-
-

caption
-
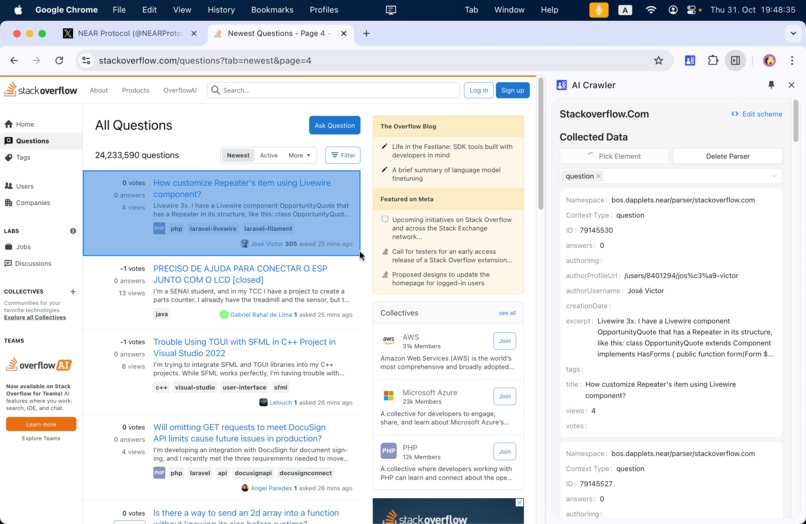
picking elements, building semantic schema
-
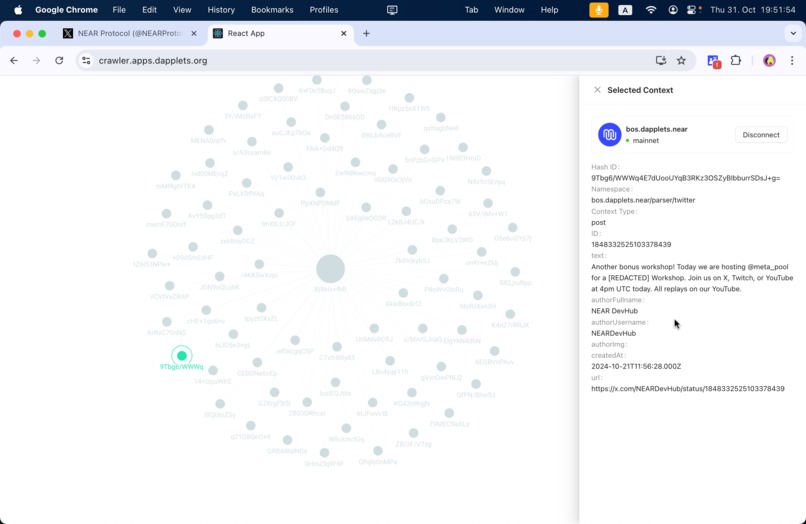
collected data, buying data example
-
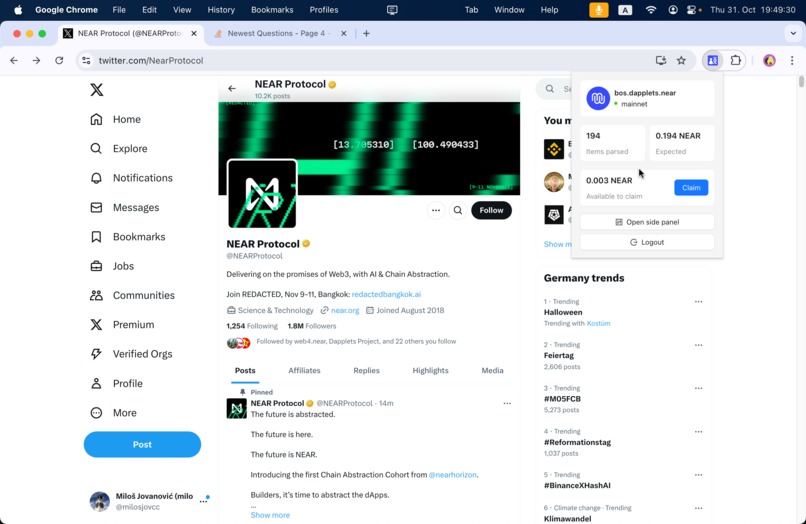
browse and earn mode.




Inspiration
AI needs data to learn. People need a reliable WayBack archive of everything. People and communities need backup storage for their content to overcome censorship by website hosts, data manipulation, or to implement new features.
The stored data needs to be broken down into semantic units. Storing whole web pages is insufficient because the most important web pages are portals with community-generated content that show different content to different users.
AICrawler is a community tool and a self-sustaining community that provides solutions to the above needs. The whole set of semantic schemas created as a by-product of the crawling process enables the Semantic Web, which the Mutable Web uses extensively.
What it does
AICrawler is currently implemented as a web browser extension, unattendedly scraping websites the user visits. To parse websites AICrawler needs Semantic Schema, created once per website by AI. The Schema Editor is also available as failback and for fixing errors. Ultimatuim browser, is thinking of implementing it natively.
How we built it
AICrawler reuses parts of the Mutable Web project and parts of the AICrawler prototype generated in chatgpt.
Challenges we ran into
- Breaking changes in near-sdk-rs.
- Token limit for gpt4o is lower than the token limit for the same model in the chatgpt. 30000 token limit is too low to parse whole sites.
- Docs for near wallet selector are not up-to-date? Usage patterns are not obvious, too much boilerplate code needed. Maybe too complex?
Accomplishments that we're proud of
it works.
What we learned
chatgpt api.
What's next for AICrawler
- Add decentralized storage.
- Better UX for manual mode.
- Validation for collected data.
- Improve AI part.
- Notification system for website changes.
- Better economics.
Built With
- ant-design
- near-api-js
- nest.js
- node.js
- openai-sdk
- react.js
- reagraph
- rust
- typescript











Log in or sign up for Devpost to join the conversation.