-
-
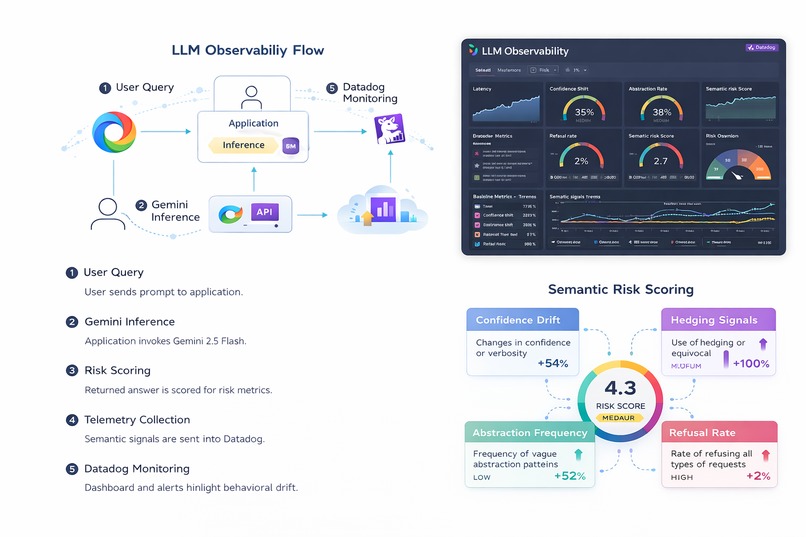
LLM observability system overview

Inspiration
Modern LLMs rarely hallucinate blatantly anymore, but that makes failures harder to notice. In production, models often fail quietly through subtle behavioral drift. I wanted to explore how LLM quality could be treated as an observability problem, similar to traditional software systems.
What it does
Llm-observability monitors Gemini-powered applications and extracts semantic and operational risk signals such as latency, confidence shifts, and abstraction patterns. These signals are sent to Datadog to surface early warning signs of silent degradation.
How we built it
I built the system end-to-end as a solo project using Gemini 2.5 Flash, Google Cloud Run, and Datadog. Each request is evaluated after inference and turned into metrics, dashboards, and alerts focused on trends rather than absolute failures.
Challenges we ran into
Strong models don’t fail dramatically, so obvious hallucination spikes were rare. This required redesigning the system to focus on relative changes and behavioral drift instead of chasing extreme errors.
Accomplishments that we're proud of
I built and deployed a complete observability system as a solo developer. The project reframes LLM failure as silent drift and demonstrates a realistic, production-style monitoring approach.
What we learned
Blatant hallucinations are no longer the main risk with modern LLMs. Observability needs to focus on trends, context, and subtle behavior changes, not just correctness.
What's next for Llm-observability
Planned improvements include semantic similarity checks for RAG pipelines, user feedback to refine risk scoring, and prompt injection detection. I also plan to add per-request cost tracking and A/B testing support to compare risk across model versions.

Log in or sign up for Devpost to join the conversation.