-
-

bg removal
-

bg changer
-

image masking
-

bg blender
-
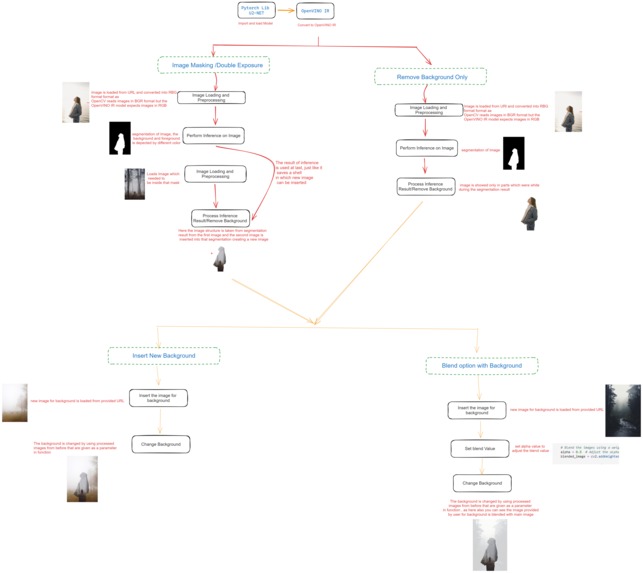
Architectural_diagram





Okay, so I'm not from the data science field and don't even know the syntax of Python other than print(). I'm a simple frontend web developer and a passionate graphic designer. When I came across this hackathon, I did some research and finally narrowed it down to two projects. The first was for human medication, and the second was for plants. There was a very specific reason, as my father was a farmer, and we have small fields to grow crops. That's why plant disease detection came to mind, with the future extension to more features like soil sampling and predicting which crops should be grown based on weather predictions. Our crops are mostly ruined by unexpected weather, resulting in losses. Also, when insects and disease affect plants, the use of pesticides harms human health.
The other main project was for medical purposes, using AI to give advice to patients with common illnesses and providing personal assistance such as reading diagnosis reports, analyzing symptoms, recommending advice, and predicting future illnesses. This was also for personal reasons.
I came across this hackathon around October 29-30, so time was very limited, and both projects would take time for development and research. I tried to create at least one feature for the medical project but failed to gather suitable resources for model training. I spent 2-3 days researching for that alone. I eventually found the Yolo8 model for object detection but then thought plant disease detection would be a better option with the LLM model. I spent another 2-3 days researching and collecting images and resources for training but failed to train the model due to the large amount of data required. Most models also demanded GPU processing, and as I'm not a Python expert, I struggled with how to train them. I did manage to train on a small dataset, but it was insufficient.
Wandering on how to proceed, I came across OpenVINO IR notebooks and found Vision-background-removal. I tried various things, got interested, and saw hope for creating a successful project. Earlier, I had thought about how programs like background removal work while working in Photoshop. So, I tried different things, found different resources, and finally settled with those features present in my project.
What it does
It has functionalities like image masking (double exposure), background removal, background replacement, background blending, and automatic caption generation.
How we built it
I thought about what I could create with the code already present in the notebook. I created the masking feature (similar to double exposure in Photoshop but more precise it is masking feature) by duplicating and modifying the code. Then, I thought about caption generation and tried various models but faced GPU problems. Finally, I settled with the API from Salesforce/blip-image-captioning-large from Huggins Face. While dealing with changing colors in background removal, I came across the blending feature.
Challenges we ran into
The most challenging thing for me was understanding Python code. Despite the basic programming knowledge and easy syntax of Python, it seemed easy until errors occurred, making it difficult for me to tackle. Another challenge was that most LLM models required GPU or RAM with 24 GB. Even Google Colab couldn't run many of them, and I had to run them on OpenShift so no chance.
Accomplishments that we're proud of
Everything was difficult and challenging, but that made it interesting for me to work on. Working under pressure made my brain function better, pushing its previous boundaries. I'm proud that for the first time, I worked with a model for this long, successfully tackled it, and understood it. Although I had worked with LangChain and OpenAI in the past month, creating code on my own, it was mostly learned from YouTube, and I imported them as needed making new things from that only.
What we learned
I learned to work with LLM models, how to run and manipulate them as needed, and how to add new features when required. I gained a little experience in using Huggins Face and how to deploy models there. I also got to know the interface of Red Hat OpenShift. Most importantly, I found where I can find all the resources for training a model, how to upload them, and how to use them.
What's next for Advanced Vision
Next is adding more features and converting it into a full-fledged application. I came across many things during this project, and there are also new ideas, so I will try to incorporate them into this project or create new ones."

Log in or sign up for Devpost to join the conversation.