
Abstract
Simulating quantum dynamics is one of the most important applications of quantum computers. Traditional approaches for quantum simulation involve preparing the full evolved state of the system and then measuring some physical quantity. Here, we present a different and novel approach to quantum simulation that uses a compressed quantum state that we call the “shadow state”. The amplitudes of this shadow state are proportional to the time-dependent expectations of a specific set of operators of interest, and it evolves according to its own Schrödinger equation. This evolution can be simulated on a quantum computer efficiently under broad conditions. Applications of this approach to quantum simulation problems include simulating the dynamics of exponentially large systems of free fermions or free bosons, the latter example recovering a recent algorithm for simulating exponentially many classical harmonic oscillators. These simulations are hard for classical methods and also for traditional quantum approaches, as preparing the full states would require exponential resources. Shadow Hamiltonian simulation can also be extended to simulate expectations of more complex operators such as two-time correlators or Green’s functions, and to study the evolution of operators themselves in the Heisenberg picture.
Similar content being viewed by others
Introduction
Simulating the dynamics of quantum systems, often referred to as quantum simulation or Hamiltonian simulation, is a problem where quantum computers offer an exponential advantage (cf.1,2,3,4,5,6,7,8,9,10). The standard presentation of this problem involves an initial quantum state \(\left| \psi (0)\right\rangle\) that is easy to prepare on a quantum computer and a Hamiltonian H that describes the interactions in the system. The goal is to produce the state at a later time \(t \, > \, 0,\left| \psi (t)\right\rangle\), which satisfies the Schrödinger equation: \(\frac{{{\rm{d}}}}{{{\rm{d}}}t}\left| \psi (t)\right\rangle=-{{\rm{i}}}H\left| \psi (t)\right\rangle\). In applications, once \(\left| \psi (t)\right\rangle\) has been prepared, one is often interested in obtaining some physical property like the ground state energy of the system or some correlation function. Many of these properties can be extracted from a limited set of measurements and expectations, such as those of k-local operators (e.g., two-body correlations).
While access to the full state \(\left| \psi (t)\right\rangle\) allows us to obtain the expectation of any observable on this state, for certain problems, it might suffice to prepare a different quantum state that does not encode all the information encoded by \(\left| \psi (t)\right\rangle\), but instead encodes information about specific properties only. This could result in significant computational savings, motivating us to introduce a novel framework for quantum simulation that we call “shadow Hamiltonian simulation”. Rather than storing the full state in quantum memory during the quantum computation, we only encode certain expectations in the amplitudes of a quantum state of smaller dimension, which we refer to as the “shadow state”. We will see that the shadow state evolves unitarily under its own Schrödinger equation and, under broad conditions, this evolution can be simulated efficiently on a quantum computer, unveiling numerous applications.
To illustrate the power of shadow Hamiltonian simulation, we apply it to simulate the dynamics of free-fermion and free-boson systems, qubit systems, and other systems with a Lie algebraic structure. In the first two cases, by encoding only the expectations of products of fermionic or bosonic operators of constant degree, we can use the exponential dimension of the shadow state to simulate systems of exponential size. These instances can be relevant in, for example, first-quantization simulations, where increasing the number of modes, corresponding to the number of points in a discretized grid, allow for better approximations of the states11,12. We can then use shadow states to compute, for example, energies of quantum states associated with fermionic or bosonic modes at any time. This includes expectations of Hamiltonians that are interacting and other interesting quantities that would require exponential resources using standard Hamiltonian simulation or classical methods. For example, with standard Hamiltonian simulation, the number of registers needed is linear in either the number of particles or the number of modes, while shadow Hamiltonian simulation does not suffer from this exponential growth in space. Moreover, using a classical–quantum correspondence (Ehrenfest theorem) we are able to reproduce the results of ref. 13 on simulating dynamics of exponentially many classical oscillators (a BQP-complete problem), which can now be seen as an example of shadow Hamiltonian simulation. These are only a few example applications but the approach can be applied more broadly.
The principles behind shadow Hamiltonian simulation can be generalized in a way that allows encoding the expectations of more complex operators, such as two-time correlators, in the amplitudes of a different quantum state. This is convenient for exploring other dynamical properties of the system, yet without requiring the preparation of the full system’s state. Additionally, while shadow Hamiltonian simulation is designed to track the time-dependent expectations of certain operators, it can be easily extended to track the evolution of these operators determined by Heisenberg’s equations of motion, without making any reference to a system’s state. This enables other efficient quantum computations, such as learning unitary operations, or finding signatures of operator spreading (e.g., light cones) or scrambling14, for which classical algorithms can take exponential time.
Shadow Hamiltonian simulation relaxes the requirements of standard Hamiltonian simulation in the same way that shadow state tomography relaxes the requirements of full quantum state tomography15. That is, in the traditional state tomography problem, we are given copies of an unknown state and need to learn a full classical description of the state, from which we can obtain the expectation of any observable. This task requires exponentially many (in the system size) copies of the unknown state in general. In contrast, in shadow tomography, the goal is to learn expectations of a limited set of observables on the state, a task that requires much fewer samples than traditional state tomography. However, this is only a loose analogy, and we stress that the two settings are distinct: while shadow tomography concerns the problem of learning some classical description of a quantum state, shadow Hamiltonian simulation is related to the problem of evolving expectations in time.
Results
Formalism
Shadow states
Our results use the notion of a “shadow state”, which we define formally. Let S = {O1, …, OM} be a finite set of operators and suppose we are only interested in the expectations 〈Om〉 with respect to a (potentially mixed) quantum state ρ. We would like to store a compressed version of ρ that does not necessarily allow us to reconstruct it, but does allow us to recover certain quantities that depend on the 〈Om〉’s only. We call this the shadow state of ρ with respect to the set S, and define it as follows:
where \(A={\sum }_{m}{\langle {O}_{m}\rangle }^{2}\) is for normalization.
For a given set S, the same shadow state can correspond to many physical states ρ, which occurs when S is not a complete set of operators. In this case, \(\left| \rho ;S\right\rangle\) contains less information than ρ, in the sense that a classical description of ρ cannot be reconstructed from a classical description of \(\left| \rho ;S\right\rangle\) (whereas \(\left| \rho ;S\right\rangle\) is fully specified by ρ and S). While \(\left| \rho ;S\right\rangle\) is a state of finite dimension M, we do not make any assumptions on the dimension of ρ. This allows us to consider infinite-dimensional systems as well, such as bosonic systems.
Note that shadow states depend on ρ and S only, and do not make reference to any interactions or Hamiltonian. In Supp. Inf., we discuss many properties of shadow states. In particular, in Supp. Note 3 we show that if S is an orthogonal set of operators acting on a finite-dimensional system and \(\rho=\left| \psi \right\rangle \left\langle \psi \right|\) is a pure state, then \(\left| \rho ;S\right\rangle\) is a projection or “shadow” of \(\left| \psi \right\rangle \otimes \overline{\left| \psi \right\rangle }\), where \(\overline{\left| \psi \right\rangle }\) is the state whose amplitudes are complex conjugates of the amplitudes of \(\left| \psi \right\rangle\).
One common task that can be solved with shadow states is the estimation of an arbitrary linear combination of the expectations 〈Om〉, which reduces to an overlap estimation problem. Another common task is that of sampling from a distribution where probabilities are Pr(m) ∝ ∣〈Om〉∣2, which can be done by measuring the shadow state in the computational basis. These tasks are related to other problems in quantum simulation, like estimating energies of a subset of modes in fermionic and bosonic systems of exponential size, which are studied in this article.
Shadow Hamiltonian simulation
In standard Hamiltonian simulation, the full initial state ρ(0) is mapped to the final state ρ(t) by applying the evolution operator U(t). This is determined by the Hamiltonian H. Instead, in shadow Hamiltonian simulation, we are additionally given a set of operators S, and the goal is to map the initial shadow state \(\left| \rho (0);S\right\rangle\) to the final shadow state \(\left| \rho (t);S\right\rangle\). The challenge is to construct this mapping, which is different from U(t).
In general, the vector \(\left| \rho (0);S\right\rangle\) might not contain enough information to completely determine the vector \(\left| \rho (t);S\right\rangle\) at a later time. For it to be possible to obtain \(\left| \rho (t);S\right\rangle\) from \(\left| \rho (0);S\right\rangle\), the expectations of the operators in S at time t should be a function of the initial expectations. This occurs when the Hamiltonian H leaves the space of operators spanned by S invariant, in the sense that the commutation relations between H and the operators in S yield a linear combination of operators in S only. In this article, we make strong use of this “invariance property”: We say that H and S satisfy the invariance property (IP) if and only if
where \({h}_{m{m}^{{\prime} }}\) are coefficients. Let HS be the M × M matrix of entries \({h}_{m{m}^{{\prime} }}\). Then, we can write Eq. (2) as
where \({{\bf{O}}}: \! \!={({O}_{1},\ldots,{O}_{M})}^{T}\) is a vector of operators.
The IP ensures that the shadow Hamiltonian simulation problem is solvable, but does not provide the desired mapping. Our first result is that, if the matrix HS is Hermitian, then the shadow state evolves according to a Schrödinger equation, but with the Hamiltonian HS rather than H.
Theorem 1
The shadow state \(\left| \rho (t);S\right\rangle\) satisfies
Furthermore, if HS is Hermitian, Eq. (4) is a Schrödinger equation.
The proof is a direct consequence of Schrödinger’s equation applied to ρ(t) and given in Supp. Note 1. For finite-dimensional systems, HS is Hermitian when the operators in S are orthogonal, i.e., \({{\rm{tr}}}({O}_{m}^{{\dagger} }{O}_{{m}^{{\prime} }})=\lambda {\delta }_{m{m}^{{\prime} }},\lambda \, > \, 0\); see Supp. Note 1. Hence, the result reduces the shadow Hamiltonian simulation problem to standard Hamiltonian simulation, which can be performed efficiently on a quantum computer under broad conditions on HS.
Note that Theorem 1 applies even if the operators in S are not orthogonal or linearly independent, or even if ρ(t) is infinite-dimensional. Additionally, while we assumed S to be time-independent, the results can be generalized to time-dependent operator sets S(t). For this case, the evolution of \(\left| \rho (t);S(t)\right\rangle\) is not only induced by HS but also by the operator due to terms of the form \(\frac{\partial }{\partial t}{O}_{m}(t)\), as they will appear in the time-derivatives of the time-evolved operators under H. Nevertheless, in this article we focus on time-independent S for simplicity.
While the IP alone does not imply that HS is Hermitian in general, it is sometimes possible to take a particular linear combination of the Om’s to fix this; that is, we can use the property [H, AO] = − AHSO for an M × M matrix A and take specific linear combinations of the Om’s to obtain a Hermitian matrix. This provides some flexibility for shadow Hamiltonian simulation, and we will use this observation for simulating bosonic systems. Additionally, since quantum circuits can be interpreted as time evolution with a time-dependent Hamiltonian, shadow Hamiltonian simulation can be easily extended to simulate quantum circuits as well; see Supp. Note 1. Note that, even if HS is not Hermitian, it might be possible to apply other quantum algorithms for simulating the non-unitary evolution arising from Eq. (4) (cf.16,17), but these studies are outside the scope of this article.
Applications
We apply shadow Hamiltonian simulation to various quantum systems, and present problems that can be solved efficiently using this framework. Subsequently, we demonstrate how similar ideas can be applied to related problems: encoding two-time correlators or expectations of products of operators in a quantum state, and encoding a time-dependent operator, subject to Heisenberg’s equations of motion, in a quantum state.
Free-fermion systems
These systems appear ubiquitously in quantum chemistry and physics. Examples include BCS superconductivity18, integer quantum Hall effect19, spin models like the transverse-field Ising model20, and other cases described by mean-field theories. For n fermionic modes, the number of degree-k fermionic operators is \({{\mathcal{O}}}({n}^{k})\), and in this case we could use shadow states to encode the expectations of operators acting on systems that are exponentially large, e.g., n = 2r. Our goal is to provide a method for shadow Hamiltonian simulation that is efficient, of complexity polynomial in r or \({{\rm{polylog}}}(n)\), and polynomial in the evolution time t. We will show this is possible for free-fermion systems under broad conditions.
In terms of Majorana operators, the Hamiltonian of a free-fermion system is \(H={\sum }_{j,k=1}^{2n}{\gamma }_{jk}{c}_{j}{c}_{k}\), where the interaction strengths \({\gamma }_{jk}\in {\mathbb{C}}\) define a 2n × 2n Hermitian matrix Γ. Majorana operators are Hermitian and satisfy the commutation relations [cjck, cl] = 2δlkcj − 2δljck. These imply that H and the set S of degree-k fermionic operators satisfy the IP for any 1 ≤ k ≤ 2n. Consider, for example, \(S={\{{c}_{j}{c}_{k}\}}_{1\le j < k\le 2n}\), and note that the cjck’s are readily orthogonal. The amplitudes of the shadow state \(\left| \rho (t);S\right\rangle\) are proportional to the expectations \(\langle {c}_{j}{c}_{k}(t)\rangle={{\rm{tr}}}(\rho (t)\,{c}_{j}{c}_{k})\), which in this case coincide with the entries of the so-called 1-RDM (reduced density matrix) of the evolved system’s state ρ(t)21. To prepare the shadow state at time t, we would like to simulate the Hamiltonian HS in Eq. (4) efficiently and also prepare the initial shadow state efficiently. For these to occur, it suffices to have efficient access to the sparse matrix Γ and for ρ(0) to be the free vacuum (the state with no bare or free fermions) or a fermionic Gaussian state (Slater determinant). We give more details in Section 4 and Supp. Note 2, which describes the case of free fermions in depth.
Many quantities can be extracted from the shadow state of an exponentially large fermionic system, like the energy 〈HJ〉 of a subset J ⊆ [2n] of Majorana modes, where HJ ≔ ∑(j, k)∈Jγjkcjck. This is an overlap estimation problem, since \(\langle {H}_{J}\rangle=G\sqrt{A}\langle {\psi }_{J}| \rho ;S\rangle\), where \(\left| {\psi }_{J}\right\rangle {:}=\frac{1}{G}{\sum }_{(j,k)\in J}{\gamma }_{jk}\left| j,k\right\rangle\) is a unit quantum state, \(\left| \rho ;S\right\rangle={\sum }_{j,k}\langle {c}_{j}{c}_{k}\rangle \left| j,k\right\rangle /\sqrt{A}\), and \(G={[{\sum }_{(j,k)\in J}{\gamma }_{jk}^{2}]}^{1/2}\) and A are for normalization. It can be shown that A ≤ n. When the set J is extensive so that ∣J∣ ∝ n and Γ is sparse, \(G={{\mathcal{O}}}(\sqrt{n}\parallel \Gamma {\parallel }_{\max })\). Then, \(\langle {H}_{J}\rangle /(n\parallel \Gamma {\parallel }_{\max })\) is an intensive property that can be computed efficiently from the overlap 〈ψJ∣ρ; S〉 using known methods (cf.22). These problems can also be shown to be BQP-complete. More generally, we can consider shadow states that encode the expectations of degree-k fermionic operators, allowing us to estimate energies of interacting fermionic systems (non-quadratic Hamiltonians) in fermionic Gaussian states and other states.
Free-boson systems
These systems are also prevalent in physics, and describe physical phenomena such as superfluidity23 and quantum optics24. Free-boson systems can also be understood as a collection of coupled quantum harmonic oscillators, which are quantum particles evolving under the influence of quadratic potentials. Like in the prior example, we are interested in simulating exponentially large systems efficiently, in time \({{\rm{polylog}}}(n)\) and poly(t).
We consider a presentation of a free-boson system given by a quadratic Hamiltonian \(H=\frac{1}{2}{{{\bf{Y}}}}^{T}\Gamma {{\bf{Y}}}\), where \({{\bf{Y}}}: \! \!={({P}_{1},{P}_{2},\ldots,{Q}_{1},{Q}_{2},\ldots )}^{T}\) is a vector of 2n Hermitian operators and Γ is a 2n × 2n Hermitian matrix of interaction strengths (assumed to be real). The operators Pj and Qj are associated with generalized coordinates like momentum and position, and satisfy the cannonical commutation relations [Yj, Yk] = iΩjk, for j, k ∈ [2n]. Here, Ωjk is the entry of the symplectic matrix \(\Omega=\left(\begin{array}{rc}{{\bf{0}}}&-{{\mathbb{1}}}_{n}\\ {{\mathbb{1}}}_{n}&{{\bf{0}}}\end{array}\right)\), where \({{\mathbb{1}}}_{n}\) is the n × n identity. This implies [YjYk, Yl] = iΩklYj + iΩjlYk. Then, the set of degree-k bosonic operators also satisfies the IP for any k ≥ 1.
As a special case we could choose S = {P1, P2, …, Q1, Q2, …}. However, one immediately arrives at the issue that HS is not Hermitian in general, unless it is number conserving, a case recently addressed in ref. 25 within a related context. To circumvent this issue, we use a decomposition Γ = Γ1Γ2 for some Γ1 of dimension 2n × M and Γ2 of dimension M × 2n, where M ≥ rank(Γ). Transforming Y ↦ O ≔ Γ2Y changes the coefficients in the commutators such that the IP reads [H, O] = − iΓ2ΩΓ1O. The set of operators is now S ≔ {O1, …, OM}; this also satisfies the IP and we are interested in instances where iΓ2ΩΓ1 ≡ HS is Hermitian. This occurs for Hamiltonians of exponentially many coupled quantum harmonic oscillators, e.g.,
Here, mj > 0 and κjk ≥ 0 for all j ∈ [n], k ∈ [n], are the masses and spring constants. For this H, the matrix of interaction strengths satisfies Γ ≽ 0. Considering a factorization Γ = BB†, for some matrix B, we can choose Γ1 = B and Γ2 = B†, and prove that HS is now Hermitian.
The Hamiltonian HS can be simulated efficiently when we have efficient access to the sparse matrix B. This is discussed in ref. 13 in great detail, which gives a quantum algorithm for simulating classical oscillators; both problems are equivalent due to a classical-quantum correspondence. Also, the initial shadow state can be prepared efficiently in some cases. For illustration, consider the case of a bosonic product state ρ where 〈Qj(0)〉 = 0 and \(\frac{1}{\sqrt{{m}_{j}}}\langle {P}_{j}(0)\rangle \ne 0\) is the same constant for all j ∈ [n]. Then, \(\left| \rho (0);S\right\rangle=\frac{1}{\sqrt{n}}{\sum }_{j=1}^{n}\left| j\right\rangle \left| j\right\rangle\) is a simple superposition state that can be prepared with \({{\mathcal{O}}}(\log (n))\) elementary gates. Like in the case of free-fermion systems, other shadow states can be considered by building upon this example. Hence, shadow Hamiltonian simulation enables the efficient simulation of the dynamics of exponentially large bosonic systems in many cases.
Shadow states can be used to compute properties of these systems efficiently. One example is estimating a semiclassical approximation to the (rescaled) kinetic or potential energies of a subset of masses or springs. This is essentially the same problem discussed in ref. 13, which is BQP-complete, and the reason why this is a semiclassical approximation here is because the expectation of a quadratic bosonic operator is not equal to the product of expectations of single operators in general. To go beyond this approximation, we could consider the set \(S={\{{O}_{m}{O}_{{m}^{{\prime} }}\}}_{1\le m\le M,1\le {m}^{{\prime} }\le M}\), which also satisfies the IP. With this choice we have \(\left| \rho ;S\right\rangle=\frac{1}{\sqrt{A}}{\sum }_{m,{m}^{{\prime} }}\langle {O}_{m}{O}_{{m}^{{\prime} }}\rangle \left| m,{m}^{{\prime} }\right\rangle\), where A > 0 is for normalization. It can be shown that the shadow state at time t can be obtained from the initial one by evolving with \({H}_{S}\otimes {{\mathbb{1}}}_{M}+{{\mathbb{1}}}_{M}\otimes {H}_{S}\) for time t. (Theorem 2 provides a more general result.) The energy of a subset I ⊆ [M] of quantum oscillators is \(\langle {H}_{I}\rangle=\frac{1}{2}{\sum }_{m\in I}\langle {({O}_{m})}^{2}\rangle\). This is also an overlap estimation problem, since \(\langle {H}_{I}\rangle=\frac{1}{2}\sqrt{A| I| }\langle {\psi }_{I}| \rho ;S\rangle\), where \(\left| {\psi }_{I}\right\rangle=\frac{1}{\sqrt{| I| }}{\sum }_{m\in I}\left| m,m\right\rangle\) is a unit quantum state. The normalization constant A can be Ω(n2) in general, since for sparse Γ the number of operators in S is Θ(n2), and all their expectations can be nonzero. However, for some initial states ρ that are of low energy, including some product states, we can prove that most expectations are zero and \(A={{\mathcal{O}}}(n)\). Then, if ∣I∣ ∝ n, the expectation 〈HI〉/n is an intensive property that can be obtained from the overlap 〈ψI∣ρ; S〉. More generally, if S contains bosonic operators of degree k > 2,we can perform other calculations like estimating the energies of interacting bosonic systems (non-quadratic Hamiltonians) in the corresponding states.
Qubit systems
The simplest example, which could be viewed as “free qubits”, is when the Hamiltonian H is a sum of local Pauli operators each acting non-trivially on only one qubit, i.e., S = {X1, Y1, Z1, …, Xn, Yn, Zn}. The IP is satisfied and HS is Hermitian due to the orthogonality of Pauli operators. The dimension of the shadow state is only M = 3n and we can encode the expectations of exponentially many qubits into a shadow state of exponential dimension, which uses only \({{\mathcal{O}}}(\log (n))\) many qubits. In this example the qubits do not interact, and hence the system might not be very interesting. A different example is when S contains all n-qubit Pauli operators. Specifically, for i, j ∈ {0, 1}n, let \({P}_{ij}: \! \!={X}_{1}^{{i}_{1}}{Z}_{1}^{{j}_{1}}\otimes \cdots \otimes {X}_{n}^{{i}_{n}}{Z}_{n}^{{j}_{n}}\) and let S ≔ {Pij: i, j ∈ {0, 1}n}. Pauli operators are orthogonal, implying Hermiticity of HS, and ∣S∣ = M = 4n. The shadow state is \(\left| \rho ;S\right\rangle=\frac{1}{\sqrt{A}}{\sum }_{i,j\in {\{0,1\}}^{n}}\langle {P}_{ij}\rangle \left| i,j\right\rangle\), where \(\langle {P}_{ij}\rangle={{\rm{tr}}}(\rho {P}_{ij})\) is the expectation. The normalization constant is \(A={\sum }_{i,j}| \langle {P}_{ij}\rangle {| }^{2}={2}^{n}{{\rm{tr}}}({\rho }^{2})\), being proportional to the purity of ρ.
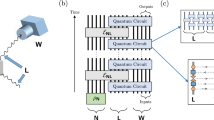
Let VS be the “Bell rotation”, which maps between the Bell basis and the standard basis; see Fig. 1. As we show in Supp. Note 3, the shadow state of a pure state \(\rho=\left| \psi \right\rangle \left\langle \psi \right|\) for this S is \(\left| \rho ;S\right\rangle={V}_{S}\left| \psi \right\rangle \otimes \left| \bar{\psi}\right\rangle\). We can then prepare the shadow state efficiently whenever we have an efficient circuit to prepare \(\left| \psi \right\rangle\). (This also gives an efficient circuit for \(\left| \bar{\psi}\right\rangle\) by complex conjugating all the elementary gates in the circuit for preparing \(\left| \psi \right\rangle\).) Similarly, it is possible to perform shadow Hamiltonian simulation since, for any unitary U, the shadow state corresponding to \(U\left| \psi \right\rangle\) is simply \(U\left| \psi \right\rangle \otimes \overline{U\left| \psi \right\rangle }\).

The two-qubit gates are CNOTs and H are Hadamard. When acting on n Bell pairs, these gates output a state in the computational basis.
Lie-algebraic systems
The case of Lie algebras is a natural one to consider in shadow Hamiltonian simulation because the IP is automatically satisfied. More precisely, a Lie algebra \({\mathfrak{g}}\) is a vector space with a Lie bracket binary operation \([\cdot,\cdot ]:{\mathfrak{g}}\times {\mathfrak{g}}\to {\mathfrak{g}}\). In our setting, the Lie bracket is simply the commutator between operators or matrices: [x, y] = xy − yx. Hence, if the Hamiltonian H belongs to a Lie algebra \({\mathfrak{g}}\), this implies that any basis of \({\mathfrak{g}}\) can be chosen as the set S of operators that satisfies the IP. Indeed, we have seen some examples already: the set of quadratic fermionic operators span the Lie algebra \({\mathfrak{so}}(2n)\), quadratic bosonic operators span the symplectic Lie algebra \({\mathfrak{sp}}(2n)\), and all Pauli operators span the Lie algebra \({\mathfrak{u}}({2}^{n})\). Other examples are spin systems with associated Lie algebras \({\mathfrak{su}}(2)\) or, more generally, \({\mathfrak{su}}(n)\). This provides a unifying framework for a broad class of situations where shadow Hamiltonian simulation is applicable. Specifically, when the dimension of the Lie algebra is polynomial in the system size, shadow Hamiltonian simulation is able to tackle quantum systems that are of exponential size.
Let S = {O1, …, OM} be the operator set and assume it spans the Lie algebra \({\mathfrak{g}}\). To apply shadow Hamiltonian simulation, we need to construct an HS that is also Hermitian. This HS is determined by the structure constants of \({\mathfrak{g}}\), which are the fjkl in the commutations \([{O}_{j},{O}_{k}]=\mathop{\sum }_{l=1}^{M}{f}_{jkl}{O}_{l}\). Hermiticity of HS can follow from the orthogonality of the Oj’s in finite-dimensional systems. Two assumptions ensure that HS can be efficiently simulated: i) having efficient sparse access to the structure constants, and ii) only a few (\({{\rm{polylog}}}(M)\)) terms in H do not commute with a given Oj and these terms can be efficiently computed. Additionally, many initial shadow states can be efficiently prepared. Examples are those of lowest-weight states \(\left| {{\rm{lw}}}\right\rangle\), generalizing the free vacuum in the fermionic case, and those corresponding to “generalized coherent” states of \({\mathfrak{g}}\). These are obtained as \({e}^{{\mathfrak{g}}}\left| {{\rm{lw}}}\right\rangle\), where \({e}^{{\mathfrak{g}}}\) is a unitary in the group induced by \({\mathfrak{g}}\), and generalize the Gaussian fermionic states discussed when \({\mathfrak{g}}\equiv {\mathfrak{so}}(2n)\). To be precise, when \({\mathfrak{g}}\) is a real Lie algebra spanned by antiHermitian operators, then \({e}^{{\mathfrak{g}}}\) is unitary. In this case, it is the antiHermitian operator iH the one that belongs to \({\mathfrak{g}}\). We give more details in Section 4.
Green’s functions and other correlators
Shadow Hamiltonian simulation can be extended to encode expectations of products of different time-dependent operators in the amplitudes of a quantum state. This is most relevant in the Heisenberg picture, where the time-dependent expectation of an operator O on the state ρ(t) is alternatively described as the expectation of a time-dependent operator O(t) on the initial state ρ(0). The evolution of the operator is given by Heisenberg’s equations of motion. More generally, we can consider products of operators at different times in the Heisenberg picture, e.g., \({O}_{1}(t){O}_{2}({t}^{{\prime} })\). Let H and S satisfy the IP and define the pure state
where \(\langle {O}_{m}(t){O}_{{m}^{{\prime} }}({t}^{{\prime} })\rangle\) are the expectations with respect to the initial state ρ, and A > 0 is for normalization. The following result, shown in Supp. Note 1, extends shadow Hamiltonian simulation to this scenario.
Theorem 2
The state \(\left| \rho ;S(t,{t}^{{\prime} })\right\rangle\) satisfies
We can then encode two-time correlators and Green’s functions in the amplitudes of a quantum state. To prepare \(\left| \rho ;S(t,{t}^{{\prime} })\right\rangle\) from \(\left| \rho ;S(0,0)\right\rangle\) efficiently on a quantum computer, it suffices for HS to be Hermitian and to have efficient sparse access to HS. The procedure involves evolving with HS acting on the first register for time t and evolving with the same HS acting on the second register for time \({t}^{{\prime} }\). In addition, it is often possible to prepare the initial state \(\left| \rho ;S(0,0)\right\rangle\) efficiently, if the set of initial expectations contains structure that can be expressed succinctly, similar to the examples discussed above.
Importantly, Theorem 2 can be generalized in two directions: i) we can encode higher order correlation functions \(\langle {O}_{{m}_{1}}({t}_{1})\ldots {O}_{{m}_{q}}({t}_{q})\rangle\), where all the \({O}_{{m}_{j}}\)’s are in the same operator set S and evolve under H for different times t1, …, tq, and ii) when the operators in the product belong to different operator sets S1, …, Sq, each evolving with their own distinct Hamiltonians H1, …, Hq, as long as the corresponding IPs between Sj and Hj are satisfied for all j.
Operators in the Heisenberg picture
In a different extension, we can encode a representation of the time-evolved operators themselves in the Heisenberg picture, rather than their expectations, without making reference to the state of the system. Consider the operator set S = {O1, …, OM} and let \(Z: \! \!=\mathop{\sum }_{m=1}^{M}{z}_{m}{O}_{m}\), where \({z}_{m}\in {\mathbb{C}}\) for all m ∈ [M]. The time-evolved version in the Heisenberg picture is Z(t) and, if the Hamiltonian H is time-independent, Heisenberg’s equation of motion is \(\frac{{{\rm{d}}}}{{{\rm{d}}}t}Z(t)={{\rm{i}}}[H,Z(t)]\). If H and S further satisfy the IP, we can express \(Z(t)=\mathop{\sum }_{m=1}^{M}{z}_{m}(t){O}_{m}\), where \({z}_{m}(t)\in {\mathbb{C}}\). These coefficients evolve according to
which is a direct consequence of Heisenberg’s equation of motion. The coefficients \({h}_{{m}^{{\prime} }m}\) are the entries of the matrix HS. If this is Hermitian, Eq. (9) is also a Schrödinger equation, and it is natural to consider the operator-vector mapping \(Z(t)\mapsto \left| Z(t)\right\rangle \propto {\sum }_{m=1}^{M}{z}_{m}(t)\left| m\right\rangle\). In this way, we can encode the time-evolved operator in a quantum state, and Eq. (9) implies
A quantum algorithm that prepares \(\left| Z(t)\right\rangle\) involves preparing the initial state \(\left| Z(0)\right\rangle\) and performing time evolution with the Hamiltonian \(\overline{{H}_{S}}\) for time t. The algorithm is efficient when these two steps can be implemented efficiently. The analysis can be extended to time-dependent Hamiltonians. In that case, it can be shown that the transformation that takes \(\left| Z(0)\right\rangle\) to \(\left| Z(t)\right\rangle\) is the evolution operator with the Hamiltonian \(\overline{{H}_{S}(t-s)}\), where the final time t is fixed and s is increased from 0 to t. This resembles the evolution of the operator in the Heisenberg picture that evolves backwards in time. More details are in Supp. Note 1, where we discuss the case of quantum circuits as well.
The state encoding a time-evolved operator can let us probe many interesting properties of the system. One example is operator growth, which relates to the phenomenon of quantum scrambling14,26,27,28,29,30. Suppose for simplicity that the set S consists of all Pauli operators Pij on n qubits. We can define an observable W which is diagonal in the computational basis; on basis element \(\left| i,j\right\rangle\), it takes value equal to the Hamming weight of the operator Pij, which counts the number of non-trivial Paulis and we denote wt(Pij). Measuring 〈Z(t)∣W∣Z(t)〉 will compute the expected weight at time t given by
Similar to Theorem 2, we can also consider the evolution of products of operators and two-time correlators by encoding them in quantum states.
The approach can also be applied for learning certain unitary oracles. For example, if S is again the set of all Pauli operators Pij on n qubits and the unitary that transforms S is a Clifford operation C, we can use this approach to study the evolution of the local Pauli operations X1, Z1, …, Xn, Zn. Each of these can be encoded in a corresponding 2n-qubit state, of a single amplitude 1 in a basis state corresponding to the local Pauli, and all other amplitudes are zero. The corresponding transformation on the 2n-qubit state will simply be a permutation, since C maps Pauli operators to other Pauli operators, i.e., it permutes the elements of S. A measurement after the evolution gives the transformation for the local Pauli operator, given as a sequence of 2n bits that specify all the n local Pauli operators in the Pauli product. Hence, with 2n experiments of this form, we obtain full knowledge of C. This requires 2n uses of each C and \(\bar{C}\), the complex conjugate. A similar approach is described in ref. 31. The analysis can be directly generalized to efficiently learn unitary oracles that map Pauli products to linear combinations of polynomially many Pauli products and beyond. Other examples are learning unitary oracles corresponding to evolutions of free-fermion or free-boson models, as long as the evolved (creation or annihilation) operators are mapped to linear combinations involving polynomially many operators. For all these cases, we only require that state tomography of the corresponding \(\left| Z(t)\right\rangle\)’s can be performed efficiently.
Quantum speedups in realistic situations
It was shown in ref. 13 that simulating exponentially-many classical harmonic oscillators is a BQP-hard problem. Since we recover this algorithm using shadow Hamiltonian simulation, this demonstrates that shadow Hamiltonian simulation is capable of providing an exponential quantum speedup in principle. In ref. 13 they also give an exponential oracle separation for the problem of simulating dynamics of coupled classical harmonic oscillators, which can also be solved using shadow Hamiltonian simulation. These systems involve “long-range” interactions, in which oscillators that are exponentially far apart can be coupled with a spring.
However, one can ask about quantum speedups in realistic physical geometries. In this case, properties like locality of interactions could be exploited, potentially enabling more efficient classical simulations of the dynamics. For example, suppose we have a system of harmonic oscillators or free fermions on a lattice in D = 3 spatial dimensions. Simulating time evolution within shadow Hamiltonian simulation has cost almost linear in the evolution time t and polylogarithmic in system size. Classically, one must only simulate the “lightcone” of the region of interest, with spacetime volume scaling as ~t4. Thus we achieve a quartic quantum speedup over classical algorithms such as finite-difference time domain (FDTD), which encodes the shadow state in a vector and simulates time evolution via matrix-vector multiplication. More generally, for lattices in D spatial dimensions, the size of the lightcone is \({{\mathcal{O}}}({t}^{D})\) and classical algorithms can have complexity \({{\mathcal{O}}}({t}^{1+D})\), while the complexity of shadow Hamiltonian simulation is \(\tilde{{{\mathcal{O}}}(t)}\).
Discussion
We devised a novel approach to quantum simulation that uses compressed versions of the full quantum states. This shadow Hamiltonian simulation approach allows us to encode limited information about a system’s quantum state, like the expectations of a relevant set of operators at any time, in the amplitudes of a different “shadow state”. We can then exploit the exponential dimension of the shadow state and encode, for example, the expectations of operators acting on systems of exponential size. By doing so we unveiled applications to quantum systems like fermions and bosons with an exponential number of modes. For these, we described computations that can be carried efficiently via shadow Hamiltonian simulation, while these computations are hard for classical or traditional quantum approaches, as preparing the full states would require exponential resources. Note that while free-boson and free-fermion systems are integrable and efficient classical solutions are possible, that efficiency is lost when analyzing systems that are exponentially large, as considered in this work.
Additionally, we demonstrated how the ideas underlying shadow Hamiltonian simulation can be applied to two other problems. In one problem, we described how to encode the expectations of two-time correlators or other products of time-dependent operators in a different quantum state. In the other problem we described an approach for encoding operators in the Heisenberg picture in quantum states, without referencing to the state of the system. These developments enable the solution to other problems; an example is studying the growth of the light cone associated with an evolving operator.
Shadow Hamiltonian simulation also shares features of prior results and can improve them, further highlighting the potential of our approach. For example, first-quantization methods enable the simulation of exponentially many fermionic modes as well. However, known approaches that use first quantization (cf.,12) require one register per fermion, and the number of registers can be exponentially large when the number of fermions is exponential (e.g., at half filling). In contrast, shadow Hamiltonian simulation uses a number of registers that depends on the set of operators S, and not on the number of fermions. While it might be possible to adapt first-quantized methods to encode partial information on the fermionic state using fewer registers (e.g., k registers to encode the k-RDM), the corresponding fermionic states would often be highly mixed and our approach based on pure shadow states still appears more powerful. For example, it is possible to prove an exponential separation (in the number of modes) in sample complexity between the cases where access to copies of the shadow states is given and where copies of the mixed states that encode the k-RDM is given. Additionally, shadow Hamiltonian simulation can deal with free-fermion Hamiltonians that are not number preserving, which is not the case of known first-quantization methods. This is useful for studying models like, for example, the BCS Hamiltonian that appears in superconductivity. Nevertheless, a main feature of first-quantization methods is that they can simulate interacting fermionic Hamiltonians, but their scaling can be polynomial in the number of modes.
Also, there is an inherent relation between the quantum algorithm of ref. 13 for simulating exponentially many coupled classical oscillators and shadow Hamiltonian simulation. That quantum algorithm shares similar features in that the coordinates (position and momentum) of the oscillators are also encoded in the amplitudes of a quantum state, which can be shown to evolve unitarily. While those are classical variables, their dynamics is similar to the dynamics of the expectations of the corresponding operators of exponentially many coupled quantum oscillators. This is a consequence of Ehrenfest’s theorem, which relates classical and quantum evolution, applied to quadratic free-boson systems. Nevertheless, with shadow Hamiltonian simulation we can perform more complex calculations that involve expectations of higher-order correlations in bosonic systems, going beyond ref. 13.
We anticipate several future directions. For instance, we mentioned that quantum algorithms for differential equations might be used when the IP is satisfied but HS is not Hermitian, and understanding when such algorithms are efficient would be important. Another potential direction is the simulation of open quantum system dynamics, and whether shadow states can be used to perform this simulation more efficiently. Also, many classical systems have an underlying Lie algebra structure, and it would be interesting to unveil other examples whose classical dynamics can be efficiently simulated on a quantum computer using shadow states. Furthermore, it might be possible to address interacting systems where the IP is not satisfied by considering products of operators in S up to some degree (cutoff), and attempt an approximate simulation using shadow states.
Methods
For shadow Hamiltonian simulation to be efficient, the simulation of HS has to be implemented efficiently and the initial shadow state \(\left| \rho (0);S\right\rangle\) has to be prepared efficiently. These take place in many interesting cases, and we provide the conditions and methods for efficiency in the examples analyzed.
Efficient Hamiltonian simulation
Shadow Hamiltonian simulation involves the simulation of HS for time t and, to this end, we can use known techniques for standard Hamiltonian simulation like quantum signal processing7. In general, we will consider cases where the number of distinct Om’s in S is exponentially large in some problem size, or where the Hamiltonian H is also a sum of exponentially many such operators. Since HS is determined from H and S, specifying it and simulating it in general will require exponential complexity. Nevertheless, as we are interested in problem instances that can be simulated efficiently, we will consider those with a succinct presentation for HS that allows for efficient simulation. By efficient simulation we mean an algorithm of complexity poly(t) and \({{\rm{polylog}}}(M)\), and also polynomial in some norm of HS.
Quantum signal processing and related efficient approaches for standard Hamiltonian simulation assume access to a “block-encoding” of the Hamiltonian. This is a unitary operator acting on an enlarged space that contains the Hermitian operator HS/Λ in one of its blocks. The constant Λ > 0 depends on some norm of HS and what type of access to HS is given. The optimal (query) complexity of such Hamiltonian simulation algorithms is \({{\mathcal{O}}}(t\Lambda+\log (1/\epsilon ))\), where ϵ > 0 is the error. Hence, if the block-encoding can be constructed efficiently, the algorithm is efficient as desired. To this end, a commonly used access model for Hamiltonian simulation is the sparse matrix model. In this model, the entries of a d-sparse matrix A can be accessed efficiently as follows. There is a black-box that outputs the (j, k)th entry of the matrix on input (j, k). The black-box also outputs the locations of the d nonzero entries in every row or column. Using this black-box a constant number of times, it is possible to build the block-encoding of A/Λ, where \(\Lambda : \! \!=d\parallel A{\parallel }_{\max }\) in this case. This model can be adapted to the shadow Hamiltonian simulation approach. Basically, what we need is for HS to be d-sparse and efficiently accessible as explained. Three sufficient conditions that enable this are: i) that the number of operators in the linear combination \([H,{O}_{m}]={\sum }_{{m}^{{\prime} }}{h}_{m{m}^{{\prime} }}{O}_{{m}^{{\prime} }}\) is at most d and \(d={{\rm{polylog}}}(M)\) or constant, ii) that each \({h}_{m{m}^{{\prime} }}\) can be computed efficiently on input \((m,{m}^{{\prime} })\), and iii) that the \({m}^{{\prime} }\) corresponding to the ℓth nonzero coefficient \({h}_{m{m}^{{\prime} }}\) in the linear combination can also be computed efficiently, i.e., \([H,{O}_{m}]={\sum }_{\ell=1}^{d}{h}_{m{m}^{{\prime} }(\ell )}{O}_{{m}^{{\prime} }(\ell )}\). In this case, \(\parallel {H}_{S}{\parallel }_{\max }=\mathop{\max }_{m,{m}^{{\prime} }}| {h}_{m,{m}^{{\prime} }}|\). Furthermore, the block-encoding of \({H}_{S}/(d\parallel {H}_{S}{\parallel }_{\max })\) can be constructed efficiently under the conditions, giving an efficient Hamiltonian simulation algorithm by means of, e.g., quantum signal processing.
We explain how to meet the three conditions for the examples discussed in this article, but essentially the same techniques can be applied more broadly. Assume S is the set of quadratic fermionic operators. The commutation between two such operators Om and \({O}_{{m}^{{\prime} }}\) gives a linear combination of at most two other quadratic fermionic operators. Then, if H is a free-fermion Hamiltonian, we can assume that at most p terms in H do not commute with a given Om, and hence d = 2p. This occurs if the matrix of interaction strengths Γ is \({d}^{{\prime} }\)-sparse, so that \(p\le 2{d}^{{\prime} }\): two quadratic fermionic operators cicj and ckcl with non overlapping indices commute. Additionally, the entries of HS are proportional to the entries of Γ, so that \(\parallel {H}_{S}{\parallel }_{\max }\propto \parallel \Gamma {\parallel }_{\max }\). Given sparse access to Γ, it is also possible to compute and find the locations of all nonzero elements in the commutator [H, Om], by explicitly computing the p nonzero commutations. This requires accessing \(\Gamma,{{\mathcal{O}}}(p)\) times, resulting in an efficient Hamiltonian simulation algorithm of complexity \({{\mathcal{O}}}({d}^{{\prime} }(t{d}^{{\prime} }\parallel \Gamma {\parallel }_{\max }+\log (1/\epsilon )))\). This is the number of queries to Γ and can be improved with a refined analysis.
A similar analysis applies to the case of free-boson systems, showing that if the matrix of interaction strengths Γ is sparse and can be accessed efficiently, then HS can be simulated efficiently. A more detailed study to do this simulation is given in ref. 13, which assumes access to a mass matrix whose entries are the masses mj, and a \({d}^{{\prime} }\)-sparse spring constant matrix whose entries are the spring constants κjk. The (query) complexity of simulating HS in this case was shown to be \({{\mathcal{O}}}(t\sqrt{{d}^{{\prime} }}\Lambda+\log (1/\epsilon ))\), where \(\Lambda=\mathop{\max }_{i,j,k}\sqrt{{\kappa }_{jk}/{m}_{i}}\).
The case of qubits, where S is the set of all Pauli products, follows directly from the relation between the shadow state and \(\left| \psi \right\rangle \otimes \overline{\left| \psi \right\rangle }\). This implies \({H}_{S}={V}_{S}(H\otimes {{\mathbb{1}}}_{{2}^{n}}+{{\mathbb{1}}}_{{2}^{n}}\otimes \bar{H}){({V}_{S})}^{{\dagger} }\), where VS maps between basis states and Bell states and can be implemented with \({{\mathcal{O}}}(n)\) two-qubit gates. Then, HS can be efficiently simulated if H can, by using standard Hamiltonian simulation with H and \(\bar{H}\). For d-sparse H, the complexity is \({{\mathcal{O}}}(td\parallel H{\parallel }_{\max }+\log (1/\epsilon ))\).
Last, for the case of Lie algebras, the Hamiltonian is H = ∑kαkOk, with \({\alpha }_{k}\in {\mathbb{C}}\) and \({O}_{k}\in {\mathfrak{g}}\). We can satisfy the three conditions outlined above as long as [Oj, Ok] = ∑lfjklOl is a linear combination of at most \({d}^{{\prime} }\) operators, and the number of terms in H that do not commute with any Oj is at most p. If we have access to a black-box that, given j, outputs all the p terms in H that do not commute with Oj together with their indices, and another black-box that, given (j, k), outputs all the \({d}^{{\prime} }\) nonzero terms in ∑lfjklOl together with their indices, we can use these black boxes \({{\mathcal{O}}}(p{d}^{{\prime} })\) times to create access to d-sparse HS, where \(d\le p{d}^{{\prime} }\). This generalizes the case of quadratic fermionic operators in a natural way. The (query) complexity for simulating HS in the case of Lie algebras is \({{\mathcal{O}}}(t\Lambda+\log (1/\epsilon ))\), where \(\Lambda=p{d}^{{\prime} }\parallel {H}_{S}{\parallel }_{\max }\), and \(\parallel {H}_{S}{\parallel }_{\max }\le \mathop{\max }_{k}| {\alpha }_{k}| {\max }_{jkl}| {f}_{jkl}|\).
Efficient preparation of some initial shadow states
We also seek a procedure that prepares the initial shadow state \(\left| \rho (0);S\right\rangle\) efficiently. This is not always possible, but for many interesting states that can be expressed succinctly, efficient quantum circuits might be constructed.
First, we can consider a model where a black-box unitary computes the expectations 〈Om〉 on input \(\left| m\right\rangle\). Starting from a superposition state like \(\frac{1}{\sqrt{M}}\mathop{\sum }_{m=1}^{M}{\alpha }_{m}\left| m\right\rangle,{\sum }_{m}| {\alpha }_{m}{| }^{2}=1\), we can use the black-box and apply a conditional rotation to map
where \(\left| \rho ;{S}^{\perp }\right\rangle\) is orthogonal to \(\left| 0\right\rangle \left| \rho ;S\right\rangle\) and x ≥ 0 is the overlap. Standard techniques like amplitude amplification can be then used to distill \(\left| \rho ;S\right\rangle\) from this state with complexity \({{\mathcal{O}}}(1/x)\). The approach is efficient as long as \(1/x={{\mathcal{O}}}({{\rm{polylog}}}\,M)\).
Next we consider the case of fermions, where S is the set of quadratic fermionic operators. The free vacuum \(\rho (0)=\rho=\left| {{\rm{vac}}}\right\rangle \left\langle {{\rm{vac}}}\right|\) is the pure state containing no fermions. In this state, the expectations of quadratic Majorana operators are
This follows from the relation between Majorana fermions and bare (free) fermions, such that \({c}_{2j-1}: \! \!={a}_{j}^{{\dagger} }+{a}_{j}\) and \({c}_{2j}: \! \!={{\rm{i}}}({a}_{j}^{{\dagger} }-{a}_{j})\) for all j ∈ [n], where \({a}_{j}^{{\dagger} }\) (aj) are the fermionic creation (annihilation) operators of the bare fermions. The vacuum state satisfies \({a}_{j}\left| {{\rm{vac}}}\right\rangle=0\) for all j and also \(\left\langle {{\rm{vac}}}\right| {a}_{j}{a}_{j}^{{\dagger}}\left| {{\rm{vac}}}\right\rangle =\left\langle {{\rm{vac}}}\right| (1-{a}_{j}^{{\dagger}}{a}_{j})\left| {{\rm{vac}}}\right\rangle =1\). The corresponding shadow state with respect to S is (up to a global phase)
This state has a simple form, i.e., it is an equal superposition over basis states and can be prepared on a quantum computer in time \({{\mathcal{O}}}(\log (n))\) using elementary gates. It is equivalent to the shadow state corresponding to the completely filled state, which is the state with one fermion in every mode. This is implied by the fact that all operators in S change sign under a particle-hole transformation, which places a fermion if the mode is empty or removes it if the mode is occupied32: it maps \({a}_{j}^{{\dagger} }\mapsto {a}_{j}\) and \({a}_{j}\mapsto {a}_{j}^{{\dagger} }\). More generally, for this choice of \(S={\{{c}_{j}{c}_{k}\}}_{1\le j < k\le n}\), the shadow state of any ρ is invariant under the particle-hole transformation (up to a global sign). This property can be useful to identify other shadow states that can also be prepared efficiently. Indeed, other examples of shadow states that can be prepared efficiently are those corresponding to fermionic product states \(\left| {\psi }_{I}\right\rangle = {\prod }_{j\in I}{a}_{j}^{{\dagger} }\left| {{\rm{vac}}}\right\rangle ,I\subseteq [n]\), that contains one fermion in the modes I and no fermions elsewhere. These can be obtained from Eq. (14) by simply changing some signs of the amplitudes, which can be done efficiently if we have access to an oracle that specifies I efficiently. The shadow states of more general fermionic Gaussian states (Slater determinants) \(\left| \phi \right\rangle\) could be prepared, for example, by means of Thouless’s theorem33, which asserts that \(\left| \phi \right\rangle\) can be obtained as \({e}^{-{{\rm{i}}}\tilde{H}}\left| {\psi }_{I}\right\rangle\). Here, \(\tilde{H}\) is also a free-fermion Hamiltonian. If \(\tilde{H}\) can be accessed efficiently as explained above, then the corresponding Hamiltonian \({\tilde{H}}_{S}\) required for mapping shadow states can also be implemented efficiently. In general, there will be other shadow states that can also be prepared efficiently, and which do not necessarily correspond to fermionic Gaussian states.
The efficient preparation of certain shadow states for bosonic systems is already discussed in Section 2. For qubit systems, if \(\rho=\left| \psi \right\rangle \left\langle \psi \right|\) is pure, shadow states with respect to the set S of all Pauli operators are a simple transformation of \(\left| \psi \right\rangle \otimes \overline{\left| \psi \right\rangle }\): \(\left| \rho ;S\right\rangle={V}_{S}\left| \psi \right\rangle \otimes \overline{\left| \psi \right\rangle }\). These can be efficiently prepared as long as \(\left| \psi \right\rangle\) (and \(\overline{\left| \psi \right\rangle }\)) can be efficiently prepared.
Last, for the case of Lie algebras, we generalize the case of fermions. Assume further that the Lie algebra \({\mathfrak{g}}\) is compact and semisimple. This enables us to present \({\mathfrak{g}}\) in the Cartan-Weyl decomposition. The Cartan subalgebra is a (maximal) set of commuting operators and the other terms are “raising” or “lowering” operators, playing a similar role to the fermionic creation and annihilation operators. There is a special lowest-weight state \(\left| {{\rm{lw}}}\right\rangle\) –a generalization of the free vacuum state of fermions– that has the following properties: it is an eigenstate of all diagonal operators in the Cartan subalgebra, and it is annihilated by all lowering operators. If hi, i ∈ [r], are the diagonal operators, then \({h}_{i}\left| {{\rm{lw}}}\right\rangle={e}_{i}\left| {{\rm{lw}}}\right\rangle\), and the shadow state of \(\left| {{\rm{lw}}}\right\rangle\) is
The eigenvalues ei are purely imaginary and A = ∑i∣ei∣2 is a normalization constant, which can often be computed efficiently. In principle, r can be exponentially large. Nevertheless, the shadow state might be prepared efficiently if the ei’s are described succinctly, which turns out to be the case in many examples. For example, in free fermions, the relavant algebra of quadratic fermionic operators is \({\mathfrak{so}}(2n)\). The lowest-weight state of \({\mathfrak{so}}(2n)\) is the free vacuum, where all eigenvalues of the diagonal operators are − 1. As we discussed, the shadow state \(\left| \rho ;S\right\rangle\) in this case is a simple equal superposition state.
Data availability
No new data was generated or analyzed in this work; data availability is not applicable.
References
Lloyd, S. Universal quantum simulators. Science 273, 1073–1078 (1996).
Somma, R. D., Ortiz, G., Gubernatis, J. E., Knill, E. & Laflamme, R. Simulating physical phenomena by quantum networks. Phys. Rev. A 65, 042323 (2002).
Berry, D. W., Ahokas, G., Cleve, R. & Sanders, B. C. Efficient quantum algorithms for simulating sparse Hamiltonians. Comm. Math. Phys. 270, 359 (2007).
Wiebe, N., Berry, D., Høyer, P. & Sanders, B. C. Higher order decompositions of ordered operator exponentials. J. Phys. A: Math. Theor. 43, 065203 (2010).
Childs, A. M. & Wiebe, N. Hamiltonian simulation using linear combinations of unitary operations. Quantum Inf. Comput. 12, 901–924 (2012).
Berry, D. W., Childs, A. M., Cleve, R., Kothari, R. & Somma, R. D. Simulating Hamiltonian dynamics with a truncated Taylor series. Phys. Rev. Lett. 114, 090502 (2015).
Low, G. H. & Chuang, I. L. Optimal Hamiltonian simulation by quantum signal processing. Phys. Rev. Lett. 118, 010501 (2017).
Low, GuangHao & Chuang, I. L. Hamiltonian simulation by qubitization. Quantum 3, 163 (2019).
Campbell, E. Random compiler for fast Hamiltonian simulation. Phys. Rev. Lett. 123, 070503 (2019).
Zlokapa, A. & Somma, R. D. Hamiltonian simulation for low-energy states with optimal time dependence. Quantum 8, 1449 (2024).
Grüneis, A., Shepherd, J. J., Alavi, A., Tew, D. P., and Booth, G. H. Explicitly correlated plane waves: accelerating convergence in periodic wavefunction expansions. J. Chem. Phys. 139, 084112 (2013).
Su, Y., Berry, D., Wiebe, N., Rubin, N. & Babbush, R. Fault-tolerant quantum simulations of chemistry in first quantization. PRX Quantum 4, 040332 (2021).
Babbush, R., Berry, D. W., Kothari, R., Somma, R. D. & Wiebe, N. Exponential quantum speedup in simulating coupled classical oscillators. Phys. Rev. X 13, 041041 (2023).
Mi, X. et al. Information scrambling in computationally complex quantum circuits. Science 374, 1479 (2021).
Aaronson, S. et al. Shadow tomography of quantum states. In Proceedings of the 50th annual ACM SIGACT Symposium on Theory of Computing (STOC 2018), 325–338, https://doi.org/10.1145/3188745.3188802 (2018).
Berry, D. W. High-order quantum algorithm for solving linear differential equations. J. Phys. A: Math. Theor. 47, 105301 (2014).
Childs, A. M., Liu, J.- P. & Ostrander, A. High-precision quantum algorithms for partial differential equations. Quantum 5, 574 (2021).
Takahashi, M. et al. Thermodynamics Of One-dimensional Solvable Models. Cambridge University Press, (2005).
Tong, D. et al. The quantum hall effect: TIFR infosys lectures. arXiv https://doi.org/10.48550/arXiv.1606.06687 (2016).
Barouch, E. & McCoy, B. M. Statistical mechanics of the XY model. II. Spin-correlation functions. Phys. Rev. A 3, 786 (1971).
Rubin, N., Babbush, R. & McClean, J. Application of fermionic marginal constraints to hybrid quantum algorithms. N. J. Phys. 20, 053020 (2018).
Knill, E., Ortiz, G. & Somma, R. D. Optimal quantum measurements of expectation values of observables. Phys. Rev. A 75, 012328 (2007).
Bogoliubov, N. On the theory of superfluidity. J. Phys. 11, 23 (1947).
Scully, M. O. & Zubairy, M. S. Quantum Optics. Cambridge University Press, (1997).
Barthe, A., Cerezo, M., Sornborger, A. T., Larocca, M. & García-Martín, D. Gate-based quantum simulation of gaussian bosonic circuits on exponentially many modes. Phys. Rev. Lett. 134, 070604 (2025).
Schuster, T. & Yao, N. Y. Operator growth in open quantum systems. Phys. Rev. Lett. 131, 160402 (2023).
Swingle, B., Bentsen, G., Schleier-Smith, M. & Hayden, P. Measuring the scrambling of quantum information. Phys. Rev. A 94, 040302 (2016).
Landsman, K. A. et al. Verified quantum information scrambling. Nature 567, 61–65 (2019).
Joshi, M. K. et al. Quantum information scrambling in a trapped-ion quantum simulator with tunable range interactions. Phys. Rev. Lett. 124, 240505 (2020).
Blok, M. S. et al. Quantum information scrambling on a superconducting qutrit processor. Phys. Rev. X 11, 021010 (2021).
Low, R. A. Learning and testing algorithms for the Clifford group. Phys. Rev. A–., Mol., Optical Phys. 80, 052314 (2009).
Zirnbauer, M. R. Particle-hole symmetries in condensed matter. J. Math. Phys. 62, 021101 (2021).
Blaizot, J.- P. & Ripka, G. Quantum theory of finite systems. MIT Press, (1986).
Acknowledgements
We thank Cristian Batista, Kipton Barros, David Gosset, Robert Huang, William Huggins, Stephen Jordan, Marika Kieferova, Nicholas Rubin, and Nathan Wiebe for discussions.
Author information
Authors and Affiliations
Contributions
R.D.S., R. King, R. Kothari, T.E.O., R.B. developed the theoretical formalism, contributed to the analysis of results, and to the writing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing interests that could have influenced the work reported in this paper.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Somma, R.D., King, R., Kothari, R. et al. Shadow hamiltonian simulation. Nat Commun 16, 2690 (2025). https://doi.org/10.1038/s41467-025-57451-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-57451-z
