-
-
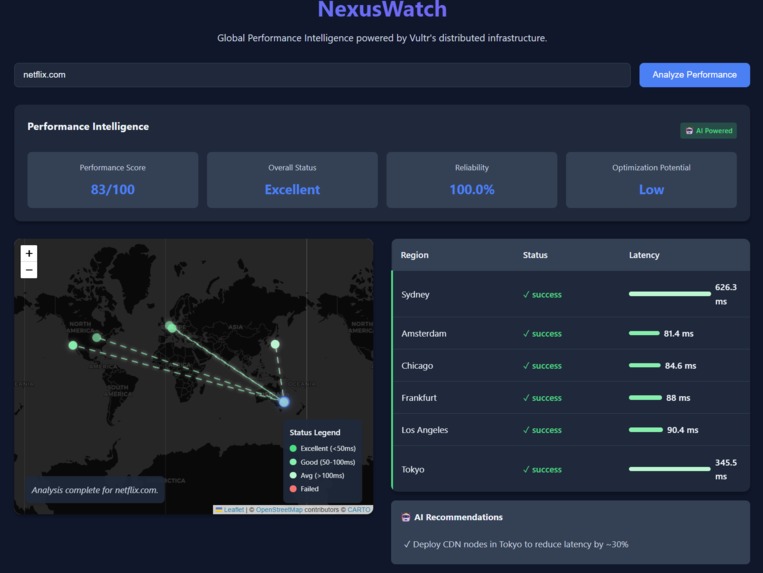
Main Page
-
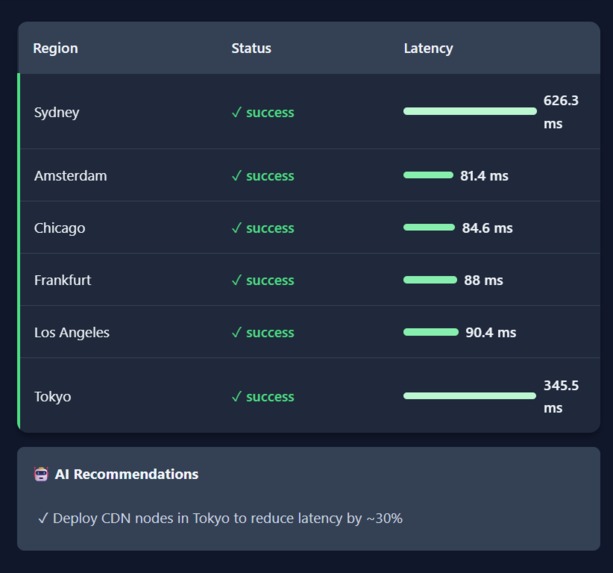
Latency && AI Suggestion
-

Performance Metrics
-
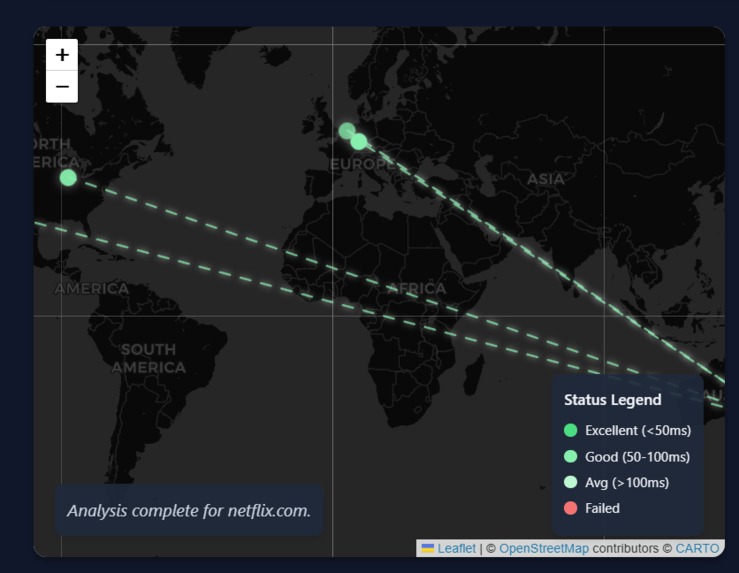
Interactive Live Map




Inspiration
- In today's digital-first world, website performance directly impacts user experience and business success. We were inspired by the challenge that companies face when trying to understand how their services perform across different geographical regions. Existing solutions are either expensive enterprise tools or simplistic single-point tests that don't capture the global picture. We wanted to create something that leverages Vultr's global infrastructure to provide comprehensive performance insights with the power of AI.
What it does
NexusWatch is a global performance intelligence platform that tests website performance from multiple regions across the world and provides AI-powered insights and recommendations. It allows users to:
Test any website's performance from 6 global regions simultaneously Visualize network paths with animated connection lines on an interactive map Receive AI-generated performance scores and reliability metrics Get actionable recommendations for optimizing global performance Understand how their service performs from different user perspectives The platform transforms raw performance data into strategic business intelligence, helping companies make informed decisions about their global infrastructure.
How we built it
We built NexusWatch using a distributed architecture that leverages Vultr's global infrastructure:
- Backend Infrastructure: Deployed 6 Vultr cloud instances across Sydney, Amsterdam, Chicago, Frankfurt, Los Angeles, and Tokyo Created a central orchestrator in Sydney that coordinates all performance tests Used systemd for robust service management to ensure reliability
- Testing Technology: Switched from ICMP ping to HTTP-based testing for more accurate web performance measurements Built custom Python agents that measure Time to First Byte (TTFB) for any website Implemented proper error handling and timeout management
- Frontend Experience: Developed a React TypeScript application with a modern dark theme Created an interactive map using Leaflet with animated connection lines Built responsive components that work seamlessly across devices Implemented smooth animations and loading states for better UX
- AI Integration: Integrated Vultr's Serverless Inference API for intelligent analysis Crafted detailed prompts that guide the AI to provide meaningful insights Implemented fallback mechanisms to ensure the application works even if the AI is unavailable
Challenges we ran into
Challenges we ran into
- Service Reliability: Initially, our agent processes would terminate when we closed SSH connections. We solved this by implementing systemd services for robust process management.
- Testing Major Services: We discovered that many large websites like Netflix and Amazon block ICMP ping requests. We pivoted to HTTP-based testing which is more relevant for web services and works with virtually any website.
- API Integration: Integrating the Vultr Inference API required careful prompt engineering to ensure the AI provided structured, useful responses rather than generic text.
- UI/UX Design: Creating a visualization that was both informative and visually appealing required multiple iterations to get the right balance between data density and readability.
- Cross-Region Communication: Ensuring reliable communication between our central orchestrator and distributed agents required proper error handling and timeout management.
Accomplishments that we're proud of
Accomplishments that we're proud of
- Complete Distributed System: We successfully built and deployed a distributed system spanning 6 global regions in just a few hours.
- Real AI Integration: We went beyond hardcoded recommendations to implement genuine AI-powered insights using Vultr's Serverless Inference.
- Professional UI: We created a polished, responsive interface with smooth animations and thoughtful interactions that rivals commercial monitoring tools.
- Robust Architecture: Our system is built with production-quality practices including systemd services, proper error handling, and fallback mechanisms.
- Solving a Real Problem: We created a tool that addresses a genuine business need that companies typically pay thousands of dollars for with enterprise solutions.
What we learned
- Global Infrastructure: We gained deep insights into how global infrastructure affects web performance and the importance of geographic proximity to users.
- Distributed Systems: We learned firsthand about the challenges and solutions for building reliable distributed systems.
- AI Integration: We developed skills in prompt engineering and integrating AI services into web applications.
- Modern Web Development: We honed our React TypeScript skills and learned to create complex visualizations with libraries like Leaflet.
- System Reliability: We learned the importance of robust service management and the difference between a quick hack and a production-ready system.
What's next for NexusWatch
- Historical Tracking: We plan to add historical performance tracking to show trends over time and identify performance regressions.
- Alert System: We want to implement a notification system that alerts users when performance drops below specified thresholds.
- Expanded Testing: We're looking to add more testing locations and additional metrics beyond just latency, such as uptime monitoring and route tracing.
- Custom AI Models: We plan to fine-tune AI models specifically for performance analysis to provide even more accurate and domain-specific insights.
- Integration with CI/CD: We envision integrating NexusWatch into development pipelines to automatically test performance during deployments.
- Public API: We're considering offering a public API so other services can integrate NexusWatch's global performance testing capabilities.



Log in or sign up for Devpost to join the conversation.