-
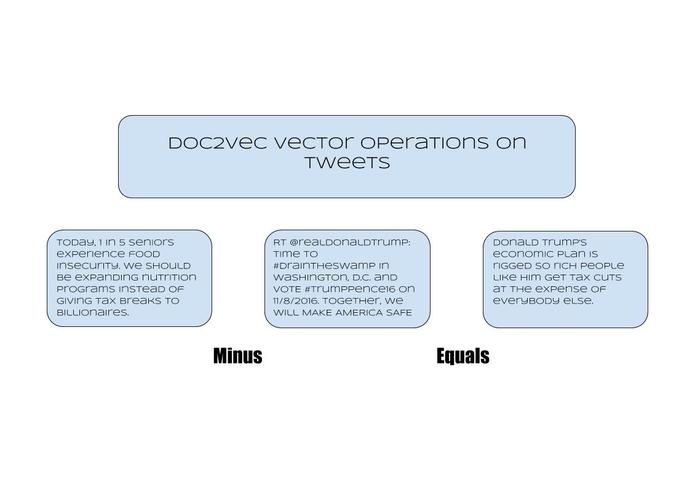
Flowchart showing how vector operations can be used on tweets in order to create results of semantic signifigance
-
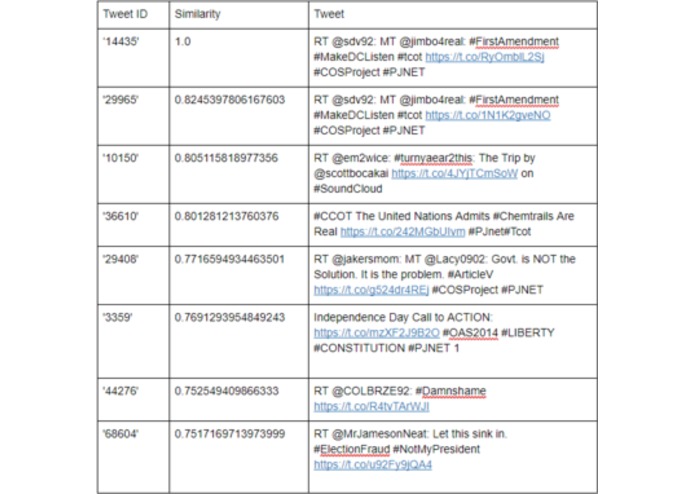
data table of similar tweets organized by document to vector (gensim)
-
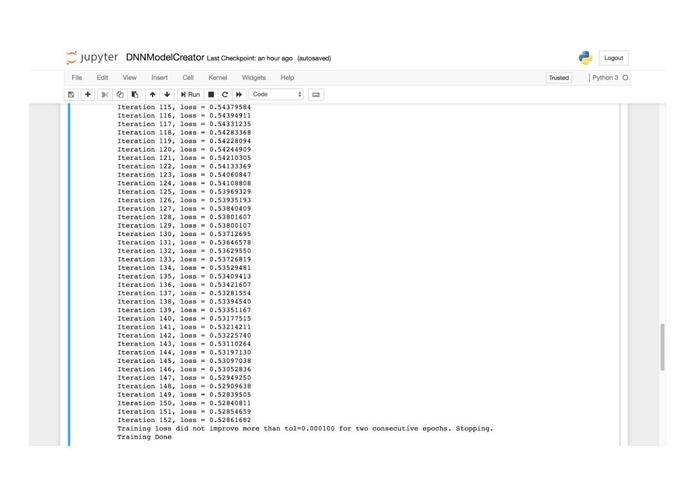
screengrab of Jupyter Notebook showing the Neural Network learning. The loss function can be seen decreasing over time (scikit-learn)



Inspiration
As a group, our team decided to take on a free online coursera course on machine learning. When looking into different possible uses for the concepts that we learned in the course we stumbled upon an online dataset of Russian Bot Tweets. This gave us the idea that, utilizing our new knowledge of machine learning, we could attempt to make a bot that would distinguish Russian Bot Tweets from other regular tweets. We wanted to implement a learning algorithm that would learn from repetitively attempting to classify the tweets as Bot vs non-Bot. We went in, not knowing whether or not these Russian tweets were actually distinguishable from their regular counterparts, but took it on as a challenge. We knew the implications of this learning algorithm. Using it we would be able to do two possible things. First, if the software was effective we would be able to use it to predict other Russian Bot tweets, but if it would not distinguish, we would have the valuable information of knowing just how sophisticated the Russian tweets are so that they blend in with the rest of the tweets. Knowing the far reaching implications we were excited to build this idea from the ground up here at Hack MHS V
What it does
Our completed program is mainly 2 parts: Doc2Vec and a Neural Network. Doc2Vec takes in a list of documents or in this case the text of our tweets and then represents these documents in a very high dimensional space where more similar documents are closer together. Theoretically, this algorithm allows normal vector operations to be performed on entire documents, which opens it up to some interesting implications, which we explored in the script VectorAnalysis. One use of Doc2Vec is returning similar documents in a dataset give a starting document. An example of this can be seen in the table in the images section. The original tweet, which has hashtags like #MakeDCListen and #FirstAmendment get matched with tweets with hashtags like #Constitution and #ArticleV. Another use of Doc2Vec that we implemented and found really interesting was vector subtraction. By subtracting the vector of one document from another, you get a new vector that is mathematically the content of the original article minus the content of the second article. For example, we found that subtracting the tweet “Today, 1 in 5 seniors experience food insecurity. We should be expanding nutrition programs instead of giving tax breaks to billionaires.” from “RT @realDonaldTrump: Time to #DrainTheSwamp in Washington, D.C. and VOTE #TrumpPence16 on 11/8/2016. Together, we will MAKE AMERICA SAFE” gave a vector most similar to the tweet “Donald Trump's economic plan is rigged so rich people like him get tax cuts at the expense of everybody else.” The Neural Network takes in the Doc2Vec vectors and tries to predict whether or not the tweet came from a russian twitter bot using the adam optimizer function in scikit learn. Our data was split into a test and training set, so that we could have a general understanding of how our neural network would work in real world simulations. Using our neural network model it is theoretically possible to apply this to real time data from twitter to find russian bots.
How we built it
We first started by compiling the russian bot data set from around the time of the last presidential election from Kaggle.com: https://www.kaggle.com/vikasg/russian-troll-tweets. We then combined this data set with a data set from https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/PDI7IN which contains normal tweets. From both datasets we pulled the username of the user and the text of the tweet. To be able to get the actual text we use the Twitter Hydrator, which takes tweet id’s and gives back data from that tweet. To combine the actual tweets we changed both into a comma separated value format (csv) and then used a Jupyter Notebook running python to combine the data into a single file using only the features that were relevant.’
Then to actually make the text usable in machine learning we ran the data through a lemitizer and cleaner to break all of the words into their base form. (IE: Forms -> Form and Ran -> Run) Then we took the cleaned data and shuffled it randomly to remove any placement bias within the system. After that the data was run through a doc2vec system, which turned all of the text into a vector, which could be used for machine learning. To confirm the doc2vec system was working we used the cosine similarity to test that the system was actually able to tell similar words or phrases were similar to each other.
Using these vectors we implemented a neural network in scikit Learn in python with 2 hidden layers, 700 nodes and 2 output nodes, which would either predict 1 if the tweet was from a russian bot and 0 if it was not. This neural network used the atom learning algorithm to learn its weight values. Additionally, once the training was complete we used accuracy, precision, recall and f_scores to improve our algorithm.
Challenges we ran into
Because of the the project, we had to process and parse a huge amount of data and this manifested itself as several different problems. Originally we planned on using Amazon Web Services to speed up this processing time considerably, however Amazon rejected all of our applications because the domain name of our emails did not match our School Name. We therefore had to rely on MacBooks to do all of the processing. This was a significant issues: with over 400,000 different tweets, 600 different features, and over 588,000,000 weights, it often took 30 minutes to an entire hour to run a script to construct or train a model. Furthermore, the data sometimes overloaded the ram, forcing us to restart a script. We also ran into many issues constructing our dataset. While the Kaggle dataset, which provided the Bot dataset, was ready to go as soon as it was downloaded, the Harvard dataset had to be ‘hydrating,’ meaning we had to download tweets directly from the twitter API at a limited rate and this took a lot of time. After that, we ran into issues combining the two datasets together. Somehow NULL bytes ended up inside the Harvard dataset and we had to manually delete these records. After preparing the dataset we ran into issues deciding between using the Document to Vector algorithm or the Word to Vector algorithm, as we were not entirely sure what the difference between them were. We eventually decided to go with Doc2Vec because it seemed to fit better with our data, as tweets were entire documents. Finally, after we managed to Vectorize the data we ran into issues with Tensorflow, the most popular machine learning library. We had never worked with it before, and could not figure it out. After many hours of troubleshooting we decided to switch to the slightly higher-level library scikit-learn, which worked well for us; however, we were unsure if we wanted to use Support Vector Machines, Logistic Regression, or a Deep Neural Network. We originally tried a SVM, but because of all the records we had it would converge, so we ended up using a Deep Neural Network.
Accomplishments that we're proud of
One thing that we are very proud of is our implementation of Doc2Vec. Our Doc2Vec implementation maps 400,000 different tweets into 1 vector space where the distance between tweets represents how similar they are. We are especially proud of Doc2Vec’s ability to subtract tweets from each other in a way that creates a tweet that is a logical subtraction of the content in the first two tweets. We are also very proud of our ability to troubleshoot: we came out with a relatively complete project in spite of running into many challenges along the way, which made this a very valuable learning experience. Furthermore, we are proud of our ability to implement a Deep Neural Network. They are normally considered a state of the art algorithm and we think it is a great achievement that we could implement them ourselves.
What we learned
We learned a ton of things involving machine learning through this hackathon. First, we started off having to combine datasets, which we had assumed would be pretty simple, but it ended up taking a significant amount of time and involving us to play with the csv format to get it load and compile correctly in python. We learned a lot about the inner working of the csv library in python. Additionally, none of us knew anything about doc2vec, but it was very important to our project. We learned not only how to implement it, but also many of its more interesting implications, such as the ability to find similar documents as shown in several of the pictures and its ability to add and subtract document vectors. We also had to use higher level vector spaces, which are relatively difficult to comprehend. Furthermore, to be able to efficiently parse the data we used a natural language toolkit, which was took a while to comprehend as well. To be able to actually implement the programming, and validating that everything was working to plan we used a significant amount of high level math. Cosine Similarity involved both dot products and magnitude multiplication. Additionally, neural networks involve many different levels of calculus, especially multivariable calculus and partial derivatives.
What's next for Russian Twitter Bot Identification
The next step to take for RTTC is improving our Neural Network. There are so many different parameters to play with including the size of the network, the learning rate, the number and type of features, and even the optimization algorithm itself. Playing with these features could provides magnitudes of improvement to our model and would make it much more powerful. We could easily expand this network by implementing for measures such as turning hashtags into features before parsing the data, and training for more time on a more powerful computer would allow us to reach a better mathematical optimum. We could also implement some visualization algorithms for example t-sne which would allow us to see the data represented in a 3 dimensional plot. We had planned to implement t-sne at the beginning of the night however time constraints made it impossible for us to do so.
Built With
- csv
- gensim
- jupyter
- nltk
- numpy
- python
- scikit
- scikit-learn

Log in or sign up for Devpost to join the conversation.