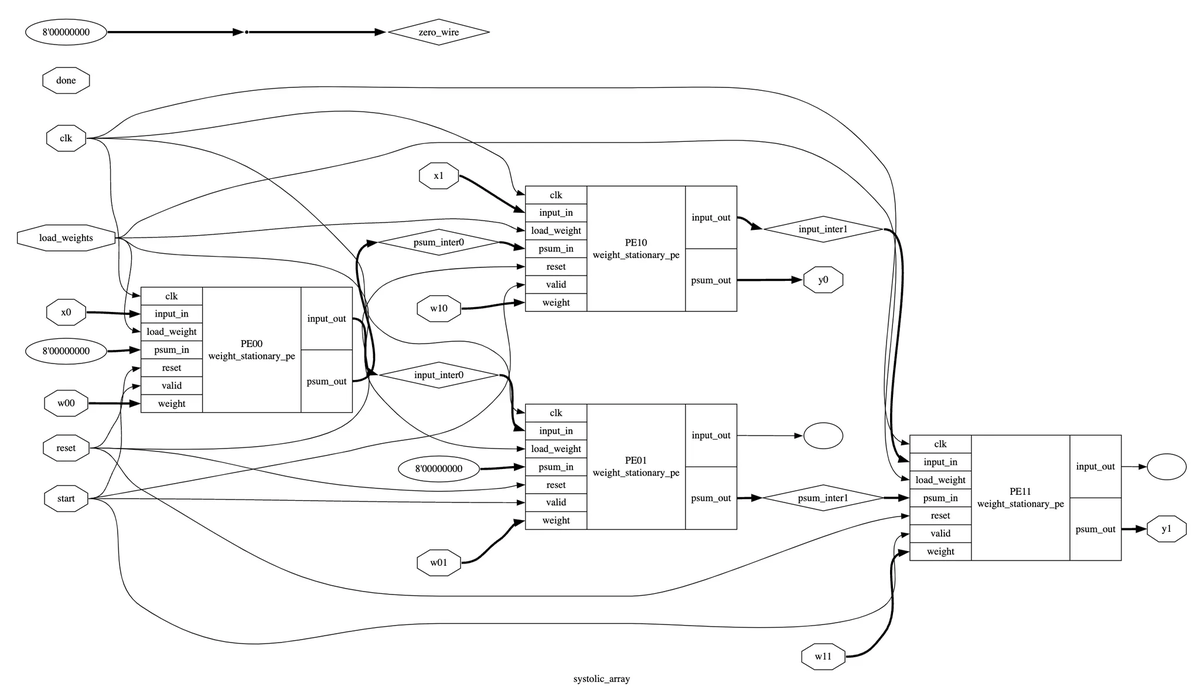
I spent my summer building TinyTPU : An open source ML inference and training chip.
it can do end to end inference + training ENTIRELY on chip.
here's how I did it👇:
i built a hardware accelerator to compute softmax more efficiently.
used a pipelined approach to create a high throughput module which entire performs the softmax computation in silicon.
here's how I did it:
I worked on this with @evanliin, @XanderChin, and @kennykgguo — incredibly smart people!
check out our article to see how our chip works and how we went about developing it:
tinytpu.com
you can also find the code here and play with it yourself:
having no hardware knowledge or experience at all until just 6 months ago, this was a very ambitious project to work on.
I had no idea how difficult this would be or if I could even complete it without the "prerequisites".
but throughout the last 4 months, I developed a style
before we got to designing any hardware, we started off with properly understanding the math behind MLPs.
we worked out the math by hand for inference and training of our network.
our first step was to decide the scale of this project.
we decided to target the simplest possible neural network — the XOR problem.
however, we still wanted to make this scalable so a core design philosophy for us was to ensure all of our mechanisms could scale to larger
before we started working on the chip, we decided to work out the math behind a simple MLP by hand for both forward pass and backprop since this was the base of our entire project