-
-
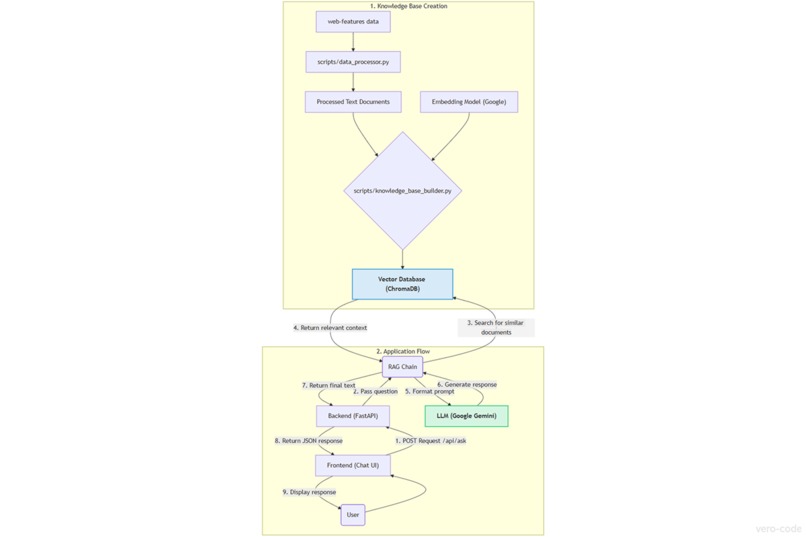
Architecture of Baseline AIgent, showing the RAG pipeline from data processing to the final AI response.
-
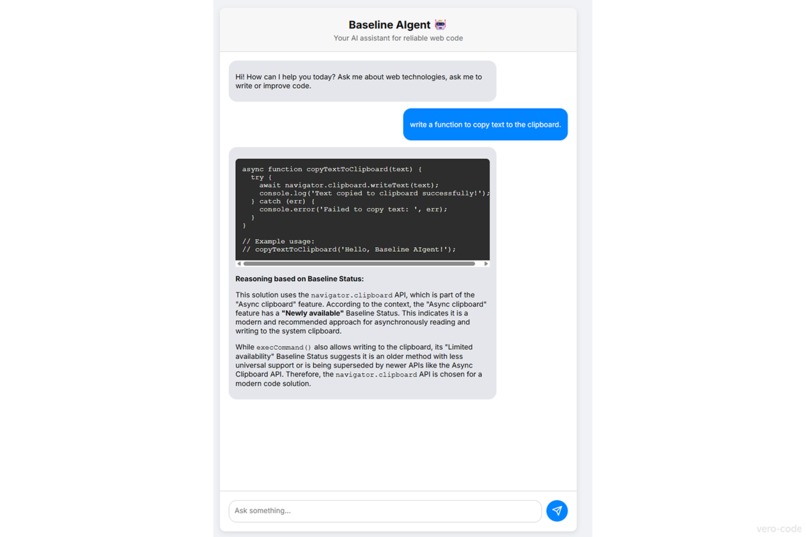
Baseline AIgent generating modern, reliable code with a clear explanation based on the feature's Baseline Status.


Inspiration
My inspiration came directly from the hackathon's prompt, which asked a powerful question: "What might Baseline's role look like in an increasingly agentic world?" As a developer who uses AI assistants daily, I've felt the pain of the "AI trust gap." I love the speed of AI tools, but I can't blindly trust their output. They often suggest outdated or incompatible code because they're trained on a chaotic mix of the entire internet, including decade-old Stack Overflow answers.
I wanted to build an AI assistant that I could actually trust—one that wasn't just a smart guesser, but a reliable engineering partner. The idea was to create an AI whose knowledge was grounded not in the whole web, but in a single source of truth: the Baseline standard.
What it does
Baseline AIgent is an intelligent AI assistant that provides web developers with modern, reliable, and production-ready code solutions guaranteed to be cross-browser compatible.
It has three core functions:
Direct Q&A: You can ask direct questions about web features (e.g., "Is CSS Nesting safe to use?") and get an instant, accurate answer based on its official Baseline status.
Modern Code Generation: Ask it to write a function (e.g., "write a function to copy text to the clipboard"), and it will generate a modern, secure implementation using Baseline-compatible APIs, explaining its choices along the way.
"Safety-First" Refactoring: You can ask it to refactor old code. Crucially, if the AI cannot find a guaranteed Baseline-compatible solution in its knowledge base, it will honestly tell you so, rather than providing a potentially unreliable answer. This "safe-fail" mechanism is its most important feature, acting as a safeguard against bad code.
How I built it
I built Baseline AIgent as a full-stack application with a Python backend and a vanilla JavaScript frontend. The core of the project is a Retrieval-Augmented Generation (RAG) architecture.
Here’s a breakdown of the tech stack:
Data Source: The project's "source of truth" is the official
web-featuresdataset, which I downloaded and processed.Knowledge Base: I used ChromaDB to create a local vector database from the processed
web-featuresdata. The text documents were converted into embeddings using Google'sembedding-001model.AI Core: I used the LangChain library to build the RAG pipeline. It connects the user's query to the ChromaDB retriever and the Google Gemini API (
gemini-2.5-flash) for generating responses.Backend: A FastAPI server exposes the RAG chain through a simple
/api/askendpoint. I also implemented CORS to allow the frontend to communicate with it.Frontend: A simple and clean chat interface built with vanilla HTML, CSS, and JavaScript. It uses
fetchto communicate with the backend API and themarked.jslibrary to render Markdown in the AI's responses.
The entire architecture is designed to be simple, efficient, and runnable locally.
Challenges I ran into
My biggest challenge was also my most important discovery. During testing, I asked the agent to refactor a simple jQuery fadeIn() function. To my surprise, the AI responded: "I don't have enough information... I cannot provide a solution that meets the 'baseline compatible' requirement."
At first, I thought this was a failure. However, I realized the AI was being perfectly honest. In its knowledge base, the most semantically similar feature was "display animation," which has a "limited availability" status. Because it couldn't find a guaranteed widely available feature for the task (like "CSS Transitions"), it chose to fail safely rather than give a bad answer. This was the moment I knew the core concept was working.
Accomplishments that I'm proud of
I'm most proud of successfully implementing the "safe-fail" mechanism. Seeing the AI refuse to answer a question because it couldn't guarantee a reliable solution was the project's "aha!" moment. It proved that it's possible to build an AI that is not just a code generator, but a trustworthy partner that protects developers from potential errors.
I’m also proud of building a complete RAG system from scratch within the hackathon's timeline, from data processing and embedding to building the final user interface.
What I learned
This project was a deep dive into the practicalities of building RAG systems. I learned that the quality of the retriever's results is incredibly dependent on the structure and content of the source documents. Just having the data isn't enough; it needs to be processed and sometimes enriched to be effective for natural language queries.
I also learned a lot about prompt engineering—crafting the perfect instruction to ensure the AI adheres strictly to the provided context and explains its reasoning, which is key to making its responses useful and educational.
What's next for Baseline AIgent
This project is a solid foundation, and there are many exciting directions to take it:
Data Enrichment Pipeline: To solve the
fadeInchallenge, the next step would be to build a script that programmatically enriches the data, adding keywords and use-case descriptions to improve the retriever's accuracy.VS Code Extension: The ultimate goal would be to integrate Baseline AIgent directly into the developer's workflow as a VS Code extension, providing real-time advice and code generation inside the editor.
Framework-Specific Context: The agent could be enhanced to understand framework-specific contexts, like providing React hooks or Vue composables that use Baseline-compatible browser APIs.
Built With
- baseline
- chromadb
- css
- fastapi
- gemini
- html
- javascript
- langchain
- python
- web-features


Log in or sign up for Devpost to join the conversation.