-

Example of image to Bitmoji generation
-
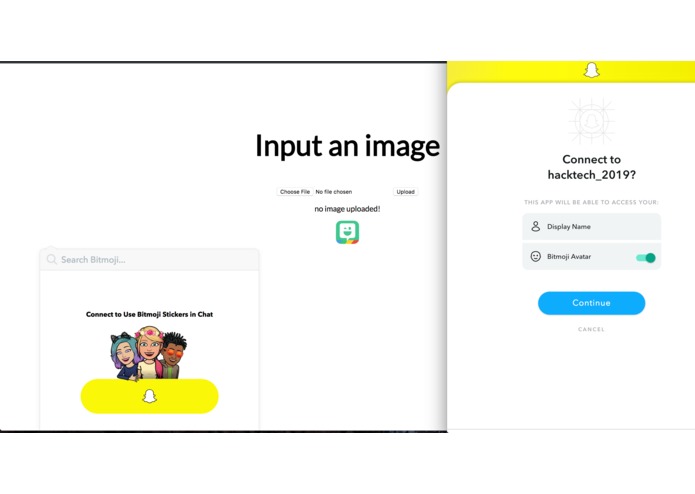
Snapchat authentication via SnapKit
-

Example of image to Bitmoji generation
-

An example of a bitmoji that can be generated programatically




Inspiration
Much of unsupervised learning is focused on finding accurate/stable embeddings in different domains. Initial algorithms such as word2vec focused on embeddings for text, but since then, the popularity of embeddings has grown, and they’ve become increasingly diverse.
Recently, there has been interest in embeddings involving emojis: specifically, groups such as Deepmoji have investigated text to emoji embeddings. To take a novel twist on emoji embeddings, we decided to investigate image to Bitmoji embeddings. One reason why we decided to investigate image to emoji embeddings was because intuitively, images lie in the visual domain, so it should be easier to map images to emojis. We also had access to an extensive emoji collection (Bitmojis), which made it easier to convey complex emotions/concepts found in images. Another reason why we investigated image to Bitmoji embeddings was because of its possible applications in social media, such as summarizing snapchat stories or snaps with a sequence of Bitmoji embeddings, or generating Bitmoji suggestions for Snapchat users once they take a snap.
Overall, we aimed to find more universal (stable/logical) emoji embeddings. Seeing as how image to emoji representation learning had not been done, we needed an alternative embedding method to compare against. This is where we decided to learn text to bitmoji embeddings.
What it does
As described above, we created two machine learning pipelines. The first aimed to represent images as a sequence of bitmojis. Specifically, we take an image, generate a caption for the image, and map that caption to the space of bitmojis. We chose to generate a caption to serve as our “image embeddings” as we needed a succinct way to represent images (as bitmojis are nothing essentially compress information). We then map these captions to the space of bitmojis, and return a sequence of bitmojis.
The second pipeline aimed to represent text as a sequence of bitmojis. Specifically, given any input text, the pipeline uses pre trained word embeddings along with a heuristic (what we called the “block method”), to transform text into a sequence of bitmojis.
The demo presents the first pipeline (image to bitmoji sequence), where the user is allowed to upload any image, and is returned an image caption along with a representative sequence of bitmojis.
How I built it
Pipeline 1:
- RNN trained on Flickr8 dataset (https://forms.illinois.edu/sec/1713398). Other datasets such as COCO or ImageNet have too many samples (we needed a quick, somewhat computationally cheap model that did an OK job at generating captions — not a state-of-the-art model)
- The general concept of this model consists of an encoder and decoder (as with many other representation learning models)
- Since we are mapping an image to a sequence of text (and emojis as follows), we have a CNN as our encoder (as CNN’s generally serve as good feature detectors).
- With a given hidden state, we use a LSTM with attention as our RNN to roll out a sequence from this encoded hidden state.
- These vectors can be converted to words (by looking at the initial dictionary of words the model builds) and emojis through embeddings (such as the one presented in Pipeline 2).
Pipeline 2:
- We are given as input a sequence of text representing a sentence
- We can convert this text to a tree using a variety of learned grammar representations
- We chose to use Stanford’s NLTK since with the time bounds of a Hackathon training our own was not feasible
- From this, we can recurse on the generated sentence tree, splitting on verb phrases and noun phrases. Bitmojis are generally representative of an entity performing an action or in a state of being, so this made sense to maximize the ability of our embedding to capture an Bitmoji space
- We can then match these sequences of text with ground truth text labels of Bitmojis, which allow us to choose the best Bitmoji that matches our selected sequence of text
- We can match by taking minimum distances in another embedding space of strings; again for brevity we chose to use Word2Vec and weighted sums of strings within a phase
Challenges I ran into (mainly backend challenges):
- Building a Flask web app w/ tensorflow (there were a lot of bugs with trying to run model tests on user inputted data)
- Dealing w/ lack of data: initially we wanted to have a model that directly learned image to bitmoji representations, but we but there is no public image to bitmoji dataset. We thus had to find and create datasets mapping image to text and mapping text to bitmojis for each of our pipelines.
- Optimizing DeepRNN: although we tried to limit the complexity of our model and go for the simplest class of models we thought (from various resources) that could decent job at captioning, the model still takes around 40s to generate caption for a given input image. This held back model evaluation and caption generation a lot. Eventually we were able to bring the time down to around 30s (though there is still a lot of room for improvement)
- Parsing grammatical trees presented a significant challenge since grammatical rules are not set in stone. Thus, there was no real way to deterministically parse a string into phrases that had any semantic meaning. We settled on the VP and NP cutoffs since they seemed to make the most sense with the context of emoji usage, but it took many iterations of changing the phrase cutoff criterion to get a reasonable result.
Accomplishments that I'm proud of
We are proud that our functional web app works well (so far) for most user inputted images. In particular, it works significantly better for images with people, which makes sense looking at the distribution of data in the Flickr8 dataset, as well as analysis of the sequences of output bitmojis, which helped give us some insight as to the potential of representation learning with bitmojis.
What I learned
We learned a lot about recent developments in representation learning, and had the chance to experiment with state-of-the-art models. Though we were familiar with the concept of representation learning, the work we did helped solidify our understanding of certain aspects of representation learning.
What's next for Seqmoji
We were able to provide a proof-of-concept for bitmoji representations, for both text and images. However, as seen, the results are definitely not optimal.
With respect to the image pipeline, we want to experiment with larger datasets (such as Google AI’s recently released 3M captioning dataset), parameter tuning, and perhaps a more complex class of models. We also want to explore omitting the captioning step and exploring ways to directly embed images with bitmojis.
With respect to the text pipeline, a lot of the code written was based on heuristics combined with word embeddings (which is what really helped us preserve information in the embedded space). However this could be more rigorously explored.
The main reason we were forced to segment our original idea into different pipelines was due to the lack of (image, bitmoji) data. Note that our pipelines could be used to generate such a dataset (or at least is a start towards such a dataset). We also wanted to try some sort of ensembling method to combine the two pipeline methods (with the intuition that combining two independent ways of arriving at bitmoji sequences would lead to more stable/universal embeddings, which is one of the reasons we started this project).
Built With
- css
- deep-learning
- flask
- html
- javascript
- machine-learning
- nlp-(parse-trees)
- python
- reinforcement-learning
- tensorflow


Log in or sign up for Devpost to join the conversation.