Announcing surya - a multilingual text line detection model for documents. It gives you accurate line-level bboxes and column breaks.
Find it here - github.com/VikParuchuri/s… .
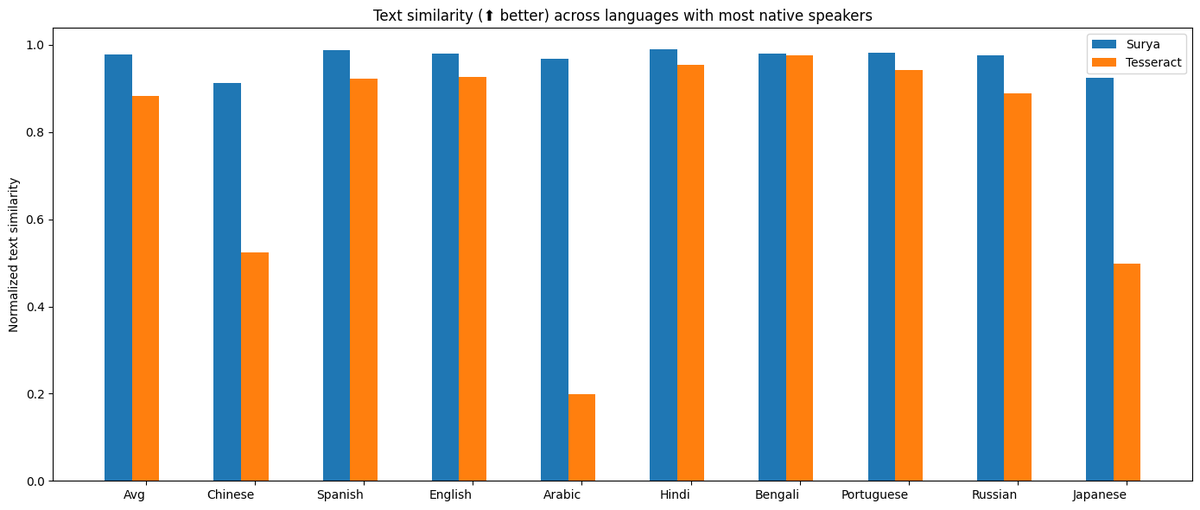
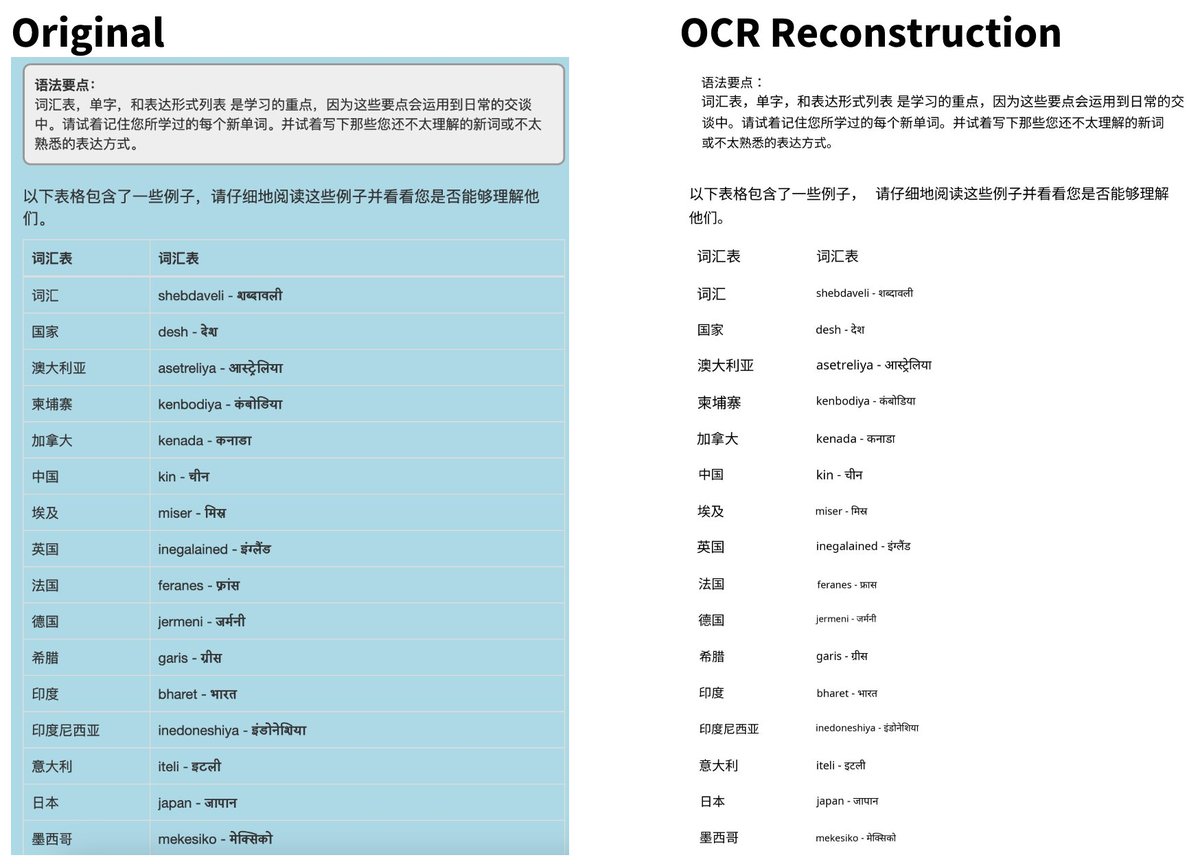
Announcing surya OCR - text recognition in 93 languages. It outperforms tesseract in almost all languages, often by large margins.
Find it here - github.com/VikParuchuri/s… .
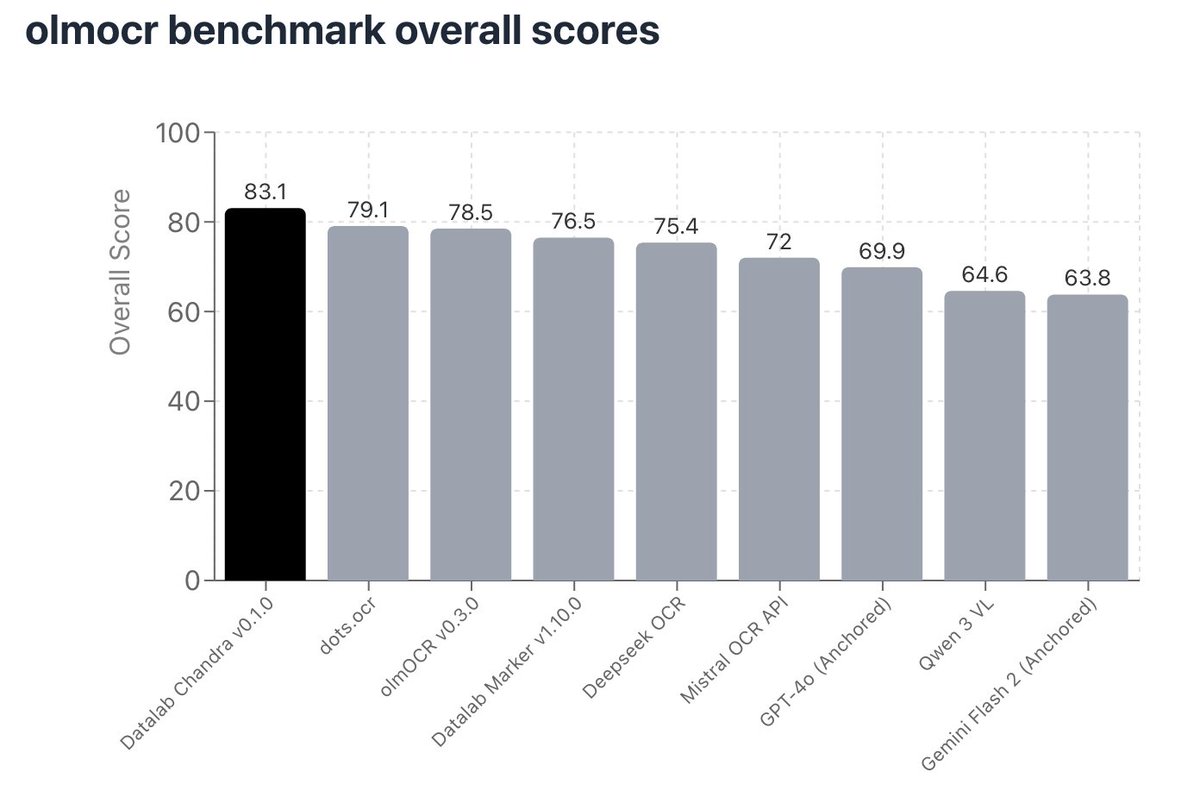
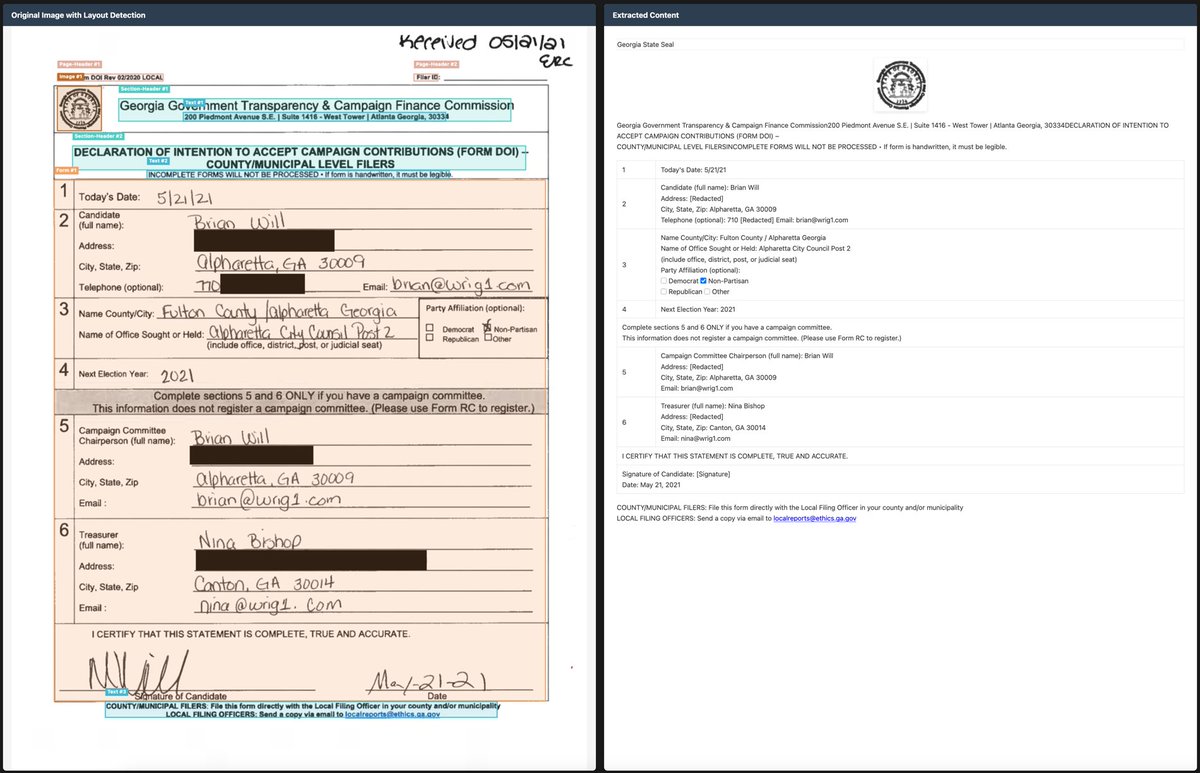
I'm excited to announce that Chandra OCR is open source!
- Full layout information
- Extracts and captions images and diagrams
- Strong handwriting, form, table support
- Works with transformers and vLLM
I'm starting a company, Datalab:
- Task-specific models that outperform frontier LLMs and existing tools
- Examples: my projects marker and surya (25k GH stars) with task-specific arch
- Goal: Train models, open source as much as possible, do hosted inference and on-prem
I wrote a blog post on going from not knowing anything about deep learning last year to training state of the art OSS models - vikas.sh/post/how-i-got… .
Hope it helps you.
tldr; read the deep learning book, implemented papers + taught, built open source tools
Announcing Surya OCR 2! It uses a new architecture and improves on v1 in every way:
- OCR with automatic language detection for 93 languages (no more specifying languages!)
- More accurate on old/noisy documents
- 20% faster
- Basic English handwriting support
I'm excited to ship marker - a pdf to markdown converter that is 10x faster than nougat, more accurate outside arXiv, and has low hallucination risk. Marker is optimized for throughput, like converting LLM pretrain data.
Find it here - github.com/VikParuchuri/m… .
We've improved marker (PDF -> markdown) a lot in 3 months - accuracy and speed now beat llamaparse, mathpix, and docling.
We shipped:
- llm mode that augments marker with models like gemini flash
- improved math, w/inline math
- links and references
- better tables and forms
Cool to see a 500M param model I trained myself do better than Google cloud vision, Claude, and GPT-4V on this task. (look at the thread for the results)
It's a relatively narrow one (OCR), but feels nice to see that small open source models still have a place.
It's weird how we live in an age of miracles with respect to AI/ML, and yet when I want to extract some text from a screenshot the best (very bad) option is tesseract, last updated ~7 years ago.
Announcing Surya Table Recognition! It uses a new architecture to outperform table transformer, the current SoTA open source model.
- Recognizes table rows, columns, and cells
- Works with complex layouts and rotated tables
- Supports any language
- Runs locally