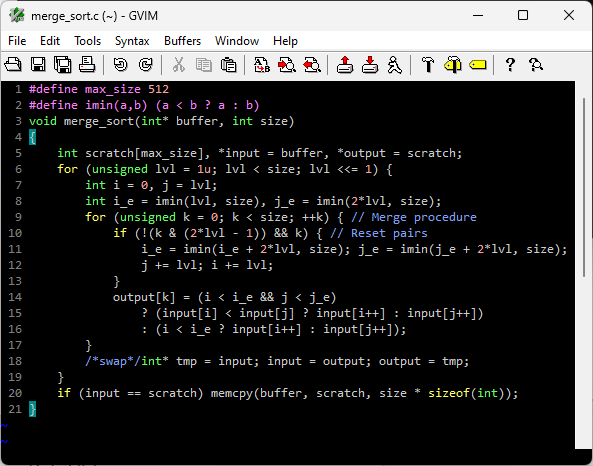
3 lines of code in c, no expensive allocations, handful of instructions easier to understand.
int begin = 0, end = 0, queue[max_sz];
void push(int e){queue[(end++) % max_sz]=e;}
int pop(){return queue[(begin++)%max_sz];}
Big tech ai slop is driven by web dudes, who worship abstraction.
Efficient GPU programming requires thinking about memory, and webdudes are allergic to memory.
Finally might be an exaggeration. I’m skeptical that all the Python folks in OpenAI will adapt and start becoming low level GPU optimizers, or letting themselves be bossed around by us. It’s hard to change the culture.
Don't miss out our #Siggraph2020 presentation about the lighting of Need for Speed in Frostbite.
We will cover Global Illumination, Materials and Reflections!
This was a lot of hard work, and we really hope you guys enjoy it :)
s2020.siggraph.org/presentation/?…
Demo showcasing GPU resident drawer, GPU occlusion culling and the new STP upscaler. Tech that my team (Weta realtime) has been relentlessly working on. More details coming soon :)
Check out Fantasy Kingdom in Unity 6, a stylized environment showcasing the latest capabilities for rendering, lighting, and scaling richer worlds, with significant performance improvements. This demo is a modified and expanded version of "Fantasy Kingdom" by @SyntyStudios (2/5)
Merge sort in C, roughly same amount of lines. And relatively trivial code.
No expensive recursion.
No expensive allocations. Only a simple scratch buffer.
Easily parallelizable.
Very cache friendly.
gist.github.com/kecho/b3abcecd…
Today I am releasing Noice. github.com/kecho/Noice
A short side project written in #ISPC for windows & linux.
It is a command line 2d/3d texture noise generation utility
I hope its something useful, and feel free to try it. Binaries: github.com/kecho/Noice/re…
Today concludes my last day at EA, after almost 10 years. Its bittersweet. I will miss everyone who made my experience so pleasant.
On to the next adventure: I'll be joining
@unity3d
starting on January. Now time to relax...
progress on my compute rasterizer (side proj)
github.com/kecho/grr
I am able to do everything on python + hlsl! also 5ms in a 2070 on the stanford dragon (2mil vertices) at 4k. More optimizations to come!
I have also integrated parts of implot and more imgui functionality
Don't do separable in compute, do it pixel, way faster.
To match pxl, read & write in groups of 4 use Morton pattern. To beat pxl, no separable; MIP chain first, 4 mips at a time use lds. Poisson disk kernel, MIP index for large jumps. For large kernels prefer gaussian pyramid.
Writing compute shaders for godot compositor effects has been pretty tiresome so I spent the past few days thinking about and writing an interpreter for a wrapper language for glsl compute shaders to allow multiple kernels in one shader file
Since the godot shader compiler
Stable radix sorting in the GPU (8 bits per radix). Not many accessible resources to do it stable. Here it goes:
1. Count & Scatter
2. Prefix batch table
3. Global Prefix
4. Scatter Output
5. Repeat 1-4 for each radix.
(Details & code in thread)
You can use mine, which is multi pass and handles arbitrary sizes as well as indirect, and uses wave intrinsics.
There's also a new one from amd that is single pass!
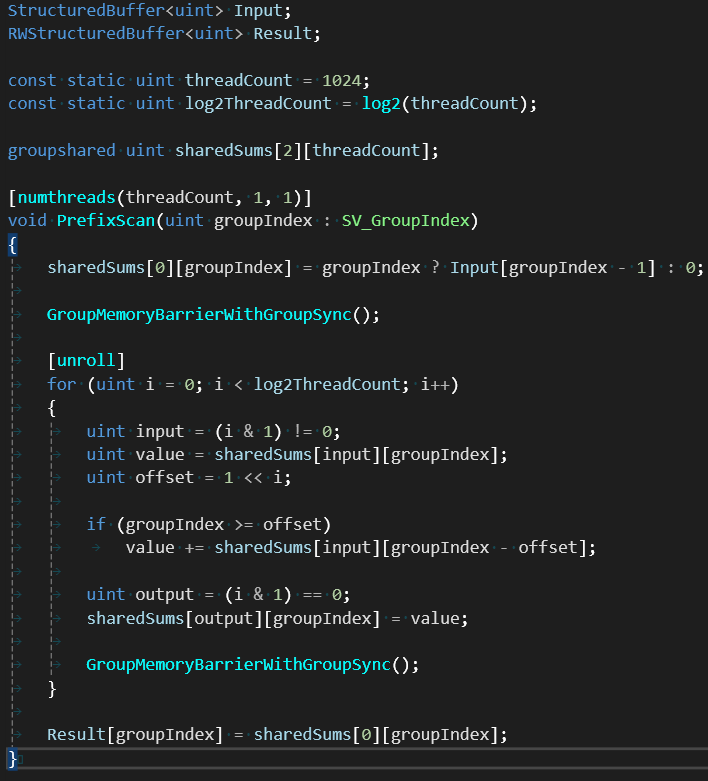
It was difficult to find a simple, concise parallel prefix sum example online, even the GPU gems code was obscure and had bugs.
I wrote a simple one, only handles a 1024 array, but can be expanded to larger arrays with multiple passes.
Not the most efficient method, but simple