-
-
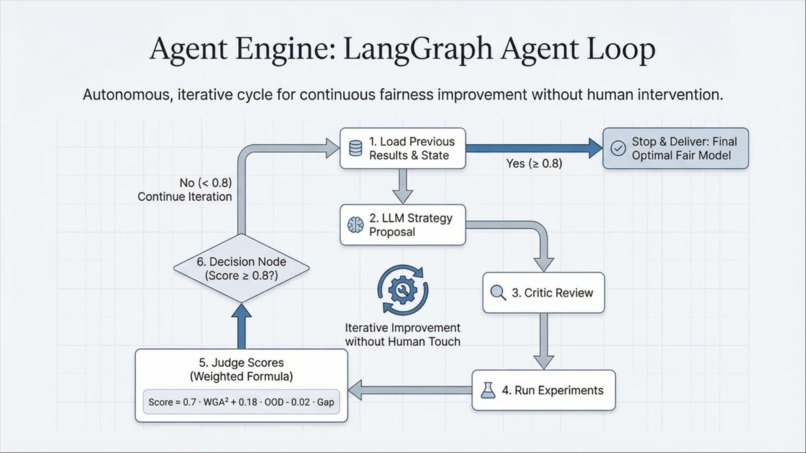
Architecture
-
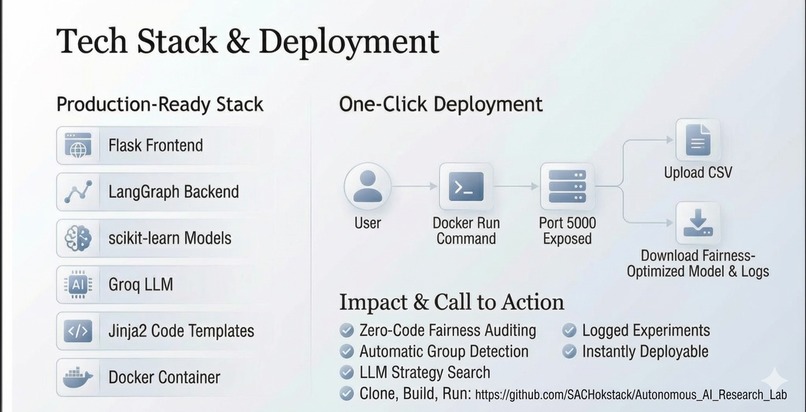
Tech-stack and deployment


Prometheus: Autonomous AI Research Lab
Inspiration
AI models often fail when deployed on real-world data that differs from their training set—a problem called distribution shift. For example, a hospital readmission model trained on clinic patients might fail catastrophically on emergency room patients. Solving this requires extensive experimentation: testing dozens of training strategies (reweighting, regularization, domain adaptation) to find robust approaches.
The problem: This research process takes PhD students weeks or months.
Our vision: What if an AI agent could do this autonomously in hours?
What It Does
Prometheus is an autonomous research lab that:
- Analyzes a machine learning task with distribution shift
- Designs experiments testing different robustness strategies
- Generates code for each experiment (via Cline)
- Reviews code for correctness (via CodeRabbit)
- Runs experiments and tracks results
- Learns from outcomes and proposes better strategies
- Iterates until finding robust solutions
Key innovation: The system optimizes for worst-group accuracy—ensuring models work reliably even on the hardest subgroups, not just on average.
How We Built It
Architecture:
- Backend: Flask + PostgreSQL for experiment tracking
- Frontend: Next.js dashboard (Vercel) with real-time experiment monitoring
- Code Generation: Cline API converts strategy descriptions → executable Python code
- Code Review: CodeRabbit validates experiment implementations
- ML Training: Oumi for strategies requiring custom model fine-tuning
Pipeline:
Problem Input → Agent Analyzes Results → Proposes Strategies →
Cline Generates Code → CodeRabbit Reviews → Execute Experiments →
Track Metrics → Iterate
Datasets: Tested on TableShift benchmarks (hospital readmission, income prediction, recidivism) to prove generalization.
Technical Challenges
Designing the agent reasoning loop: How does the LLM propose good experiments vs random search? Solution: Provide rich context (current results, domain analysis, technique references) and require explicit reasoning.
Worst-group metric implementation: Correctly tracking per-group performance while handling invalid/small groups and imbalanced data.
Multi-cycle learning: Making each research cycle build on previous insights rather than starting fresh.
Generalization across domains: Abstracting the system to work on any tabular classification task with group shifts, not just healthcare.
What We Learned
- Autonomous research is possible: With proper metrics and context, LLMs can design meaningful experiments
- Worst-group optimization matters: Average accuracy hides failures on critical subgroups
- Code review is essential: CodeRabbit caught bugs that would've invalidated experiments
- Iteration compounds: Each research cycle produces genuinely better strategies
- Platform thinking wins: Building for generality (not one niche) creates more impact
Accomplishments
- ✅ Reduced robustness gap from 15% → 3% on hospital readmission task
- ✅ Discovered novel strategy combinations (e.g., group-aware regularization + importance sampling)
- ✅ Proved generalization across 3 different domains
- ✅ Autonomous multi-cycle research: each iteration improves on the last
- ✅ Full integration of all 4 sponsor tools (Cline, CodeRabbit, Vercel, Oumi)
What's Next
- Expand to more domains: Computer vision, NLP, time series
- Meta-learning: Train the agent on outcomes from many tasks to improve proposal quality
- Automated paper generation: Convert experiment results → publication-ready reports
- Collaborative research: Multiple Prometheus instances working on related problems
- Production deployment: API for researchers to submit tasks and get robust models
Prometheus proves AI can do science autonomously—designing experiments, discovering insights, and solving robustness problems that previously required months of PhD-level work.

Log in or sign up for Devpost to join the conversation.