The team has been working hard bringing upgrades to Grok Imagine in the past month. We're rolling out the 1st model upgrade today, with more to come. Try it out and join us if you want to help accelerate!
🚀We are thrilled to release LLaVA-1.6, with improved reasoning, OCR, and world knowledge. It supports higher-res inputs, more tasks, and exceeds Gemini Pro on several benchmarks! 🤯 It maintains the data efficiency of LLaVA-1.5, and LLaVA-1.6-34B is trained ~1 day with 32 A100s.
🚀 LLaVA-1.5 is out! Achieving SoTA on 11 benchmarks, with simple mods to original LLaVA! Utilizes merely 1.2M public data, trains in ~1 day on a single 8-A100 node, and surpasses methods that use billion-scale data.
🔗arxiv.org/abs/2310.03744
🧵1/5
🚀Exciting news! Thanks to the LLaVA-Lightning, we're releasing LLaVA-MPT today, just a day after the release of (commerically usable) MPT from @MosaicML! Built on MPT-7B-Chat, it only takes 3 hours to open up the eyes of MPT models to grasp and reason about the visual world. 🧵
🧵1/ Exciting news! We've just released a major update for LLaVA, our open-source large multimodal model, with support for LLaMA-2, LoRA training with academia GPUs, higher resolution (336x336), 4-/8- inference, and more! 🚀🌋
Grok can see👀!
Excited to share that I joined @xai last month, and it’s such a pleasure to work with a small, focused team and see how fast we can move!
This is just the beginning.
🚀Introducing LLaVA Lightning: Train a lite, multimodal GPT-4 with just $40 in 3 hours! With our newly introduced datasets and the efficient design of LLaVA, you can now turbocharge your language model with image reasoning capabilities, in an incredibly affordable way.🧵
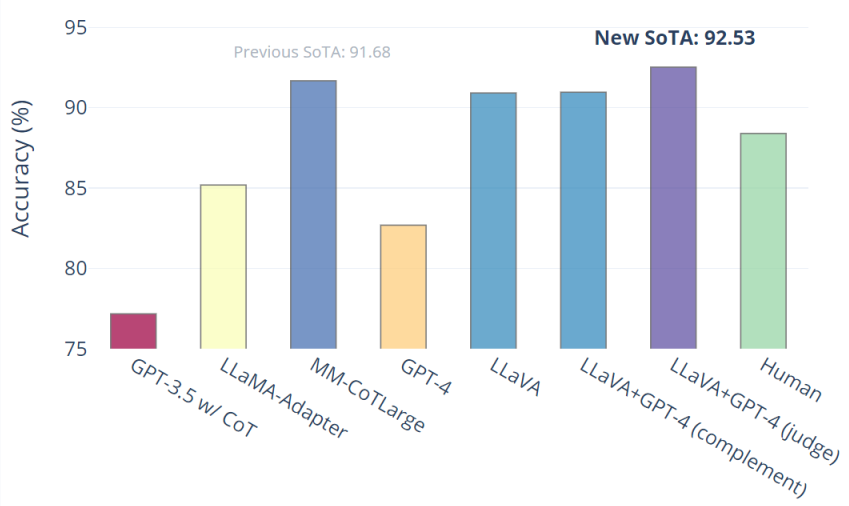
🔥Visual Instruction Tuning with GPT-4 !
We release LLaVA, a Language-and-Vision Assistant that exhibits some near multimodal GPT-4 level capabilities:
- 🤖Visual Chat: 85% relative score of GPT-4
- 🧪Science QA on reasoning: New SoTA 92.53%, beats multimodal chain-of-thoughts
We’ve been working hard and with this rate of progress, we’ll likely have prototypes covering almost all aspects for video gen ready by end of this year. And next year would be even more fun! Join us!!
I'll be in Seattle 6/17-21 for #CVPR2024. If you're interested in multimodal (image/video/audio; understanding/generation), let's chat! @xai is hiring and apply at x.ai/career if you want to build multimodal models on the largest GPU cluster ever built!
🚀 LLaVA-1.5 is out! Achieving SoTA on 11 benchmarks, with simple mods to original LLaVA! Utilizes merely 1.2M public data, trains in ~1 day on a single 8-A100 node, and surpasses methods that use billion-scale data.
🔗arxiv.org/abs/2310.03744
🧵1/5