-
-
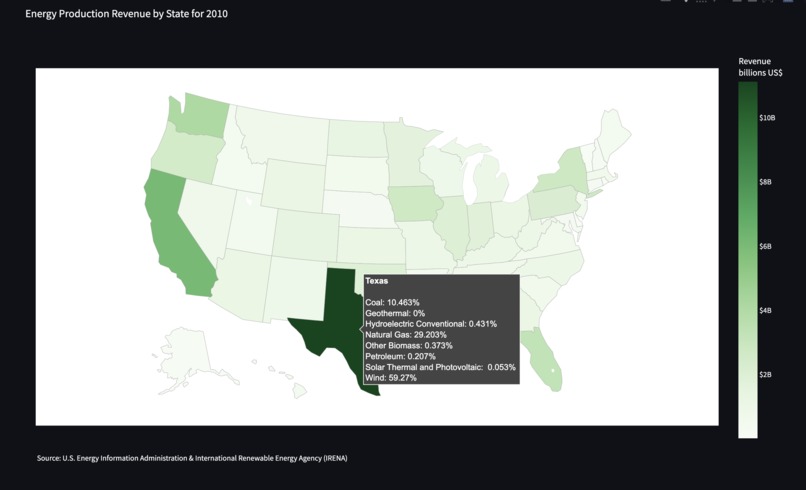
Energy Production Revenue by State
-
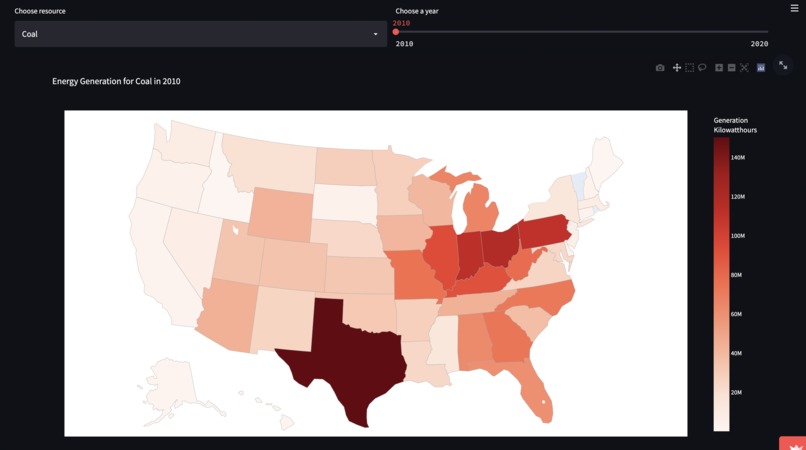
Energy Generation by Source
-
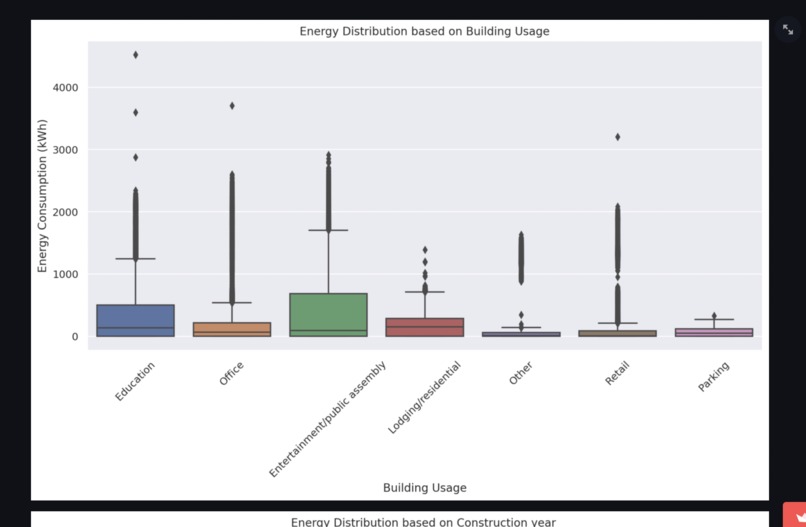
Energy Distribution based on building info
-
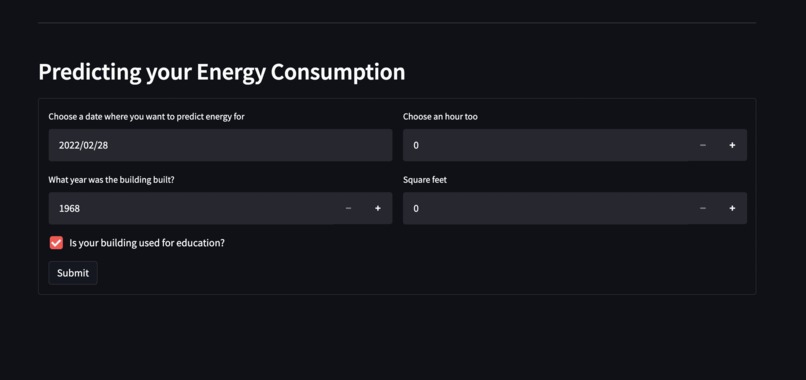
Machine Learning Model for Prediction




Inspiration
As it stands, fossil fuels are significantly cheaper at producing energy than renewable technologies. However, this is not a sustainable solution, and we are still years away from reaching parity in efficiency between renewable sources and conventional fossil fuel sources. Moreover, businesses would not only profit from minimizing their energy consumption but also help them achieve lower CO2 emissions. Our goal is to identify, through machine learning, which features contribute the most to energy consumption so that they can be tackled to minimize the energy consumption for businesses.
How we built it
We initially looked for datasets that would help us with our project in order to find the factors that create energy consumption as well as various costs for energy sources. We then interpreted this data and compiled it onto a dataframe in python as we collaborated through the platform Deepnote. Through this platform, we were able to work on visualizing the data through maps and graphs. We used libraries from Plotly to help us in this endeavour. While part of our group worked on this, the rest worked on the machine learning aspect of it by working on the modelling of the projection and training the system. We experimented with using Optuna which is an open-source hyperparameter optimization framework to automate the tuning process. This was something new that we explored and the experience was very rewarding as it cut down the resource-intensive process significantly.
Finally, we orchestrated the code on Streamlit so we could display the visualizations and machine learning model through a web app.
Challenges we ran into
- Finding relevant data for performing our analysis was the first obstacle we faced. While we were able to readily find data about renewable energy in European countries, the same was not the case for the United States. Finding relevant data was very difficult and took ~4 hours of researching to get the data as well as to clean it.
- Model Training and Hyperparameter tuning presented themselves as a challenge in a short timeline. The dataset we compiled consisted of more than 600 thousand rows hence to be able to produce a good model, the tuning model had to go through many layers and many repetitions to finally produce the best parameters.
- Building an application on streamlit was a brand new process for most of us. Hence, we learned from each other and also learn from articles online on how to develop on that platform.
Accomplishments that we're proud of
- Successfully trained a model with a root mean square error of 39 for predicting the energy consumption of a building
- Learned the full process of data science pipeline from data cleaning to analytical modelling to presentation
- Learned how to work on streamlit as a platform to present our insights on datasets
What's next for Energytics
- We can track the trend of renewable sources of energy as well as the trend of fossil fuels using our machine learning model
- Find more specific data on energy for specific companies and in general more data is definitely needed for further development of this project





Log in or sign up for Devpost to join the conversation.