-
Visual Representation of the Workings of the Programs
-

DarkMode Logo
-

LightMode Logo



Inspiration
The inspiration to this project was in trying to figure out what is a product that solves an everyday problem and is versatile to be used in other helpful ways. In what ways can our service improve the quality of lives of individuals? The idea of a program to convert PDFs to audio was born. Not only will this program allow students to listen to notes from classes, it is also easy to navigate for individuals who are visually impaired. As college students we made it our mission to figure out how to get our notes to be read in voice of one our professors, as funny as it is. This can make the difference between passing or failing when connecting material mentally when reading notes from class or powerpoint slides.
What it does
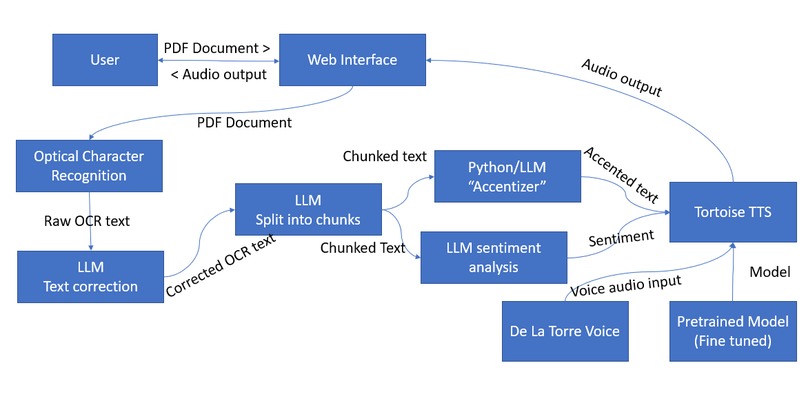
DocSound converts text from PDFs into Audio, through OCR Tesseract phrasing of PDF to text, LLM text correction, and Tortoise TTS of text to audio. After the PDF is converted to audio, the audio is sent back to the website and can be listened to or downloaded.
How we built it
We used Svelte for our front end. Using the PyTesseract OCR library to convert the PDF from the website to text. We used the Kobalt LLM to correct the raw text fed by PyTesseract. This text is then sent to Tortoise TTS where the Pretrained Model takes the text and create an audio. The audio is then sent back to the website for the user.
Challenges we ran into
Despite many challenges, they were definitely memorable ones. Learning new libraries and programs to use, and new programing languages - python. Processing a lecture recording of our professor's voice, and the Pretrained Model rejecting the audio. A significant challenge was connecting our backend and frontend together, along with keeping in mind library dependencies and platforms.
Accomplishments that we're proud of
What we are most proud is our determination in working hard and our flexibility to use multiple unfamiliar programs/frameworks. Only within twenty four hours, we were able to learn Python, LLM Kobalt, Svelte framework, and Tortoise TTC fundamentals and get to a point where we felt comfortable squeezing in some sleep.
What we learned
We learned a lot. Three out of the four of our members hadn't had any experience using the different APIs, one team member had never used python and was still able to contribute to our back end. The most important thing we learned, hard work and good spirits go a long way.
What's next for Docsound
We aim to finalize and find tune the Pretrained Model to output audio with our professor's voice. We want to allowed functionality for users to input their own choice of voice so that they can develop their own personalized Pretrained Model
Built With
- css
- github
- gradio
- html
- javascript
- kobold
- llm
- node.js
- ocr
- python
- svelte
- sveltekit
- tailwind
- tesseract
- tts
- typescript

Log in or sign up for Devpost to join the conversation.