Following on from last post I want to talk about the appropriate notion of morphism between the objects I defined. Recall that these are Lie groupoids  with a map to the manifold
with a map to the manifold 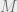 satisfying some properties (
satisfying some properties ( and
and  are surjective submersions), and then equipped with a little bit of extra structure. We will fix a bundle of abelian Lie groups
are surjective submersions), and then equipped with a little bit of extra structure. We will fix a bundle of abelian Lie groups  (where this projection map is a surjective submersion). Then the extra structure is that we have a specified isomorphism between the bundle of Lie groups
(where this projection map is a surjective submersion). Then the extra structure is that we have a specified isomorphism between the bundle of Lie groups  (see the previous post for notation) and the pullback of
(see the previous post for notation) and the pullback of  along
along  , such that that the conjugation action of on factors through the resulting descent data for in the guise of its encoding of an action of the Čech groupoid
, such that that the conjugation action of on factors through the resulting descent data for in the guise of its encoding of an action of the Čech groupoid  on . This is the definition of an abelian -bundle gerbe.
on . This is the definition of an abelian -bundle gerbe.
Now, given two Lie groupoids  and
and  over (with the surjective submersions as above) we can consider internal functors
over (with the surjective submersions as above) we can consider internal functors  between them, commuting with the projections to . Such a functor is a map of (generalised bundle) gerbes over , but we want to consider more specifically maps of abelian -bundle gerbes.
between them, commuting with the projections to . Such a functor is a map of (generalised bundle) gerbes over , but we want to consider more specifically maps of abelian -bundle gerbes.
The cartoon analogy to keep in mind as to what could happen without further conditions is if you had a pair of principal 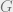 -bundles
-bundles  and
and  , and a map
, and a map  over , but it was only equivariant in a weak way, namely that
over , but it was only equivariant in a weak way, namely that  where
where 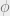 is a group automorphism of . Abelian -bundle gerbes are principal 2-bundles for the 2-group (or bundle of 2-groups)
is a group automorphism of . Abelian -bundle gerbes are principal 2-bundles for the 2-group (or bundle of 2-groups)  , but the way in which they inherit this action because of the isomorphism
, but the way in which they inherit this action because of the isomorphism  , and functors automatically commute with the action of on . So instead of having to impose a condition analogous to , this comes for free, in that from a functor (over )
, and functors automatically commute with the action of on . So instead of having to impose a condition analogous to , this comes for free, in that from a functor (over )  between abelian -bundle gerbes you get an endomorphism of bundles of groups of the pullback of along
between abelian -bundle gerbes you get an endomorphism of bundles of groups of the pullback of along  . This arises as the composite
. This arises as the composite  .
.
So the requirement that we are going to impose is going to firstly ensure this endomorphism of  is an automorphism, which we can then ask is actually descendable, so that it arises from an automorphism of down on (in principle, one could ask the endomorphism descends without asking it’s an automorphism, but not today). But, secondly we are going to ask that the automorphism of is in fact the identity map. This is the analog of asking the group automorphism above is the identity map on . However, we need to specify these conditions explicitly in a way that makes sense in the picture of bundle gerbes as internal groupoids.
is an automorphism, which we can then ask is actually descendable, so that it arises from an automorphism of down on (in principle, one could ask the endomorphism descends without asking it’s an automorphism, but not today). But, secondly we are going to ask that the automorphism of is in fact the identity map. This is the analog of asking the group automorphism above is the identity map on . However, we need to specify these conditions explicitly in a way that makes sense in the picture of bundle gerbes as internal groupoids.
So, it’s been a long way around to give the intuition (and this blog post has been long delayed, due to work commitments and other things), but the final definition is in fact rather easy. All that we ask is that  is a pullback, so that the square witnessing the fact is a pullback of along
is a pullback, so that the square witnessing the fact is a pullback of along  is the pasting of the similar square for
is the pasting of the similar square for  and the square witnessing the fact is a pullback of .
and the square witnessing the fact is a pullback of .
One then has to check that from this definition, and the condition that the descent data for “comes from” the adjoint action of 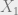 on , means that the resulting automorphism of descends to the identity map.
on , means that the resulting automorphism of descends to the identity map.
Given the above, one can then go back and examine what happens if you drop the requirement the bundle gerbe is abelian. Certainly the definition given (that  ) still makes sense even when we only ask that we have a “
) still makes sense even when we only ask that we have a “ -bundle gerbe”, for any bundle of Lie groups on .
-bundle gerbe”, for any bundle of Lie groups on .
The final point, I think, is that a morphism of abelian -bundle gerbes is a functor of Lie groupoids satisfying two conditions: commuting with the functors down to the base, and the pullback condition discussed above. In particular there is no extra data that we need to supply to define a morphism.
What does this tell us in the case of a vanilla (abelian) 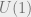 -bundle gerbe, as originally defined by Michael Murray? (Though note that in the paper, everything’s done with
-bundle gerbe, as originally defined by Michael Murray? (Though note that in the paper, everything’s done with  -bundles instead) He defined a notion of morphism of bundle gerbes
-bundles instead) He defined a notion of morphism of bundle gerbes 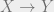 , which amounts to a functor over such that
, which amounts to a functor over such that  is a map of -bundles covering the map
is a map of -bundles covering the map  . If I take
. If I take  , then as last time, a bundle gerbe on is a Lie groupoid
, then as last time, a bundle gerbe on is a Lie groupoid  over equipped with a trivialisation
over equipped with a trivialisation  as a bundle of groups, satisfying conditions. Given two such, say and
as a bundle of groups, satisfying conditions. Given two such, say and  , a morphism between them in my sense is a functor over such that the restriction of
, a morphism between them in my sense is a functor over such that the restriction of  to respects the trivialisations. This condition then ensures that the full is a map on the total spaces of -bundles.that is -equivariant, so we have a morphism of bundle gerbes in Murray’s sense. Now assume we have a pair of abelian -bundle gerbes
to respects the trivialisations. This condition then ensures that the full is a map on the total spaces of -bundles.that is -equivariant, so we have a morphism of bundle gerbes in Murray’s sense. Now assume we have a pair of abelian -bundle gerbes  , and a morphism between them in Murray’s sense. Then since
, and a morphism between them in Murray’s sense. Then since  is a map of -bundles covering , the resulting square is a pullback, and then the restriction of this square along the diagonal maps
is a map of -bundles covering , the resulting square is a pullback, and then the restriction of this square along the diagonal maps  and
and  (to get the map
(to get the map  over
over  ) is still a pullback, and then we have recovered my definition of morphism. This I have recovered the traditional definition up to equivalence.
) is still a pullback, and then we have recovered my definition of morphism. This I have recovered the traditional definition up to equivalence.
The natural continuation of the above discussion is to examine what we should do with natural transformations (or rather, natural isomorphisms, as they all are). Of course, the data of a natural isomorphism  over is a smooth function
over is a smooth function  satisfying the usual naturality condition. To compare to the literature, we need to go to section 3.4 of Danny Stevenson’s PhD thesis (which builds a 2-category of bundle gerbes and morphisms à la Murray, in the lead up to Proposition 3.8). The definition of 2-arrow is slightly nontrivial and on inspection of Lemma 3.3 one can see that the definition of abelian bundle gerbe I have given is being implicitly relied on, where descent data is given by conjugation in the groupoid, to descend a certain bundle down to . The data of a 2-arrow in Stevenson’s sense gives a smooth map
satisfying the usual naturality condition. To compare to the literature, we need to go to section 3.4 of Danny Stevenson’s PhD thesis (which builds a 2-category of bundle gerbes and morphisms à la Murray, in the lead up to Proposition 3.8). The definition of 2-arrow is slightly nontrivial and on inspection of Lemma 3.3 one can see that the definition of abelian bundle gerbe I have given is being implicitly relied on, where descent data is given by conjugation in the groupoid, to descend a certain bundle down to . The data of a 2-arrow in Stevenson’s sense gives a smooth map  that, I think by the construction in Lemma 3,3, is in fact the data of a natural isomorphism (implicit in the equation at the bottom of page numbered 27). The question is: what else do we get? Or, another tactic is to see if an arbitrary natural isomophism
that, I think by the construction in Lemma 3,3, is in fact the data of a natural isomorphism (implicit in the equation at the bottom of page numbered 27). The question is: what else do we get? Or, another tactic is to see if an arbitrary natural isomophism  is enough to define a 2-arrow in Stevenson’s sense. Given the component map
is enough to define a 2-arrow in Stevenson’s sense. Given the component map  , it gives a section
, it gives a section  of Danny’s bundle
of Danny’s bundle  (which is the pullback of
(which is the pullback of  by
by  ). What we need to check is that descends to a section of the descended bundle
). What we need to check is that descends to a section of the descended bundle  . However, we know that the descent data for
. However, we know that the descent data for  that is constructed in Lemma 3.3 is by conjugation, and the naturality condition on
that is constructed in Lemma 3.3 is by conjugation, and the naturality condition on  in fact tells us that is compatible with this descent data, and so descends to a section as needed.
in fact tells us that is compatible with this descent data, and so descends to a section as needed.
So in fact we can define a 2-arrow between morphisms (in my sense) to just be a natural isomorphism satisfying no additional conditions. And so we can define a 2-category of bundle gerbes as a locally full—and not full—sub-2-category of the 2-category of Lie groupoids over . My discussion in the past two blog posts (this and the previous one) is much longer than the bare definition requires; this is all to motivate and explain. The actual definition could be at most a single paragraph long—cf the more than two pages including two lemmas with proofs needed to define what turns out to be an isomorphic 2-category in Danny’s thesis, in addition to the theory of bundle gerbes that requires.
It turns out this post is longer than I thought it would be, but that’s ok. The next step is to move on from this naive 2-category of bundle gerbes, because the above really isn’t the one that people want. But that will fall out from an existing construction in the literature. I’m not sure, though, if I should first treat the analog of the above definition stack where we add connections to things, before moving on to the “real” definitions for both.







 of (affine) schemes with the pretopology of flat surjections. One can define a presheaf on
of (affine) schemes with the pretopology of flat surjections. One can define a presheaf on  , assign to it the set of locally constant functions from
, assign to it the set of locally constant functions from 
 ) is smaller than the cardinality of the residue field at that point. This gives a functor
) is smaller than the cardinality of the residue field at that point. This gives a functor  , using the fact maps of fields are injective.
, using the fact maps of fields are injective. of affine schemes which are spectra of fields, since one arrives at a contradiction assuming the existence of a sheafification by using a flat covering
of affine schemes which are spectra of fields, since one arrives at a contradiction assuming the existence of a sheafification by using a flat covering  for
for  and
and  fields (in fact any field extension
fields (in fact any field extension  gives such a cover). Then locally constant functions
gives such a cover). Then locally constant functions  are merely elements of
are merely elements of  , or in other words,
, or in other words,  can be taken as
can be taken as 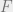 restricts to the forgetful functor
restricts to the forgetful functor  . This is a very natural presheaf to consider (see comment 3 below regarding the pretopology on this subcategory).
. This is a very natural presheaf to consider (see comment 3 below regarding the pretopology on this subcategory). which is just the inclusion for
which is just the inclusion for  and the retract
and the retract  sending
sending  to the bottom element of
to the bottom element of  making the obvious triangle commute, where
making the obvious triangle commute, where  is the sheafification of
is the sheafification of  , for any
, for any  factors through
factors through  so that
so that  is injective, which implies that
is injective, which implies that  is injective, and hence that
is injective, and hence that  , see comments below]
, see comments below]
 (We can check this by applying the natural transformation
(We can check this by applying the natural transformation 
 for a pair of parallel arrows) and remembering
for a pair of parallel arrows) and remembering  is an equaliser.) But
is an equaliser.) But  is a point, so this equaliser is
is a point, so this equaliser is  , which restricts to the full subcategory
, which restricts to the full subcategory  for
for 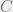 a concrete category whose image in
a concrete category whose image in  isn’t a field, but can find a map from it to a field (as
isn’t a field, but can find a map from it to a field (as  is flat, so I think this means it is a morphism of sites as in Remark 2.3.7 of Sketches of an Elephant (certainly covers in
is flat, so I think this means it is a morphism of sites as in Remark 2.3.7 of Sketches of an Elephant (certainly covers in  . Really one just needs, for any field
. Really one just needs, for any field  and a map
and a map  such that
such that  is injective. I don’t know how to supply this if I don’t have AC, but I haven’t thought very hard. Ideas? Perhaps we can prove this by contradiction.
is injective. I don’t know how to supply this if I don’t have AC, but I haven’t thought very hard. Ideas? Perhaps we can prove this by contradiction. along itself”, we can actually fill the square with the identity map of
along itself”, we can actually fill the square with the identity map of  can be used to fill in the square, using the fact every arrow is a cover. From now on I’ll drop all the ‘op’ business for simplicity.
can be used to fill in the square, using the fact every arrow is a cover. From now on I’ll drop all the ‘op’ business for simplicity. is an element
is an element  , such that when a span
, such that when a span  fills the square (i.e.
fills the square (i.e.  ) then
) then  . The sheaf condition is then that given such descent data, we have that there is a unique
. The sheaf condition is then that given such descent data, we have that there is a unique  such that
such that  . Since this condition quantifies over fillers of the square, we can consider the subclass where
. Since this condition quantifies over fillers of the square, we can consider the subclass where  ,
,  and thus that
and thus that  . The only way that we can have
. The only way that we can have  for all elements of the Galois group is that
for all elements of the Galois group is that  comes from the (underlying set of the) base field
comes from the (underlying set of the) base field 
 , where
, where  is the
is the 




 , namely an exponential stack of fifteen 10s. For comparison,
, namely an exponential stack of fifteen 10s. For comparison,  is already more than 200 times larger than BB(5), and increasing that index at the end makes this function grow superexponentially. In fact, about
is already more than 200 times larger than BB(5), and increasing that index at the end makes this function grow superexponentially. In fact, about  , by
, by  , compared to which the number of particles in the observable universe is a rounding error away from zero. But then even more recently, a
, compared to which the number of particles in the observable universe is a rounding error away from zero. But then even more recently, a 
 out of the water. It’s hard to conceive of this number as a concrete actual natural number, one is left resorting to imagining exponential towers whose height is also measured in exponential towers.
out of the water. It’s hard to conceive of this number as a concrete actual natural number, one is left resorting to imagining exponential towers whose height is also measured in exponential towers. . But we just don’t know (yet?) if BB(6) is bigger than
. But we just don’t know (yet?) if BB(6) is bigger than  in the recursive definition that extends the definition of Graham’s number, for all k past some threshold, and that threshold may well be 6 or 7, but it is no bigger than 14, since
in the recursive definition that extends the definition of Graham’s number, for all k past some threshold, and that threshold may well be 6 or 7, but it is no bigger than 14, since  . If anyone knows tighter bounds on when
. If anyone knows tighter bounds on when  , I’d love to hear about it! However, it should be noted that BB(14) beating Graham’s number is certainly more impressive than learning that BB(64) beats it, merely because the BB function has blown past the
, I’d love to hear about it! However, it should be noted that BB(14) beating Graham’s number is certainly more impressive than learning that BB(64) beats it, merely because the BB function has blown past the 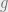 -function before that point. To point to the current lower bound of BB(7), we need much more iteration of the up-arrow notation to say how long
-function before that point. To point to the current lower bound of BB(7), we need much more iteration of the up-arrow notation to say how long 

 space, instead select a random subset from
space, instead select a random subset from  , the
, the  -fold power of the Sierpinski space
-fold power of the Sierpinski space  , since every
, since every  , and the only open subsets are
, and the only open subsets are  . The point
. The point  is open, which is true for all points in discrete spaces, but not for example in the reals with the standard topology, where they are closed. The point
is open, which is true for all points in discrete spaces, but not for example in the reals with the standard topology, where they are closed. The point  is closed in
is closed in  to
to  via
via  , where
, where  is the classifying map for the open set
is the classifying map for the open set  (this sends everything in
(this sends everything in 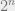 arises from the taking the uniform distribution on
arises from the taking the uniform distribution on  . It’s certainly not uniform, since (the homeomorphism classed of)
. It’s certainly not uniform, since (the homeomorphism classed of) 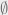 appear once, but the one-point space appears many times. It feels like one should use some kind of approximation or asymptotics, rather than attempt to get an exact answer.
appear once, but the one-point space appears many times. It feels like one should use some kind of approximation or asymptotics, rather than attempt to get an exact answer. where one takes the codiscrete topology (with only two opens) and declares the point
where one takes the codiscrete topology (with only two opens) and declares the point  to be open: that is, the sets
to be open: that is, the sets  are the only open subsets (note that now the subset
are the only open subsets (note that now the subset 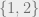 is closed, and no points are closed). In particular, for a finite space
is closed, and no points are closed). In particular, for a finite space  , as shown in
, as shown in  by considering random subsets of
by considering random subsets of  .
.