-
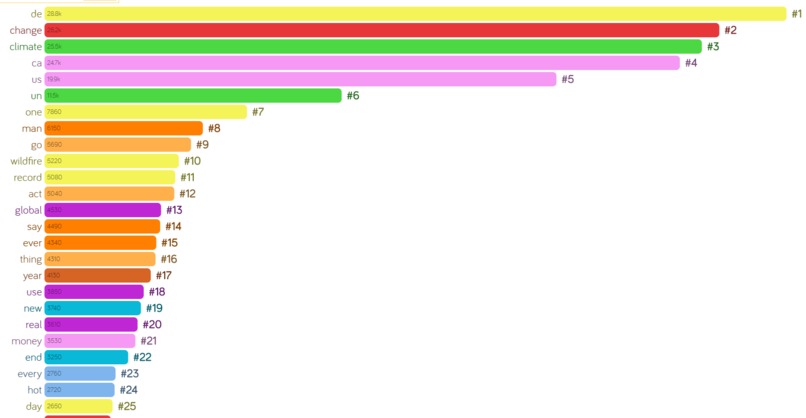
Most frequent words in August 2018

Inspiration
We were drawn to the popular culture track due to its open-endedness and the potential to use NLP to analyze data. We figured that one of the most important aspects of social media from a data perspective is that it gives us the ability to see how public opinion and sentiment changes over time, so we first decided to look into how the positivity and negativity of climate-change related tweets changed over the span of 2017-2019, when a lot of climate protests and movements started to take off.
What it does
Our project looks at how the frequency of different words changes over time, as well as how public sentiment changes over time, when looking at tweets related to climate change in some way. We verified that our data follows an even distribution of sentiments, and used gapminder and excel to visualize the data.
How we built it
IDs from tweets related to climate change were collected from Justin Littman and Laura Wrubel's dataset on the Harvard Dataverse. We used tweepy to collect text, like count, retweet count, post date, and location for roughly 164,000 tweets, and analyzed their sentiment using python's natural language toolkit package. We put the data in CSV files and made visual representations of the data.
Challenges we ran into
Accessing the twitter API was difficult to set up, and we ended up getting strange numbers of likes for most of the tweets as well as very few locations. There was also a significant challenge in learning to use tools that we hadn't used before or had only used in a specific way, such as gapminder, excel, and pandas.
Accomplishments that we're proud of
We're proud of involving everyone's individual skills and knowledge in order to create a project that has several different aspects to it.
What we learned
We learned how helpful it is to read through the API reference closely rather than just skimming; we found a number of NLTK methods that would have greatly aided us had we found them sooner. We also learned to communicate ideas and techniques between people with different majors and how to play to each person's strength.
What's next for Climate Sentiment
If we took this project further, we would train a Naïve Bayes classifier with data using TweetTokenizer. Also, our database of tweet IDs was much larger than we had time to request Tweets for; Twitter only allows developers to pull so many tweets at a time.







Log in or sign up for Devpost to join the conversation.