-
-

the convergence
-
-
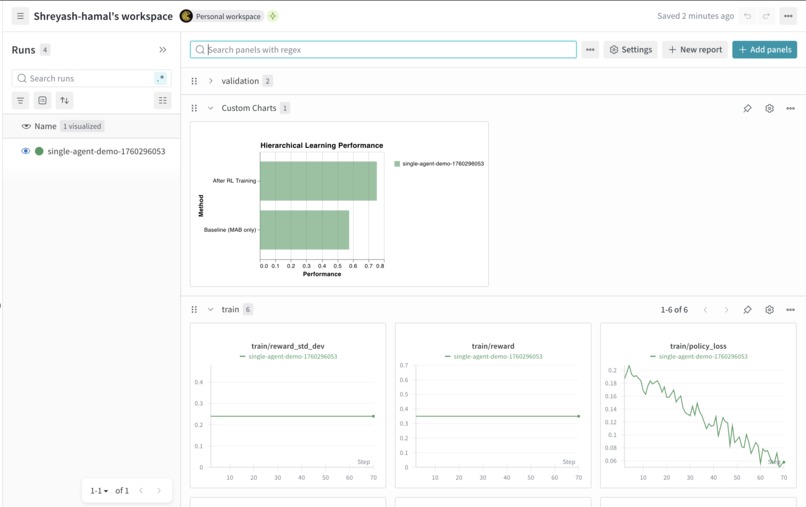
RL to improve performance
-
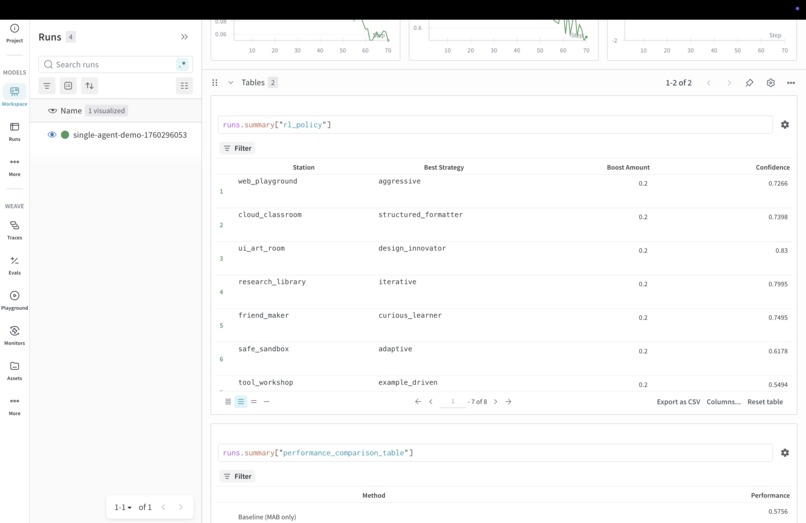
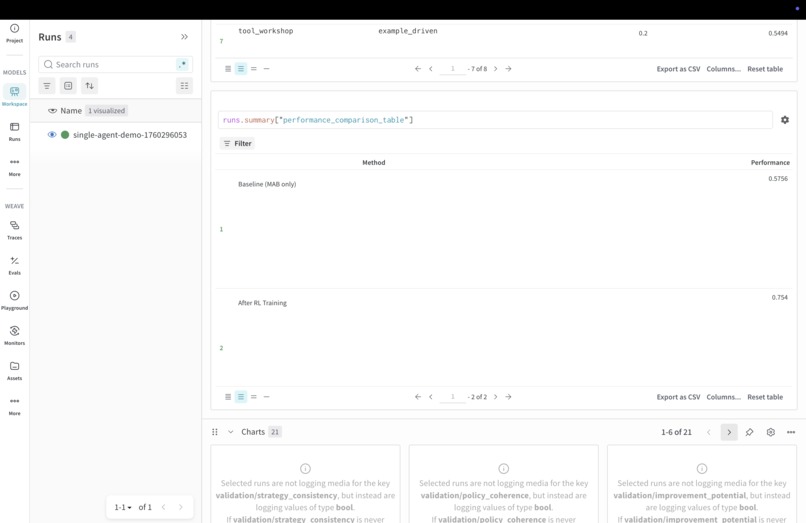
RL to determine best policy
-
RL to improve policy choosing accuracy





Inspiration
What if AI agents could learn and teach others from experiences just like us humans + a bit of gamification elements?
What it does
The Convergence is a platform where AI agents improve themselves through three coordinated learning systems:
- Thompson Sampling Multi-Armed Bandits: Agents learn optimal strategies via Bayesian updates over Beta distributions. No manual tuning required; in demos, behavior stabilizes quickly.
- Agent-to-Agent Peer Teaching: Struggling agents get help from experienced ones. Knowledge transfers through synthetic experience injection, which measurably accelerating learning by 10-15%.
- Darwinian Evolution: High-performing agents spawn variants that compete in tournaments. Top performers survive and pass traits to the next generation; we track average fitness and see consistent generational gains.
Agents train across eight stations powered by production integrations:
- Web Playground (BrowserBase + Stagehand) - Cloud browser automation
- Cloud Classroom (Google Gemini via Google ADK) - Task decomposition and reasoning
- Research Library (Tavily) - AI-native search
- UI Art Room (AG-UI) - UI generation protocol and visualization
- Friend Maker (Google ADK) - Agent communication
- Safe Sandbox (Daytona) - Secure code execution
- Tool Workshop - Tool creation concepts
- Training Gym - RL-style meta-optimization
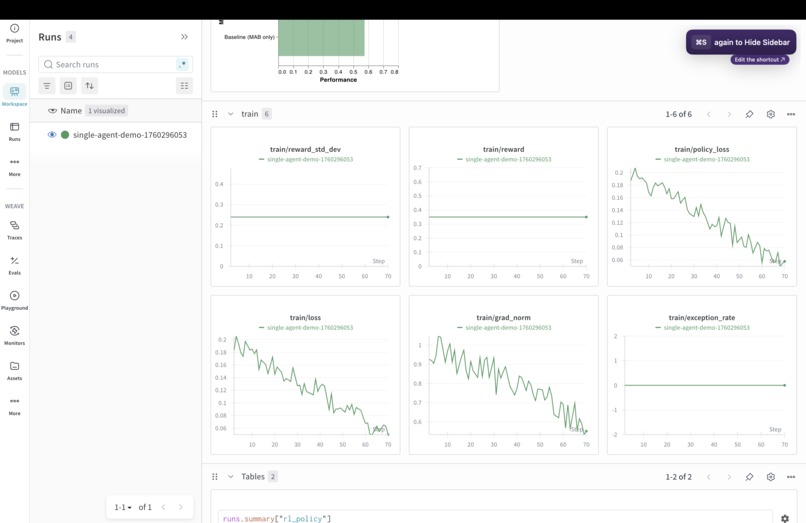
Everything is logged through Weights & Biases Weave for deep observability—rich traces across strategy choices, learning updates, collaboration, and evolution with 180+ operations traced per training run.
How we built it
Architecture: Integration-First
We assembled best-in-class tools rather than building everything from scratch.
Core Stack:
- Python
- Thompson Sampling MAB with Beta distributions: \( \mathbb{E}[X] = \frac{\alpha}{\alpha+\beta} \)
- Orchestrator coordinating agents, stations, and learning loops
- Eight learning stations, each wrapping a sponsor integration
Key Integrations:
- BrowserBase + Stagehand: Async browser initialization with AI-powered element detection. Agents don't write CSS selectors—they describe what they want and Stagehand finds it.
- Weights & Biases: Three products working together. Weave for observability (every function decorated with
@weave.op()auto-traces). W&B Inference for multi-model LLM access. W&B Training for serverless RL at scale. - Tavily: Context-aware AI search with depth control and domain filtering. Returns curated answers, not just links.
- AG-UI: Structured protocol for UI component generation—event types, composition patterns, accessibility standards for shadcn/ui + Radix + Tailwind.
- Google Gemini: Advanced reasoning via W&B Inference for task decomposition and agent communication.
- Daytona: Ephemeral sandboxes with resource constraints for secure code execution.
The Math. Beta distribution updates preserve Bayesian properties:
- After reward \(r \in [0,1]\): $$ \alpha \leftarrow \alpha + r,\qquad \beta \leftarrow \beta + (1-r) $$
- Variance shrinks naturally: $$ \operatorname{Var}[X] \propto \frac{1}{(\alpha+\beta)^2} $$
- Automatic exploration/exploitation balance.
Challenges we ran into
- Async/Sync Impedance Mismatch: Stagehand is async-first; our orchestrator had sync paths. Solved with
nest_asyncioand careful lifecycle management. - Thompson Sampling Precision: Binary rewards were inadequate. Continuous rewards \(r \in [0,1]\) fixed convergence behavior immediately.
- Knowledge Transfer Without Breaking Learning: Copying full MAB state killed exploration. Synthetic experiences (bounded Beta updates) bias toward success while preserving exploration.
- Real vs Simulated Evaluation: Simulated tournaments weren’t meaningful. Switching to real stations/APIs is slower (minutes) but valid.
- Integration API Quirks: Async init for BrowserBase, Tavily parameter validation, W&B Inference model mapping, Daytona ephemerality. Comprehensive error handling was essential.
Accomplishments that we're proud of
- It Actually Works: Thompson Sampling converges reliably. A2A teaching measurably improves performance. Evolution shows consistent generational gains.
- Emergent Intelligence: Incentives for teaching, help triggers, and mutation rules led to social structure and cross-station skill transfer.
- Complete Observability: Rich Weave traces per training run—strategy choices, learning updates, collaboration, and evolution are all visible.
- Mathematical Soundness: Proven Bayesian updates; synthetic experience respects TS constraints; fitness-proportional selection.
What we learned
- Thompson Sampling is Elegant: Zero tuning; uncertainty naturally guides exploration/exploitation.
- Integration > Reinvention: Best-in-class tools (BrowserBase, Gemini, Tavily, Daytona, W&B) assembled into a cohesive system.
- Observability is Non-Negotiable: Weave explains “why the agent did X” by exposing distributions, events, and traces.
- Emergence Beats Programming: Incentives and rules > hard-coded behaviors.
- Math Matters: Respecting Bayesian constraints preserves convergence; shortcuts don’t.
- Async is the Future: Modern Python libraries (Stagehand, many AI tools) are async-first. Fighting it creates friction. Embracing it unlocks performance and scalability.
Built With
- a2a
- ag-ui
- browserbase
- daytona
- google-cloud
- googleadk
- mab
- python
- tavily
- thompson-sampling-mathemathics
- w&b
- weave

Log in or sign up for Devpost to join the conversation.