-
-
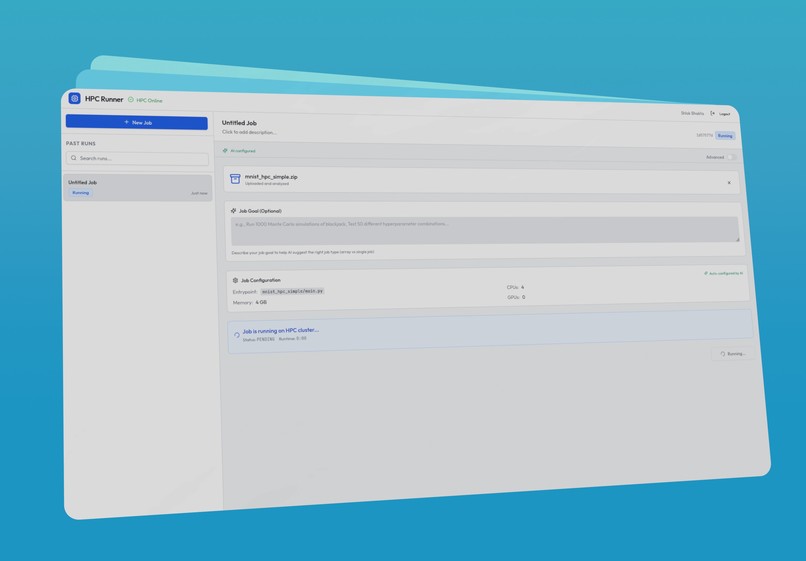
Job running
-
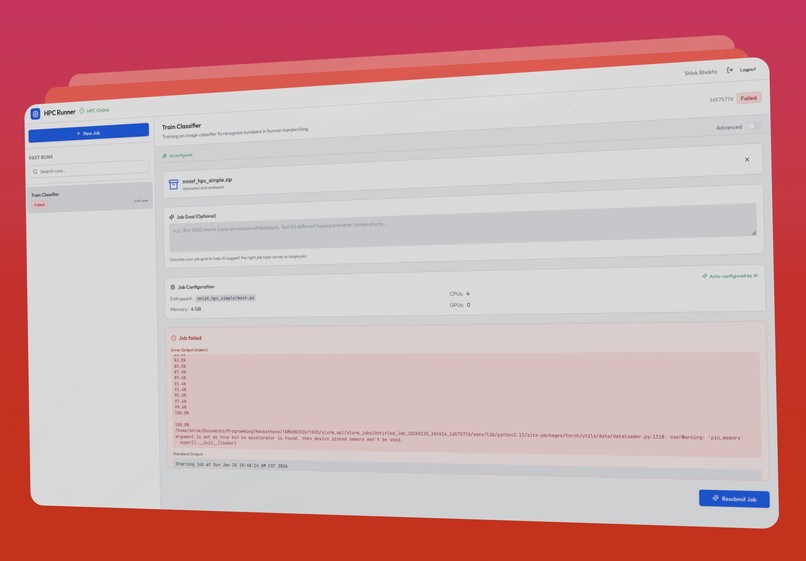
Job failing with error message
-
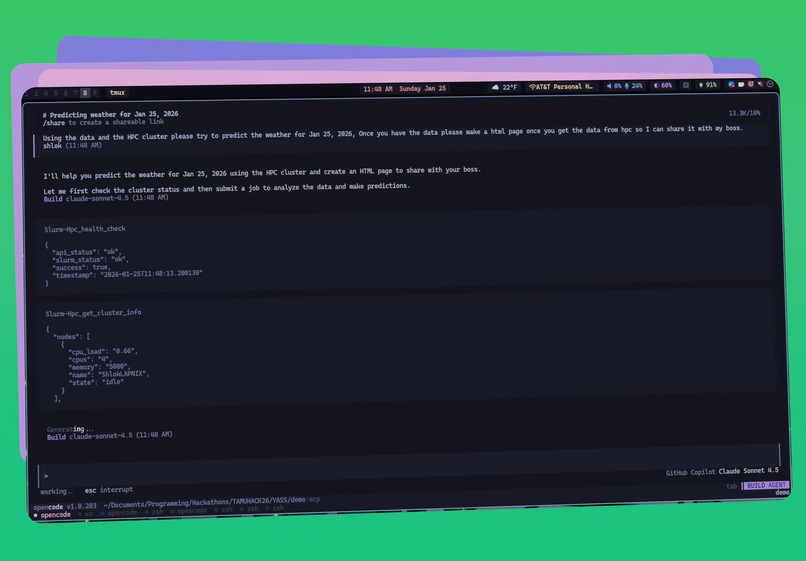
MCP



Inspiration
Researchers, students, and analysts often need large-scale computation, but are blocked by complex schedulers, scripts, and infrastructure.
What it does
Our project provides a simple web interface that allows users to run high-performance computing jobs without needing any knowledge of clusters, schedulers, or resource management. Users can upload a zip file containing their code and data, and our system automatically detects the program’s entry point and estimates the required compute resources.
Once submitted, users can monitor job progress in real time, view error logs if failures occur, and access results upon completion. For advanced users, we also offer an optional mode that allows manual specification of compute resources when finer control is needed.
In addition to the human-facing interface, we built an MCP server that enables AI agents to submit and manage high-performance jobs autonomously. LLMs can package necessary files, send them to our backend, retrieve results, and perform downstream analysis. This allows not only non-expert users, but also non-human AI agents, to access large-scale computing through the same unified system.
Together, these interfaces make high-performance computing accessible, flexible, and automation-ready.
How we built it (and creative use of AI)
HPC Runner is built around a multi-stage pipeline of specialized LLMs that analyze user intent and uploaded code. Each stage performs focused tasks such as entrypoint detection, dependency analysis, and workload classification using carefully designed prompts and structured outputs.
We use Gemini to inspect full project structures and source files to automatically determine how jobs should be executed. A separate classification stage identifies workload patterns and assigns confidence scores to guide scheduling decisions, while enforcing cluster constraints through prompt-level safeguards and output validation.
The platform is implemented with a React and Next.js frontend, a Python Flask backend, and a real SLURM cluster for job execution. Job metadata and results are stored in MongoDB, and user authentication is handled through Auth0.
Due to space constraints, we focus here on high-level design. Full implementation details and code are available in our GitHub repository.
Challenges we ran into
- Using SLURM's existing API, had to create our own API on top of slurm.
- Computer running out of storage
- No access to ACTUAL high performance compute, forced to use laptop with no GPU
- Team member lost his wallet
Accomplishments that we're proud of
We are proud of everything we built. Our project has had massive scope, and we've accomplished quite a lot. In no particular order we are proud of:
- Users upload code and describe goals in plain English
- Gemini analyzes code structure, detects entrypoints, classifies workload types
- AI classifies (parameter sweeps, single tasks, distributed jobs), deterministic systems calculate resources
- AI reads cluster limits from documentation (4 CPUs, 4GB RAM, 0 GPUs) with programmatic enforcement
- JSON parsing, schema validation, Zip Slip protection, automatic fallbacks with confidence scores
- Custom Python SLURM API, MongoDB persistence, Auth0 authentication
- System creates complete SLURM batch scripts that extract files, setup environments, install dependencies, run code
We have also successfully used our project to train hand written digit classification with the MNIST dataset, predict future weather outcomes, and simulate 100 blackjack hands.
What's next for HPC Runner
Future enhancements could include automated email notifications when jobs complete, as well as interactive result exploration. Users could discuss outputs with an LLM, generate charts and visualizations on the fly, and export data to platforms like Claude or ChatGPT for further analysis.









Log in or sign up for Devpost to join the conversation.