-
-

DeceptionRL
-

Our simulated game RL environment
-

GameEngine for efficient async RL environments
-
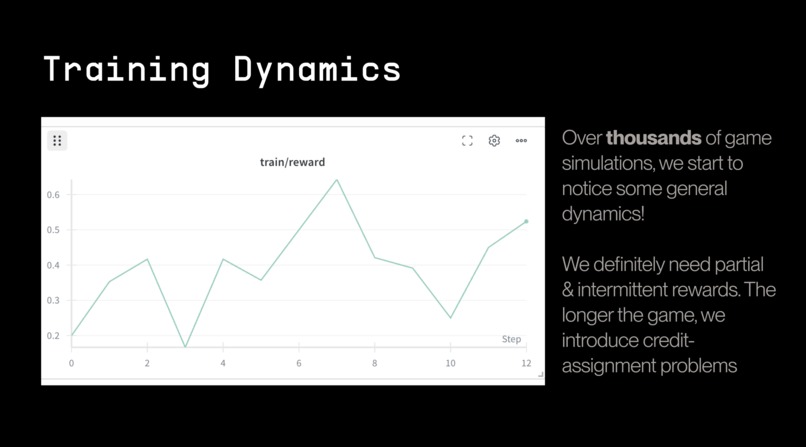
Steady-ish training dynamics on our large run! We learn basic behaviours over several thousand rollouts
-

Game examples
-

Game examples
-

A few things that we realized were good with our model & next steps we noticed







We propose that language models can learn basic game theory and, more importantly learn to deceive other language models with RL. We propose this through a game of SecretHitler, where you win the game with the odds stacked against you if you can effectively deceive and strategize against your opponent.
Game Engine
Our GameEngine is built on a fully asynchronous architecture to manage multiple concurrent games, each running as an independent task that communicates via dedicated I/O queues. Within each game, the Engine class orchestrates the game state, tracking public events visible to all agents and private events specific to individual players. With the gather primitive to parallelize agent interactions (ie when all agents need to vote on a chancellor or decide whether to speak during discourse phases) these requests are dispatched simultaneously rather than sequentially. Communication with external agents (whether AI models or human players) uses the protocol to send input objects containing conversation history and tool call specifications, then awaits output responses with tool call arguments. This queue-based, event-driven design allows the engine to handle (via napkin math) 100+ multiple games efficiently while maintaining clean separation between game logic and agent inference.
RL Training
Our reinforcement learning system is designed for maximal parallelism on a 8xH100 GPU node using Modal's distributed compute platform and the ART (Adaptive RL Training) framework. Each training step executes multiple simultaneous game rollouts asynchronously. Within each rollout, our agent plays one of the five game agents, the remaining four being GPT-5, with each agent receiving role-specific context. Model inference itself is handled by vLLM with tensor parallelism, with some hacky ways to get Qwen3-7B-Instruct to provide reasoning + tool calls via our RL framework. By using the GameEngine as our source of truth, we ensure that all 8 GPUs are utilized with active game states rather than waiting idle for sequential game logic or I/O operations.
Results
We had strong training dynamics for an RL run! Lots of improvement, but we learn a lot of patterns! View the images for images of our training dynamics & some interesting deception/game theory reasoning traces within the game.
Built With
- modal
- openai
- openpipe-rl
- python







Log in or sign up for Devpost to join the conversation.