komen :D.
[ravi]
Beberapa minggu terakhir (dengan terpaksa) saya terpapar ilmu stokastik. Jadi ceritanya di lab saya ada yang namanya book reading session, dimana tiap minggu kita ganti-gantian presentasiin isi buku dan bukunya ini diharapkan beres selama satu semester.
Alkisah semester ini kita membahas buku “Introduction to Stochastic Control“..mew..bukan saya yang milih loh ya, semua hak prerogatif profesor saya.
*btw, entah kenapa setiap denger stokastik yang seketika kebayang di otak saya malah bunyi yang keluar dari mukul2in stik ke gelas kaca *siapa sih yang menanamkan insepsi sesat kayakgini
Tapi stokastik itu bukan kayak gitu kok (yakali, lo doang kali yang mikir gitu). Stokastik itu apa ya, kayak sesuatu yang penuh dengan ketidakpastian (udah kayak kehidupan aja..haha), random (nah kalo ini pikiran saya yang suka random 😛 ), ada probabilitas-probabilitasnya, yang gitu-gitu deh
*duh maafkan saya yang terlalu failed ketika membuat definisi 😥
Nah minggu kemaren, di lab saya ngebahas gimana cara memprediksi output dari proses stokastik, dan bagaimana kita mendesain kontrol yang bisa membuat output proses stokastik kita memiliki variance minimum (jadi outputnya ga gujlek gujlek gitu *bahasa apa ini*).
Karena sebelumnya disini udah ada yang nyentil-nyentil masalah prediksi dari sisi signal processing, kayaknya seru deh kalo ada juga yang nulisnya dari point of view-nya stochastic control 😀
*walopun kayaknya case nya rada beda sih..hehe
*tapi maaf ya kalo tulisannya rada cupu dan banyak gagal pahamnya..hebrew << tuh kan,itulah mengapa kita menamai blog ini “merkhavia” 😛
Continue reading
24-09-2014
Yak, masih belom ganti hari, tapi saya bikin baru aja deh, kok kayaknya banyak banget yang pengen ditulis, haha. Update: ternyata setelah disindir di ruang publik *engga karena ini juga sih sebenernya, maksud saya ga kausal juga kok ahahaha*, rekan saya langsung konkret nulis, udah gitu yang susah2 pulak, aaakkk. Baiklah setidaknya harus tuntaslah bagian ini *ceritanya ga mau kalah*.
Okay, saya ingin mengawali konsep bias dan variance yang bahkan saya baru paham benar sekarang T.T *ngapain aja dulu mbak pas kuliah*. Ini kaitannya sama performa estimator. Bentar2, kok tiba2 ngomongin estimator ya? Yap, ini berkaitan sama postingan saya sebelumnya tentang mengestimasi parameter-parameter yang tidak diketahui. Namanya estimasi juga ga mungkin 100% akurat kan ya, jadi harap dimaklumi saja. Sekian. *ditabok*
Well, tapi kita masih punya kesempatan lhooo untuk meminimalisasi error antara hasil estimasi dengan hasil aktual. Semakin mendekati berarti semakin akurat *yudonsei sih ini ya*.
Continue reading




![p( y|x) = \frac{1}{2\pi^{\frac{N}{2}}} \frac{1}{|C_{w}|^{\frac{1}{2}}}exp\{-\frac{1}{2} [y-H(\omega)x ]^{T} C_{w}^{-1}[y-H( \omega )x] \}](https://s0.wp.com/latex.php?latex=p%28+y%7Cx%29+%3D+%5Cfrac%7B1%7D%7B2%5Cpi%5E%7B%5Cfrac%7BN%7D%7B2%7D%7D%7D+%5Cfrac%7B1%7D%7B%7CC_%7Bw%7D%7C%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D%7Dexp%5C%7B-%5Cfrac%7B1%7D%7B2%7D+%5By-H%28%5Comega%29x+%5D%5E%7BT%7D+C_%7Bw%7D%5E%7B-1%7D%5By-H%28+%5Comega+%29x%5D+%5C%7D&bg=ffffff&fg=666666&s=0&c=20201002)

![L(x|y) = -\frac{N}{2}ln2\pi - \frac{1}{2}ln|C_{w}|-\frac{1}{2}[y-H(\omega)x]^{T}C_{w}^{-1}[y-H(\omega)x]](https://s0.wp.com/latex.php?latex=L%28x%7Cy%29+%3D+-%5Cfrac%7BN%7D%7B2%7Dln2%5Cpi+-+%5Cfrac%7B1%7D%7B2%7Dln%7CC_%7Bw%7D%7C-%5Cfrac%7B1%7D%7B2%7D%5By-H%28%5Comega%29x%5D%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7D%5By-H%28%5Comega%29x%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![arg \underset{x}{max}L(x|y)=arg\underset{x}{min}[y-H(\omega)x]^{T}C_{w}^{-1}[y-H(\omega)x]](https://s0.wp.com/latex.php?latex=arg+%5Cunderset%7Bx%7D%7Bmax%7DL%28x%7Cy%29%3Darg%5Cunderset%7Bx%7D%7Bmin%7D%5By-H%28%5Comega%29x%5D%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7D%5By-H%28%5Comega%29x%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![arg\underset{x}{min}[y-H(\omega)x]^{T}C_{w}^{-1}[y-H(\omega)x]=arg\underset{x}{min}[y^{T}C_{w}^{-1}y^{T}-x^{T}H(\omega)^{T}C_{w}^{-1}y-y^{T}C_{w}^{-1}H(\omega)x+x^{T}H(\omega)^{T}C_{w}^{-1}H(\omega)x]=arg\underset{x}{min}[y^{T}C_{w}^{-1}y^{T}-2x^{T}H(\omega)^{T}C_{w}^{-1}y+x^{T}H(\omega)^{T}C_{w}^{-1}H(\omega)x]](https://s0.wp.com/latex.php?latex=arg%5Cunderset%7Bx%7D%7Bmin%7D%5By-H%28%5Comega%29x%5D%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7D%5By-H%28%5Comega%29x%5D%3Darg%5Cunderset%7Bx%7D%7Bmin%7D%5By%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7Dy%5E%7BT%7D-x%5E%7BT%7DH%28%5Comega%29%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7Dy-y%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7DH%28%5Comega%29x%2Bx%5E%7BT%7DH%28%5Comega%29%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7DH%28%5Comega%29x%5D%3Darg%5Cunderset%7Bx%7D%7Bmin%7D%5By%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7Dy%5E%7BT%7D-2x%5E%7BT%7DH%28%5Comega%29%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7Dy%2Bx%5E%7BT%7DH%28%5Comega%29%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7DH%28%5Comega%29x%5D&bg=ffffff&fg=666666&s=0&c=20201002)


![L(x|y) = -\frac{N}{2}ln2\pi - \frac{1}{2}ln|C_{w}|-\frac{1}{2}[y-H(\omega)(H(\omega)^{T}C_{w}^{-1}H(\omega))^{-1}H(\omega)^{T}C_{w}^{-1}y]^{T}C_{w}^{-1}[y-H(\omega)(H(\omega)^{T}C_{w}^{-1}H(\omega))^{-1}H(\omega)^{T}C_{w}^{-1}y]](https://s0.wp.com/latex.php?latex=L%28x%7Cy%29+%3D+-%5Cfrac%7BN%7D%7B2%7Dln2%5Cpi+-+%5Cfrac%7B1%7D%7B2%7Dln%7CC_%7Bw%7D%7C-%5Cfrac%7B1%7D%7B2%7D%5By-H%28%5Comega%29%28H%28%5Comega%29%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7DH%28%5Comega%29%29%5E%7B-1%7DH%28%5Comega%29%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7Dy%5D%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7D%5By-H%28%5Comega%29%28H%28%5Comega%29%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7DH%28%5Comega%29%29%5E%7B-1%7DH%28%5Comega%29%5E%7BT%7DC_%7Bw%7D%5E%7B-1%7Dy%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![arg \underset{\omega}{max}L(x|y)=arg \underset{\omega}{min}[y-P(\omega)y]^{T}[y-P(\omega)y]](https://s0.wp.com/latex.php?latex=arg+%5Cunderset%7B%5Comega%7D%7Bmax%7DL%28x%7Cy%29%3Darg+%5Cunderset%7B%5Comega%7D%7Bmin%7D%5By-P%28%5Comega%29y%5D%5E%7BT%7D%5By-P%28%5Comega%29y%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![arg \underset{\omega}{max}L(x|y)=arg \underset{\omega}{min}[y(I-P(\omega))]^{T}[y(I-P(\omega))]](https://s0.wp.com/latex.php?latex=arg+%5Cunderset%7B%5Comega%7D%7Bmax%7DL%28x%7Cy%29%3Darg+%5Cunderset%7B%5Comega%7D%7Bmin%7D%5By%28I-P%28%5Comega%29%29%5D%5E%7BT%7D%5By%28I-P%28%5Comega%29%29%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![arg \underset{\omega}{max}L(x|y)=arg \underset{\omega}{min}[y^{T}(I-P(\omega)-P(\omega)+P(\omega))y]](https://s0.wp.com/latex.php?latex=arg+%5Cunderset%7B%5Comega%7D%7Bmax%7DL%28x%7Cy%29%3Darg+%5Cunderset%7B%5Comega%7D%7Bmin%7D%5By%5E%7BT%7D%28I-P%28%5Comega%29-P%28%5Comega%29%2BP%28%5Comega%29%29y%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![arg \underset{\omega}{max}L(x|y)=arg \underset{\omega}{min}[y^{T}(I-P(\omega))y]=arg \underset{\omega}{min}[y^{T}P(\omega)y]=arg \underset{\omega}{min}[y^{T}P(\omega)y]=arg \underset{\omega}{min}[tr\{P(\omega)yy^{T}\}]](https://s0.wp.com/latex.php?latex=arg+%5Cunderset%7B%5Comega%7D%7Bmax%7DL%28x%7Cy%29%3Darg+%5Cunderset%7B%5Comega%7D%7Bmin%7D%5By%5E%7BT%7D%28I-P%28%5Comega%29%29y%5D%3Darg+%5Cunderset%7B%5Comega%7D%7Bmin%7D%5By%5E%7BT%7DP%28%5Comega%29y%5D%3Darg+%5Cunderset%7B%5Comega%7D%7Bmin%7D%5By%5E%7BT%7DP%28%5Comega%29y%5D%3Darg+%5Cunderset%7B%5Comega%7D%7Bmin%7D%5Btr%5C%7BP%28%5Comega%29yy%5E%7BT%7D%5C%7D%5D&bg=ffffff&fg=666666&s=0&c=20201002)



