-
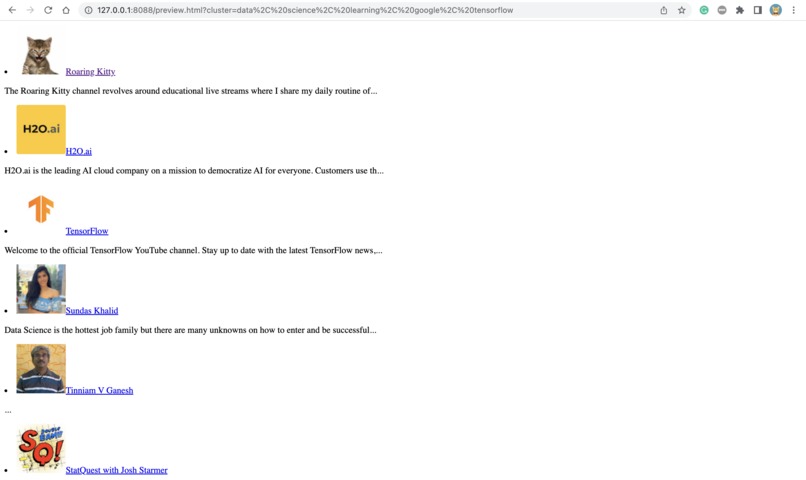
one of the clusters- Education
-
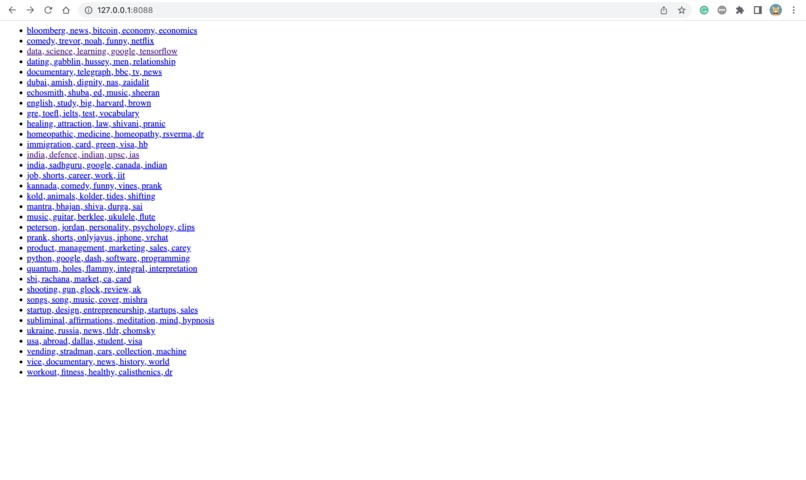
window-1 clusters from my youtube subscriptions
-

one of the clusters- Workout, Health



Inspiration
YouTube has a design flaw in the organization of subscriptions, making it difficult for users to navigate through their 100s or 1000s of channel subscriptions to find a particular channel.
What it does
SubzCat aims to solve this problem by using machine learning to cluster the user's subscribed YouTube channels into categories, making it easier to find a particular channel. The steps involved are:
- Collection of the user's subscribed YouTube channels and their metadata along with the keywords used in their latest 50 videos.
- Data cleaning of the collected information.
- Clustering of the cleaned data using a pre-trained SentenceTransformer ("all-mpnet-base-v2") to embed the documents into a continuous vector space, and normalizing the embeddings to perform Agglomerative Clustering on the embeddings using Euclidean distance and Ward linkage to form clusters.
- Associating each cluster with a cluster label by computing the top 5 keywords for each cluster using TfidfVectorizer.
- Presentation of the clusters along with their cluster labels and page navigation to a new page to display the channels in the cluster.
How we built it
The project was built using Python for data collection, data cleaning, and server development, a bit of JavaScript and HTML for website development. The AI model was developed using Huggingface transformers, sklearn, and scipy.
Challenges we ran into
- A team member with frontend skills dropped out last minute, but we still built a localhost web app.
- Optimizing and hyperparameter tuning the ML model was challenging, as it was a data-driven unsupervised clustering algorithm. Ensuring that the model is not sensitive to the clickbait keywords of the videos was challenging, and it took a lot of research and reading to arrive at the best model architecture and hyperparameters.
Accomplishments that we're proud of
Despite the two challenges, we accomplished the significant objective of clustering subscriptions into categories and developed a working prototype. We also learned to work under pressure and handle the non-availability of manpower with efficient resource planning.
What we learned
How to optimize ML models. How to visualize ML Clustering output and build a full-stack web app. How to work with team members of different age groups and backgrounds towards a common objective.
What's next for SubzCat
We plan to refactor and develop a CICD pipeline in production, improve the front end, and convert the localhost web app to a Chrome extension.





Log in or sign up for Devpost to join the conversation.