-
-
-
Verbwire
-
-
-
-






RAIdology
Inspiration
80 million CT scans are performed every year in the US according to Harvard Medical School.
With CT scan appointments taking up to 1hr and 30 minutes, that's 120 million Physician Hours spent on scans.
Given the average Radiology Physician makes $217 per hour, which means that's 26.04 Billion USD spent every year on CT scan.
With healthcare getting more expensive and more backlogged with physicians increasingly experiencing burn out, our team has come together with an exciting vision to streamline the process by developing an AI-driven radiology assistant. As we began our discussions, we explored several innovative ideas, including wildfire prevention, text-to-movie conversions, and AI ultrasound detection. After a few deliberations, we felt most inclined toward the AI ultrasound detection concept.
Objective:
The project is intended to serve as an AI-powered radiology assistant that analyzes ultrasound images to provide insights. The primary goal is to "replace" the need for a doctor to interpret ultrasounds, offering a first-line analysis and guiding users to a doctor if there are any serious issues. However, the emphasis is on recognizing and providing insights about the ultrasound images, particularly focusing on the health of the baby and parent. We want to promote social equity and inclusion by providing accessible care for any users that want a deep understanding of their ultrasound or radiology images broken down. By creating this app, anyone can upload their radiology photos, and "replace" the need to spend a high cost asking the doctor to explain a radiology scan, with even that possibly being more cryptic than our app.
General Flow
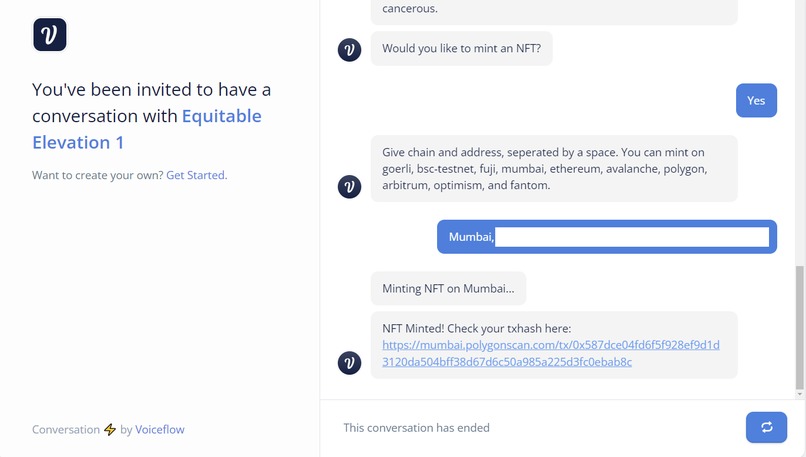
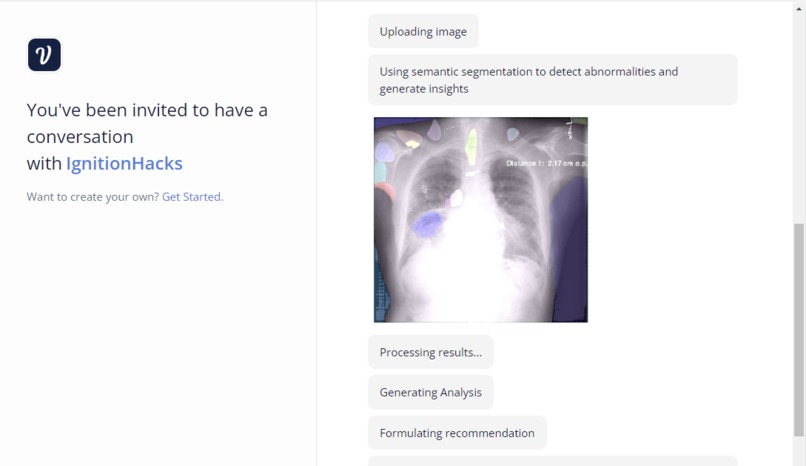
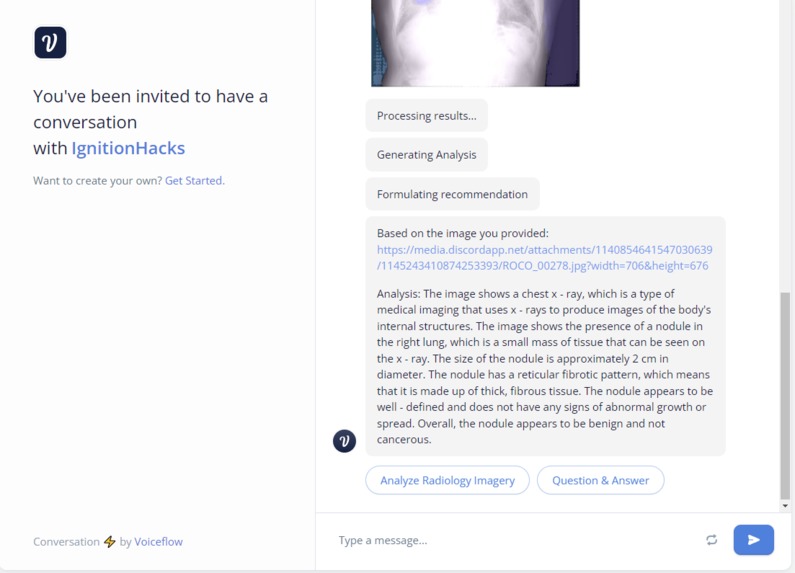
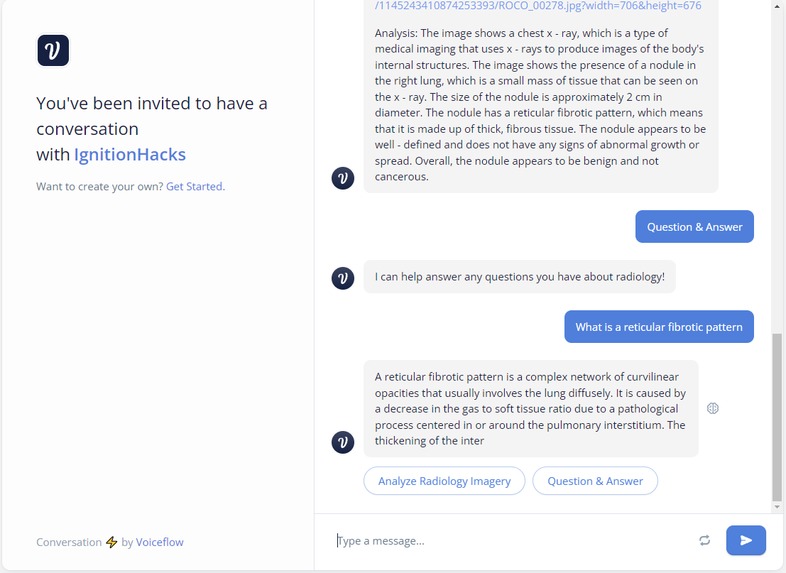
Users are introduced via a landing page and directed to a Voiceflow interface. Users then upload ultrasound images. An AI model, which we are actively developing, will then analyze these ultrasound images. Insights drawn from the images will be processed and presented through a chatbot. This is where the Language Model (LLM) comes into play, converting the AI's findings into comprehensive insights. The objective is to provide a simplified overview of the ultrasound's findings, focusing primarily on the health of the carrier, potentially eliminating the immediate need for a doctor unless a serious issue is detected. We've also discussed possible expansions like gestational time estimation, baby size predictions, and recommendations (like whether a C-section might be advisable). We allow users to mint an NFT on over 13 chains using the Verbwire API, building an API to mint an NFT for ease of access, and being able to choose a chain, and send this NFT cross chain, which represents sending to various hospitals or clinics. Verbwire makes it easy to create and transfer NFTs across several chains.
Features:
A user-friendly landing page for users to access the system. Voiceflow interface for user interaction. Capability to upload ultrasound images. An AI model that analyzes the uploaded ultrasound images. A chatbot (LLM) that uses the insights generated by the AI to answer user queries. Possibility of a mobile app for added convenience. Potential features discussed include: Descriptions of ultrasound images. Baby health insights. Information about the carrier's health. Possible recommendations (e.g., whether the host should consider a c-section).
Tech Stack
For the tech stack of our project, we decided to use T3 stack for the frontend, and FastAPI for the backend. On the ML side, we used Jupyter for inference, and a Lambda Labs A100 reserved cuda (GPU) instance for training. We fine tuned an ensemble of LLaVa and MiniGPT using QLoRa quantized embeddings. We also researched CLIP, intending to use it to get LLM insights. For our production model, we used a checkpointed version of MiniGPT fine tuned on ROCO-instruct to generate medical insights (tandem to LLaVa-Med) and a Segment Anything semantic model to detect abscesses and abnormalities. We trained this model on a A100 NVIDIA GPU, provided by Lambda Labs, but we would prefer to have the perfect specs of 4x A100, 512 SSD, which would be the best specs to run a self fine tuned large language model. On the backend side, we had to set up a local NVIDIA cuda deployment, and run a FastAPI endpoint (with ReDoc support) that could connect to our Voiceflow interface (another part of our frontend). This way, we could pass image urls that could be unpacked and our inference could be done locally, then passed back using the ByteScale API. For NFT minting, we used the Verbwire API (quick mint an NFT from metadata URL), to first choose a chain and address, and mint an NFT on that chain.
Next Steps
As we progress, we are considering making a mobile version, leveraging Voiceflow's mobile optimization. We hope to reach out to clinics and hospitals, improve general features and model accuracy, as well as providing an easier interface for users to be onboarded. We also hope to have real time analysis from doctors, which can be done with funding, as we partner with these institutions. Finally, we want to leverage better infrastructure in order to train these models, specifically LLAVA-MED.
Challenges
However, there have been certain points of confusion and challenges. For instance, ultrasounds are usually conducted in the doctor's office, where the doctor then reviews and informs the patient about any findings. We need to identify the precise gap our solution will fill in the current medical process. Also, fine-tuning the AI's capability to understand and interpret ultrasound images is something we're continuously working on.
Conclusion
Regardless of the challenges, we're excited and are actively dividing tasks, setting up the technical stack (next tailwind), and ensuring we have a clear direction to move forward. Let's bring our vision of an AI radiology assistant to life!
Built With
- bytescale
- gpt
- javascript
- minigpt-4
- python
- qlora
- t3
- tailwind
- typescript
- voiceflow










Log in or sign up for Devpost to join the conversation.