-
-
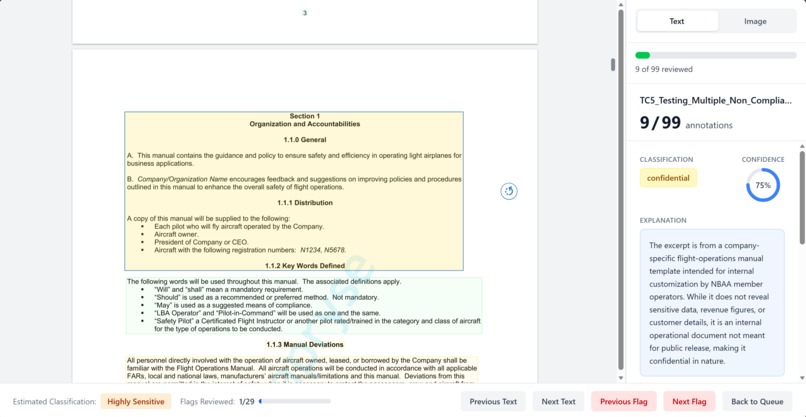
Text Classification with text citations
-

Image safety classification
-

Reviewer Page
-
Home Page
-

Upload Page
-
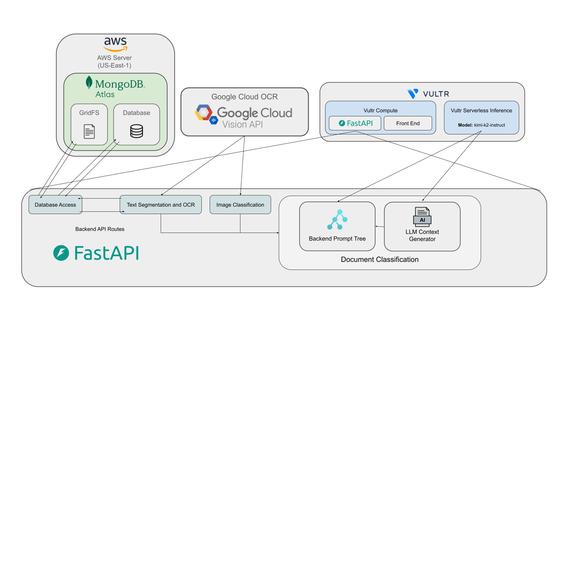
Infrastructure layout diagram
-
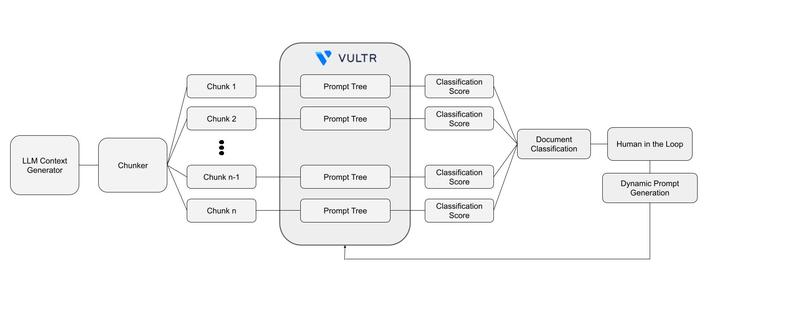
Classification pipeline







Inspiration
Organizations struggle to classify multi-page, multi-modal documents for regulatory compliance. Manual review is slow, error-prone, and doesn't scale. We built Makoto to automate classification with AI while keeping human oversight.
What it does
Makoto is an AI-powered document classifier that analyzes PDFs (text and images) and classifies them into Public, Confidential, Highly Sensitive, or Unsafe. It provides section-level citations, confidence scores, and explanations for each classification. The system includes:
- Multi-modal analysis: processes text (via Google Document AI) and images (via Google Vision API Safe Search)
- Citation-based evidence: exact page numbers and bounding box coordinates for audit trails
- Human-in-the-Loop workflow: intelligent reviewer queue prioritizes uncertain classifications
- Dynamic prompt engineering: Tree of Prompts (ToP) agent with configurable prompt chains that can be refined by experts
- Safety monitoring: automatic detection of unsafe content (hate speech, violence, exploitation, etc.)
- Business-friendly UI: interactive PDF viewer with color-coded annotations, detailed reports, and file management
How we built it
Backend (Python/FastAPI):
- FastAPI REST API with async processing
- Google Document AI for text extraction and bounding box detection
- Google Vision API for image safety classification
- MongoDB with GridFS for document storage
- Tree of Prompts (ToP) agent using Vultr's
kimi-k2-instructSLM - Parallel processing with ThreadPoolExecutor (up to 20 workers) for concurrent classification
- Background task processing for non-blocking document analysis
Frontend (React/TypeScript):
- React 19 with TanStack Router for navigation
- PDFTron WebViewer for interactive PDF viewing with annotations
- Tailwind CSS for styling
- Motion library for animations
- Real-time status updates and progress tracking
AI Architecture:
- Tree of Prompts agent with four classification chains (Sensitive, Confidential, Public, Unsafe)
- Each chain uses sequential prompts that build context progressively
- Document summary generation for context-aware classification
- Configurable prompt library supporting AI-assisted and manual prompt editing
Challenges we ran into
- PDF coordinate system mapping: aligning Document AI bounding boxes with PDFTron WebViewer coordinates required careful scaling and transformation calculations
- Parallel processing: managing concurrent LLM API calls while maintaining order and handling errors gracefully
- Multi-modal synchronization: coordinating text and image classification results into a unified document-level classification
- Real-time updates: implementing non-blocking background processing while providing immediate feedback to users
- MongoDB GridFS integration: efficiently storing large PDFs and associated metadata with proper indexing
- Prompt engineering: designing effective prompt chains that balance accuracy with cost-efficiency using lightweight SLMs
Accomplishments that we're proud of
- Built a complete end-to-end system from document upload to classification review in a short timeframe
- Achieved cost-effective AI processing using the lightweight
kimi-k2-instructSLM instead of expensive large models - Created an intuitive UI that makes complex AI classifications accessible to non-technical users
- Implemented a flexible prompt engineering system that allows continuous improvement through HITL feedback
- Delivered precise citation-based evidence with page-level and bounding box-level accuracy
- Integrated multiple Google Cloud APIs (Document AI, Vision API) seamlessly with proper error handling
- Built a scalable architecture supporting both interactive and batch processing modes
What we learned
- Lightweight SLMs can achieve strong results with proper prompt engineering and context management
- Tree of Prompts provides a flexible framework for complex classification tasks
- Human-in-the-Loop workflows are essential for building trust in AI systems
- Citation-based evidence is critical for regulatory compliance and user acceptance
- Multi-modal document analysis requires careful orchestration of different AI services
- Real-time status updates significantly improve user experience during long-running processes
- Parallel processing requires robust error handling to prevent cascading failures
What's next for Makoto
- Dual-LLM validation: implement cross-verification using two LLMs to reduce HITL involvement
- Advanced prompt optimization: use machine learning to automatically refine prompt chains based on reviewer feedback
- Batch processing enhancements: add bulk upload capabilities with progress tracking and scheduling
- Enhanced visualizations: develop more sophisticated dashboards for classification analytics and audit trails
- Custom classification categories: allow organizations to define their own classification taxonomies
- API integrations: connect with document management systems and compliance platforms
- Performance optimization: further reduce processing time through caching and smarter parallelization strategies
- Mobile support: develop mobile-friendly interfaces for on-the-go document review
Bonus! Customer Demonstration Video: https://youtu.be/orp1MgI0xig
Built With
- amazon-web-services
- fastapi
- google-cloud
- google-cloud-vision-api
- mongodb
- mongodbatlas
- python
- react
- vite
- vultr


Log in or sign up for Devpost to join the conversation.