-
-
Pipes Page
-
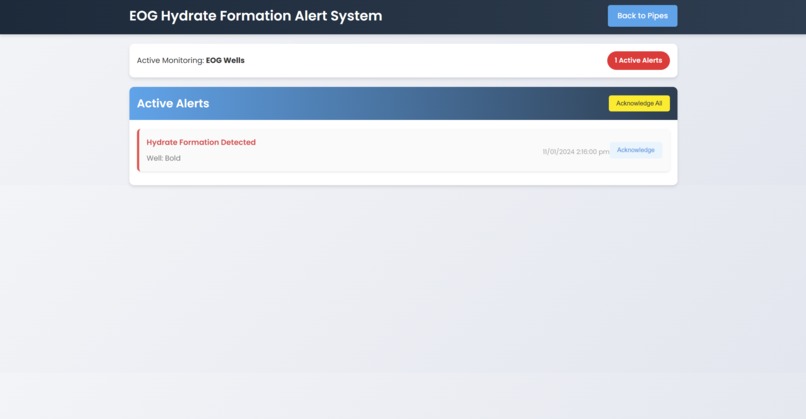
Alerts Page
-
Home Page



Inspiration:
We were inspired by our goal to build a full stack application with machine learning in conjecture with the datasets given by the EOG Resources challenge. We also realized the dangers of hydration caused by pipeline blockages in oil wells to humans and the natural environment, and have decided to make ourselves busy in attempt to solve this problem. As a group, we have not had much experience working on group programming projects together, and have found this challenge a great opportunity for us and for society as a whole.
What it does:
Our project, PipeBrains, was trained using a machine learning algorithm from Scikit on the given datasets by EOG. It produced promising results, with an R^2 of around 94% and lesser mean error. With this, our trained model was able to predict possible hydrates in the pipes, as well as create the chart API to graph trends for the user to view. Moreover, we also added an alerts tab that shows alerts every second based on the data fed on pipes. We also added a custom field for owners to manually input data to for them to know the predictions. Firebase was used to manage login pages for the owners.
How we built it:
Before creating our machine learning model, we graphed all the given datasets to find trends and faults in the data. We found major deviations when pressure had quick releases due to the pressure valve opening quickly. Our research indicated that this is an effect known as the Joule-Thomson effect, where a sudden release in pressure can lead to natural gas freezing at rapid rates, causing the gas to stop moving. We used statistics to find the major deviations in data, and have used that to determine where in the datasets we believe a hydrate may have been produced. However, rather than using statistics for our final predictions, we have decided to create a machine learning model to handle that for us. We cleaned up the dataset by filling in the empty data with what would be appropriate, and added our own column indicating our predictions for whether the dataset at a certain row is experiencing a hydrate or not. Using Python and Scikit, we ran this through a machine learning algorithm to create a model that can make predictions, rather than analyzing it at the base mathematically. Since all data is numeric and there are only four inputs, we felt the random forest regression model would be best suited for the role, as it can produce notably accurate results, and so our machine learning model has a success rate of about 94% in dealing with the pipes given the datasets from EOG. The pro to this is that it allows our app to be more versatile to newer pipelines or pipelines that are not documented as well as others. Already having trained a machine learning model allows our application to make new predictions with little new data, unlike examination with mathematics. To build our front-end, we used HTML, CSS, and JavaScript with some Tailwind CSS, as these languages are usually standard in web applications. We integrated our web application with Python using Flask to build our custom API that retrieves predictions from our machine learning model from Scikit. To handle logins, we decided to use Firebase's API for its ease of use, reliability, and security.
Challenges we ran into:
Not all team members were familiar with machine learning algorithms and were required to learn how it works quickly. Most team members were not a fan of web development, though it was necessary for our team's application. This led to an onslaught of challenge after challenge, error after error, with little understanding of team members. We found it difficult integrating our Python code, a language we're more familiar with, to JavaScript, a language we were not as comfortable with.
Accomplishments that we're proud of:
Team members have gained a solid understanding of machine learning and how it's implemented in our application. The team members that worked on the model itself felt proud, as most of the competition in previous Hackathons simply use wrappers such as GPT-integration, while instead our team went ahead and trained an entire model using the given data. Though we had a rocky start to web development and JavaScript in general, we as a team have collectively taken the effort to learn our mistakes and fix them, enough to fix our code's errors and complete our application. Also as a team with members who have all been close throughout university years, we are proud to have finally been given an opportunity to create a meaningful and impactful project and show the world what we can do.
What's next for PipeBrains?
Next, we plan on improving our UI and making our pipe designs look real. We plan on organizing our code better for the future and we plan on making constant tweaks to our approaches to better improve our application's accuracy and speed. We would love to work with more datasets for training a machine learning model and try to include more parameters than only what was given in the datasets by EOG. We are excited to make changes that can better the work environment and benefit society as a whole.






Log in or sign up for Devpost to join the conversation.