In past articles I wrote how Python is useless for side-channel free programming and how you can debug code written with side-channel free processing in mind. But, you may ask how realistic are attacks like this, or how do side-channel attacks work in the first place. In this article I’ll show a simple network server, a script you can use to attack it, and few ideas how you can expand your side-channel knowledge.
I’ll skip the theory of statistical analysis and practical way of executing the test script reliably, if you’re interested in that, see the debugging code article and the tlsfuzzer documentation. That being said, to understand what we’ll be doing, you need to understand that small p-values indicate departure from expected result (where expected result in our case is “no discernable difference based on input”) and what 95% confidence interval means.
With that out of the way, let’s look at a server.
Server
In this example we’ll consider a simple server that expects a password and, in case the password is correct, replies with some kind of secret data. To make execution of the tests easier, and interpretation of the graphs more clear, let’s assume that the password in question contains only lower case Latin letters, i.e. ‘a’ to ‘z’.
The server code and test client is available on gist, you can compile the server with gcc:
gcc password_server.c -o password_serverThen execute it by running:
./password_serverIt will listen on port 5001 on all network interfaces.
The critical part of it is the loop that inspects the characters of the provided password (data) with the expected password (password) until either string ends (through newline character or null character):
/* check if all the letters match */
for (a=data, b=password; *a != '\n' && *a != '\x00' && *b != '\n' && *b != '\x00'; a++, b++) {
if (*a != *b) {
goto end;
}
}
/* check if length matches */
if (!((*a == '\n' || *a == '\x00') && (*b == '\n' || *b == '\x00'))) {
goto end;
}Now, since it aborts as soon as a letter is different, it will provide a side-channel signal. Question is, how big, and can we attack it?
Test client
While running the server is fairly simple, getting the client script running is a bit more involved. You’ll need to have python available (new enough for scipy and numpy to work) and permissions to run the tcpdump packet capture (easiest way to do it is by running the script as root).
First of all, download the tlsfuzzer repository:
git clone https://github.com/tlsfuzzer/tlsfuzzer.gitThen create a virtual environment and install the dependencies needed to run script and the statistical analysis:
python3 -m venv tlsfuzz-venv
tlsfuzz-venv/bin/pip install -r tlsfuzzer/requirements.txt -r tlsfuzzer/requirements-timing.txtThen as either user with permission to run tcpdump or as root, you can execute the test script against the server:
PYTHONPATH=./tlsfuzzer/ ./tlsfuzz-venv/bin/python3 ./test-passwd-guess.py -i lo -o /tmp --repeat 1000 --no-quickackThe PYTHONPATH environment variable tells python where to find the tlsfuzzer library, we specify python3 from inside the virtual environment so that it has access to the installed dependencies. The meaning of the options is as follows: -i lo specifies the interface on which the packet capture needs to be executed on (you will need to inspect output of ip addr ls to learn the interface name of external facing interface when running the test over real network), -o /tmp specifies where to keep the temporary files and the results, --repeat 1000 specifies that every letter needs to be used in 1000 connections, and finally the --no-quickack specifies that we don’t want to expect the TCP QUICKACK feature to be in use.
Internally, the script does something fairly simple: connects to the server, sends a password guess, expects error, and then connection close. The password guesses are just the 26 letters of the alphabet. In addition to that we have also the canary (or placebo) probe, that’s a second probe with letter ‘a’. By sending the probes in random order and measuring the response time from the server, we can effectively see if the server accepted the first letter of the password or not (as testing two letters for equality will take more time than testing just one).
Results
If you execute those commands on a typical system you will likely see the script report “No statistically significant difference detected”, or in more detail, summary that looks something like this:
Sign test mean p-value: 0.5348, median p-value: 0.5464, min p-value: 0.0009225
Friedman test (chisquare approximation) for all samples
p-value: 0.669298684947114
Worst pair: 5(e), 22(v)
Mean of differences: 6.99390e-06s, 95% CI: -1.42111e-06s, 2.193720e-05s (±1.168e-05s)
Median of differences: 4.00000e-08s, 95% CI: 1.00000e-08s, 7.000000e-08s (±3.000e-08s)
Trimmed mean (5%) of differences: 1.04511e-07s, 95% CI: 4.44867e-08s, 1.665733e-07s (±6.104e-08s)
Trimmed mean (25%) of differences: 7.88520e-08s, 95% CI: 2.81640e-08s, 1.227660e-07s (±4.730e-08s)
Trimmed mean (45%) of differences: 3.86200e-08s, 95% CI: 1.00900e-08s, 6.882000e-08s (±2.936e-08s)
Trimean of differences: 7.26250e-08s, 95% CI: 2.00000e-08s, 1.157937e-07s (±4.790e-08s)
For detailed report see /tmp/test-passwd-guess.py_v1_1697395170/report.csv
No statistically significant difference detectedWith accompanying graph looking like this:

Does that mean that there is no side channel leakage? No. As the 95% confidence intervals of both median and trimmed means are in the range of tens of nanoseconds (30ns and 29ns respectively) we cannot exclude the possibility of a side channel. This test was executed on an AMD Ryzen 5 5600X that can boost up to 4.6GHz, which means that the smallest side channel it can have is on the order of 0.2ns. So a small side channel would be undetectable with such a small sample.
OK, let’s execute the same test again, but with --repeat 100000 option. Now, after about 10 minutes of execution time, the test reports failure (it’s a failure as correctly implemented server wouldn’t have a side-channel leak), with the overall statistics that look like this:
Sign test mean p-value: 0.42, median p-value: 0.4144, min p-value: 1.545e-31
Friedman test (chisquare approximation) for all samples
p-value: 4.028330499541504e-44
Worst pair: 13(m), 15(o)
Mean of differences: 6.71613e-08s, 95% CI: -7.92283e-07s, 9.030701e-07s (±8.477e-07s)
Median of differences: -2.00000e-08s, 95% CI: -2.00000e-08s, -1.900000e-08s (±5.000e-10s)
Trimmed mean (5%) of differences: -1.81057e-08s, 95% CI: -2.57158e-08s, -1.146633e-08s (±7.125e-09s)
Trimmed mean (25%) of differences: -1.80656e-08s, 95% CI: -2.33658e-08s, -1.299852e-08s (±5.184e-09s)
Trimmed mean (45%) of differences: -1.89289e-08s, 95% CI: -2.21798e-08s, -1.605050e-08s (±3.065e-09s)
Trimean of differences: -1.77500e-08s, 95% CI: -2.25000e-08s, -1.675000e-08s (±2.875e-09s)
For detailed report see /tmp/test-passwd-guess.py_v1_1697385326/report.csvBoth the Friedman test has a statistically significant p-value, and the smallest sign test p-value is small enough to be significant.
But the graphs of the confidence intervals of the means still are not clear:

That’s because I’ve executed the script on a machine with no special configuration, with other workloads running at the same time (I had no core isolation set up and I was watching YouTube in the meantime). If we take a look at the ECDF of the collected measurements, we’ll see that there’s a huge spread (of over 7 orders of magnitude larger than the difference we want to measure) in the calculated differences:

And looking at heatmap of the differences, the data not only has long and heavy tails, it is clearly multi-modal (in this case we see 3 clear modes):

Thankfully, there are simple ways to work with such data, we can either look at the confidence interval of the median (here it it’s limited by the resolution of the clock source the kernel decided to use):

Or at the confidence interval of the trimmed means:

In both of those graphs, clearly the class 13 is the outlier. By looking at the legend.csv or at the report, we can deduce that class 13 corresponds to ‘m’, so the first letter of the password is “m”.
With this information we can ask the script to start looking for the second letter:
PYTHONPATH=./tlsfuzzer/ ./tlsfuzz-venv/bin/python3 ./test-passwd-guess.py -i lo -o /tmp --repeat 100000 --no-quickack --base mThat will provide us with a summary like this:
Sign test mean p-value: 0.4052, median p-value: 0.4143, min p-value: 3.179e-25
Friedman test (chisquare approximation) for all samples
p-value: 2.0606607949733857e-53
Worst pair: 1(a - canary), 20(t)
Mean of differences: -4.81858e-08s, 95% CI: -6.41017e-07s, 5.886469e-07s (±6.148e-07s)
Median of differences: -1.90000e-08s, 95% CI: -2.00000e-08s, -1.000000e-08s (±5.000e-09s)
Trimmed mean (5%) of differences: -1.38332e-08s, 95% CI: -2.02997e-08s, -7.578911e-09s (±6.360e-09s)
Trimmed mean (25%) of differences: -1.68099e-08s, 95% CI: -2.17857e-08s, -1.185134e-08s (±4.967e-09s)
Trimmed mean (45%) of differences: -1.55797e-08s, 95% CI: -1.82030e-08s, -1.287140e-08s (±2.666e-09s)
Trimean of differences: -1.62500e-08s, 95% CI: -2.00000e-08s, -1.000000e-08s (±5.000e-09s)
For detailed report see /tmp/test-passwd-guess.py_v1_1697386248/report.csvAnd a graph like this:

Does that mean that all letters are valid? No. Since the script uses ‘a’ as the baseline (class 0) and as the placebo/canary probe (class 1), and in the graph we’re comparing all classes to the baseline, only the canary probe will match it. Which means that the second letter of the password is ‘a’.
Exercises for the reader
We’ve cracked first two letters of the password in mere 20 minutes of machine time despite the side-channel being equivalent to around 75 CPU clock cycles. Given that, you can try few things to have a better feel for the side-channel attacks:
Try to set this setup yourself, decode remaining letters of the password. As I wrote, the only special thing you need to do, is have the permission to execute tcpdump, any other configuration will just require fewer connections.
Take the server application and execute it at a different system: either connected to the same network switch or few network hops away (use the -h option of the script to specify a remote host). How does the size of the sample necessary to detect side-channel change?
Look at the statistical results of the sign test and Wilcoxon signed-rank test in the report.csv file. How do they correlate with the graphs? Note: keep in mind Bonferroni correction.
Run the server on a specific CPU core together with some other heavy load (like sha1sum /dev/zero). Does that hide the side channel?
Try to modify the server code so that it is processing the password in side-channel free way.
Experiment with adding random delay to processing. Why that doesn’t help to hide the side-channel signal?
 as the generator,
as the generator,  as the prime,
as the prime, 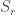 as the server selected random,
as the server selected random, 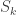 as the server key share,
as the server key share,  as the client selected random and
as the client selected random and 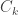 as the client key share, and
as the client key share, and  being the agreed upon secret, the server performs following operations:
being the agreed upon secret, the server performs following operations:
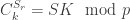
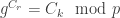

 both parties agree on the same
both parties agree on the same 