 Member of Technical Staff, xAI
Member of Technical Staff, xAI
Email: [email protected]
Google Scholar • GitHub • LinkedIn
About Me / Bio
- Ronghang Hu is a member of technical staff at xAI, focusing on pushing the frontier of multimodal AI.
- Previously, Ronghang Hu was a research scientist at Meta FAIR (formerly Facebook AI Research), and was devoted to the Segment Anything series of projects to build strong visual perception models, and was a core contributor to SAM 2 and SAM 3. Ronghang obtained his Ph.D. degree in Computer Science from the University of California, Berkeley in 2020, and his B.Eng. degree from Tsinghua University in 2015.
Experiences
- xAI (Palo Alto, CA; 11/2025 — present)
Member of Technical Staff - Meta FAIR (Menlo Park, CA; 06/2020 — 11/2025)
Research Scientist - Facebook AI Research (Menlo Park, CA; 05/2019 — 08/2019)
Research Intern - Facebook AI Research (Seattle, WA; 05/2017 — 08/2017)
Research Intern
Education
- University of California, Berkeley (Berkeley, CA; 08/2015 — 05/2020)
Ph.D. and M.S. in Computer Science - Tsinghua University (Beijing, China; 08/2011 — 07/2015)
B.Eng. in Electronic Information Science and Technology
Selected Projects
 SAM 3: Segment Anything with Concepts
SAM 3: Segment Anything with Concepts
arXiv preprint arXiv:2511.16719, 2025
(PDF, Project, Code, Demo, Blog)
- Segment Anything Model 3 (SAM 3) is a unified foundation model for promptable segmentation in images and videos. It can detect, segment, and track objects using text or visual prompts such as points, boxes, and masks. Compared to its predecessor SAM 2, SAM 3 introduces the ability to exhaustively segment all instances of an open-vocabulary concept specified by a short text phrase or exemplars.
 SAM 2: Segment Anything in Images and Videos
SAM 2: Segment Anything in Images and Videos
International Conference on Learning Representations (ICLR), 2025 — Outstanding Paper Honorable Mentions
(PDF, Project, Code, Demo, Dataset, Blog)
- Segment Anything Model 2 (SAM 2) is a foundation model towards solving promptable visual segmentation in images and videos. We extend SAM to video by considering images as a video with a single frame. The model design is a simple transformer architecture with streaming memory for real-time video processing.
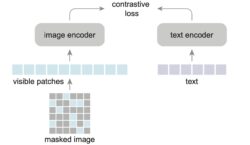 Scaling Language-Image Pre-training via Masking
Scaling Language-Image Pre-training via Masking
Computer Vision and Pattern Recognition (CVPR), 2023
(PDF, Code)
- We present Fast Language-Image Pre-training (FLIP), which gives ~3.7x speedup over the traditional CLIP and improves accuracy using the same training data on a large variety of downstream tasks.
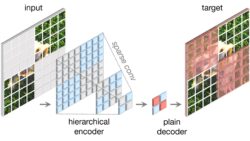 ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
Computer Vision and Pattern Recognition (CVPR), 2023
(PDF, Code)
- We propose ConvNeXt V2, a fully convolutional masked autoencoder framework (FCMAE) and a new Global Response Normalization (GRN) layer that can be added to the ConvNeXt architecture to enhance inter-channel feature competition.
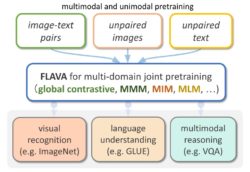 FLAVA: A Foundational Language And Vision Alignment Model
FLAVA: A Foundational Language And Vision Alignment Model
Computer Vision and Pattern Recognition (CVPR), 2022
(PDF, Project Page)
- We propose FLAVA, a foundational model that performs well over a wide variety of 35 tasks on all three target modalities: 1) vision, 2) language, and 3) vision & language, and develop an efficient joint pretraining approach on both unimodal sources.
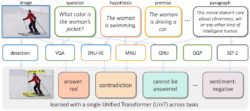 UniT: Multimodal Multitask Learning with a Unified Transformer
UniT: Multimodal Multitask Learning with a Unified Transformer
International Conference on Computer Vision (ICCV), 2021
(PDF, Project Page)
- We build UniT, a unified transformer encoder-decoder model to simultaneously learn the most prominent tasks across different domains, ranging from object detection to language understanding and multimodal reasoning.