-
-
Model Framework
-

Models loaded
-
First user prompt, creating embeddings, checking if special agent exists.
-
Similar 5 queries to increase the count of SQL -> label.
-
Count as seen logged in query_log file under SQL ->Label.
-
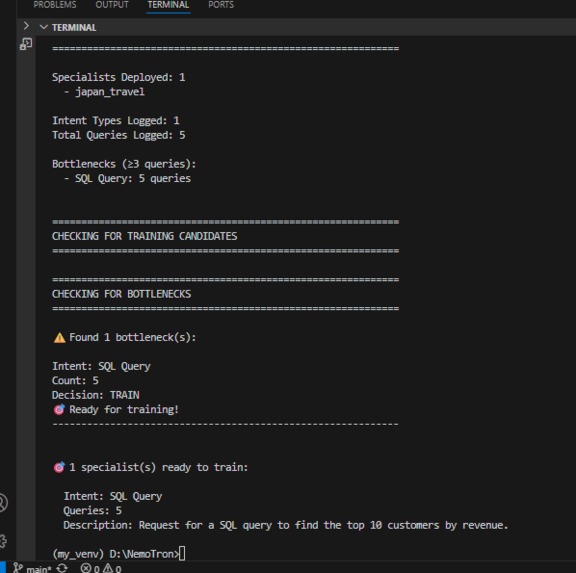
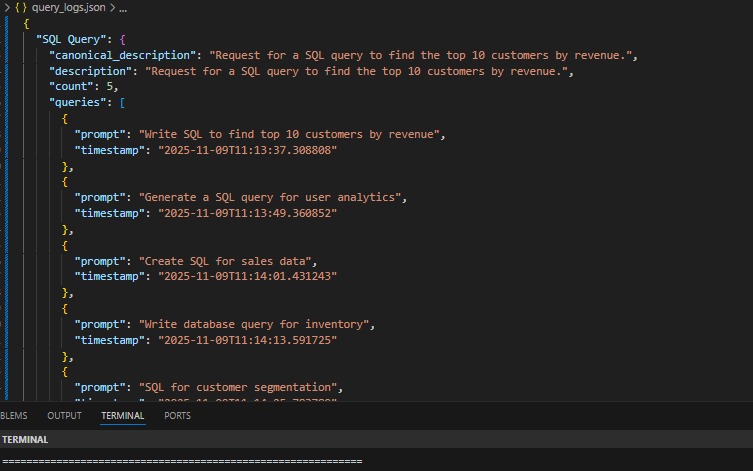
As count >= threshold, thus the need for new specialized agent.
-
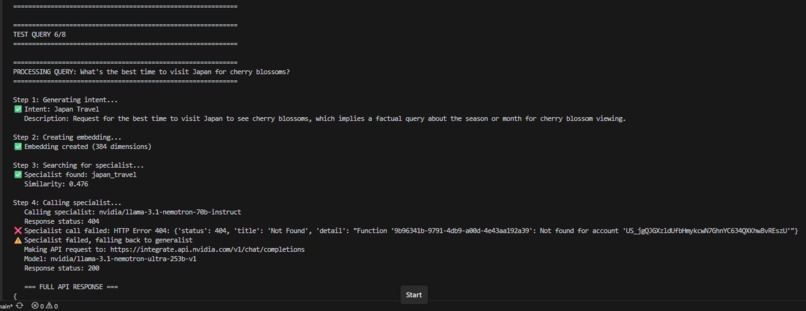
New query for the special agent that I have (Japan). It shows from user query embeddings that, yes, an agent already exists for this.







Inspiration
Every AI system today has the same fatal flaw - the moment you deploy it, it stops learning.
Think about it. The day you launch your shiny new AI model is the best it will ever be. From that point on, it stagnates while the world keeps changing, or you train it, but at a cost
We’ve all seen this pattern now. You start with a general-purpose giant like GPT-5 or Nemotron-253B, capable of everything from text summarization to GPU code optimization. It’s brilliant, but brutally expensive. And yet, 90% of real-world queries are simple - requests like “summarize this,” “rewrite that,” or “generate SQL.”(as per statistics)
So why are we paying 253B prices for 8B problems?
That question became our obsession.
We asked ourselves - can an AI system get smarter, faster, and cheaper the more it runs? Can it watch itself work, spot its own bottlenecks, and train new specialists automatically - without any human in the loop?
That’s when we built something different:
an AI that evolves.
It doesn’t just perform tasks - it studies its own behavior, identifies inefficiencies, and spawns new fine-tuned models to fix them overnight.
It’s not just intelligent. It’s self-improving. It’s artificial evolution moving from artificial intelligence
What it does
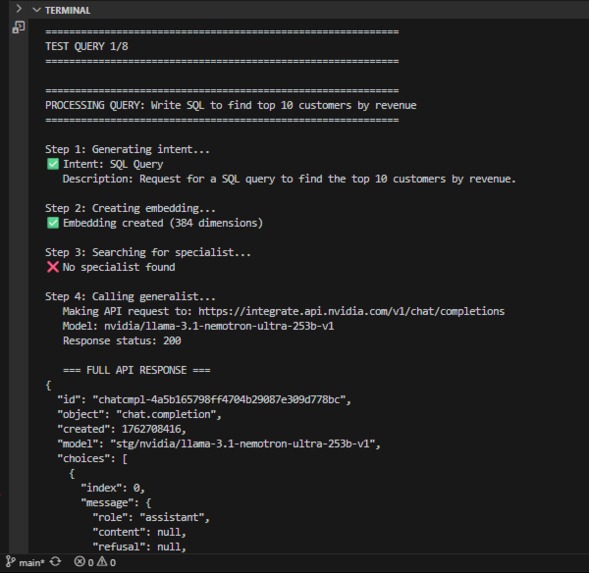
Let’s start simple. You give the system a prompt: “Write an SQL query to get the top 5 customers by total purchase amount.”
At first, there’s no “SQL Agent.” The system only has the Generalist Model — a huge foundation model (Nemotron-253Bin our setup). It handles the request directly, runs inference, and gives you a correct answer.
But the Router is watching. Over the next few hours, it notices something: hundreds of similar prompts — “generate SQL,” “fix this SQL,” “explain this SQL.” The Router detects a recurring intent pattern.
Now the system makes a decision — “I keep seeing this kind of task. Why waste a massive 253B model every time?” So i need to creates an Agent.
🧬 The Birth of an Agent
Data Generation The Generalist uses its own reasoning to generate a massive, diverse synthetic dataset for this new “SQL” intent — thousands of input-output pairs covering schema variations, join cases, aggregations, and even intentionally flawed examples for robustness.
Reward Filtering Before using the data for training, each example is scored by the Nemotron-70B Reward Model. Only the top 75% of examples with the highest quality scores are kept. This ensures the specialist learns from the most accurate, reliable, and diverse examples.
Self-Fine-Tuning Next, it fine-tunes a smaller, specialized model (e.g., Mistral-7B or Phi-3-mini) using that curated dataset. This becomes the SQL Expert Agent — lean, fast, and surgically precise for that one domain.
Each one is born the same way — observed need → self-generated data → reward-filtered selection → self-fine-tuned specialist → autonomous deployment. (future)
What begins as a single generalist brain becomes a self-organizing network of evolving agents — each trained, deployed, and managed automatically as the system learns what the world actually needs.
No humans labeling data. No manual fine-tuning loops. Just continuous, intelligent evolution.
🏗 How We Built It
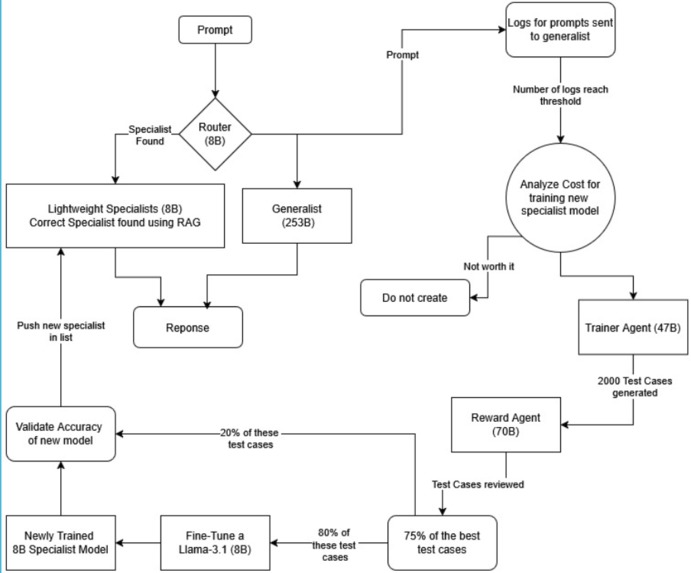
We built the system as a fully autonomous Model Evolution Loop, composed of key modules.
Router (The Intent Brain): Every user query first hits the Router, a lightweight classifier that combines text embeddings with semantic search via FAISS. It predicts the intent — SQL generation, Python debugging, text summarization, etc. — and checks the Agent Registry to see if a specialist exists. If an agent exists, the Router routes the prompt there. If not, it flags the intent as “unserved” and triggers the Evolution Loop.
Trainer Generative model: The large LLM like mixtral-8x7b-instruct-v0.1 — acts as the teacher. When a new intent arises, it automatically generates thousands of diverse prompt-response pairs using structured templates and controlled randomness. Each example is self-labeled, checked for consistency, and curated to form a robust synthetic dataset for fine-tuning.
Fine-Tuner + Reward Model (The Self-Trainer & Filter): Once the dataset is ready, the Fine-Tuner launches a GPU-bounded fine-tuning job using PEFT/LoRA on models like Mistral-7B, LLaMA-3-8B, or Phi-3-mini. Before training, all examples are filtered through the Nemotron-Reward model (nvidia/llama-3.1-nemotron-70b-reward) to select the top 75% most high-quality and relevant samples. This ensures the specialist is trained only on robust, high-fidelity data, preserving accuracy while reducing noise.
The combination of synthetic data generation, reward-based filtering, and fine-tuning produces a fast, lean specialist model ready to handle its designated intent — all autonomously, with no humans in the loop.
⚙ Tech Stack Highlights:
LLMs: Nemotron-253B (teacher), Phi-3-mini / Mistral-7B (students)
Reward Filtering: Nemotron-70B-Reward
Fine-tuning: PEFT (LoRA), Hugging Face Accelerate
Routing: FAISS embeddings + cosine similarity
Data Management: JSONL pipelines with auto-versioning
Orchestration: Python microservices
Challenges we ran into
We ran into a lot of issues haha — partly because time was short, but mostly because we were trying to make AI do something it’s not built to do yet: evolve by itself.
Generating Realistic Test Cases Creating diverse, non-repetitive data for new intents was tough — the model kept generating shallow or similar examples. We solved it using a semantic noise injection technique and a reward-filtering loop, but we still need a smarter redundancy detector.
Semantic Retrieval (RAG Layer) FAISS often retrieved lexically similar but semantically wrong examples. We switched to transformer-based embeddings and re-ranking by intent metadata, which improved accuracy but slowed performance at scale.
Stable Intent Clustering Prompt embeddings caused unstable clustering — almost identical tasks formed multiple clusters. We added an adaptive threshold based on variance to merge close clusters, but it still needs auto-merge over time.
Reward Model Drift As agents multiplied, the reward model’s scoring drifted, making older agents look worse. We now recalibrate scores against a held-out set, though automatic normalization remains future work.
Time & Compute Constraints Fine-tuning and evaluation cycles were expensive and time-limited. We focused on proving the core evolution loop (generalist → router → reward → new agent), saving deployment and long-run training for later.
Intent Drift Over Time User prompts evolved — “generate SQL” became “optimize SQL” and “fix SQL,” confusing the router. We introduced temporal clustering so older agents adapt or merge when intent meaning shifts, keeping the ecosystem stable and self-evolving.
Accomplishments that we're proud of
We’ve only scratched the surface. Our next step is to close the full agentic loop — blending human feedback, continuous learning, and autonomous deployment. Full Deployment: Launch specialists as NIM microservices with a live dashboard to visualize routing and new agent creation. Human-in-the-Loop Feedback: Add simple feedback loops (👍/👎 or text) to align learning with real user intent. Smarter Meta-Agent: Upgrade reasoning to handle context, diversity, and collaboration between agents.
Expanding Specialist Library: Grow from SQL and code to finance, legal, and more — a living ecosystem of agents.
Edge & Enterprise Ready: Optimize for portability, compression, and cost-efficient self-training anywhere.
What we learned
We all started this project the same way we’ve built every hackathon project before — vibe-coding. You know that feeling when you’re in flow, ideas flying faster than your brain can structure them? That was us. We jumped right into building, wiring APIs, generating datasets, spinning up pipelines. But somewhere around the 200th failed test case and the third all-nighter, it hit us — we weren’t thinking, we were reacting. Since forever, we’ve had calculators, search engines, and compilers — tools that helped us think faster. But AI is different. It can think for us if we let it. And that’s dangerous. Because the moment you stop understanding why something works, you stop building, and start imitating. So we forced ourselves to stop coding for a bit. We drew out the architecture on paper. We asked the hard questions: “Why does this system need to exist?” “What is actually evolving here?” That pause changed everything.
From there, every technical breakthrough — from designing feedback loops that made the agent aware of its own bottlenecks, to building a reward-based self-training system — came from that mental reset. And honestly, we learned that time constraints are brutal. But those same limits forced us to focus on essence over perfection. We didn’t finish everything, sure — but what we did finish actually thinks. And that’s the part that matters.
What's next for FindingNemo
Looking back, this project was a whirlwind of late-night coding, constant debugging, and endless “aha” moments. We stumbled, we pivoted, and we learned more than we expected. Yet, seeing our AI system watch itself, learn, and get smarter on its own — even in this early form — was truly magical. It reminded us why we build: not just to make things work, but to push the boundaries of what’s possible. This is just the beginning, and we can’t wait to see how far it can evolve.


Log in or sign up for Devpost to join the conversation.