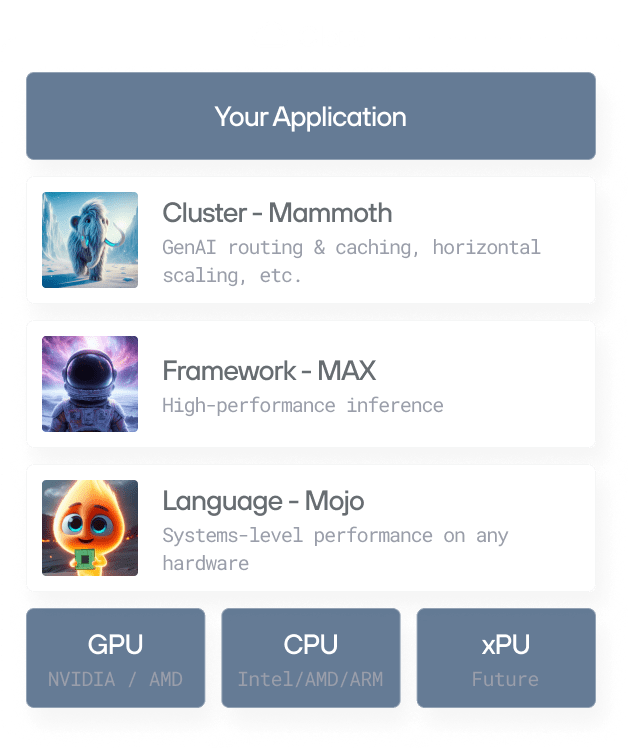
GPU portability for the world's most demanding AI
Our AI infrastructure powers the most advanced AI workloads to achieve unparalleled performance hosted in your cloud environment, or in ours.
Start with Modular Community Edition Free:
500+ GenAI models
Customizable
Open source implementation
Portable across NVIDIA & AMD
Tiny containers
Multi-hardware support
Multi-cloud deployment
Full hardware control
Great documentation
State-of-the-art performance
~70% faster compared to vanilla vLLM
"Our collaboration with Modular is a glimpse into the future of accessible AI infrastructure. Our API now returns the first 2 seconds of synthesized audio on average ~70% faster compared to vanilla vLLM based implementation, at just 200ms for 2 second chunks. This allowed us to serve more QPS with lower latency and eventually offer the API at a ~60% lower price than would have been possible without using Modular’s stack."

Igor Poletaev
Chief Science Officer - Inworld
Slashed our inference costs by 80%
"Modular’s team is world class. Their stack slashed our inference costs by 80%, letting our customer dramatically scale up. They’re fast, reliable, and real engineers who take things seriously. We’re excited to partner with them to bring down prices for everyone, to let AI bring about wide prosperity."

Evan Conrad
CEO - San Francisco Compute
Confidently deploy our solution across NVIDIA and AMD
"Modular allows Qwerky to write our optimized code and confidently deploy our solution across NVIDIA and AMD solutions without the massive overhead of re-writing native code for each system."

Evan Owen
CTO, Qwerky AI
MAX Platform supercharges this mission
"At AWS we are focused on powering the future of AI by providing the largest enterprises and fastest-growing startups with services that lower their costs and enable them to move faster. The MAX Platform supercharges this mission for our millions of AWS customers, helping them bring the newest GenAI innovations and traditional AI use cases to market faster."

Bratin Saha
VP of Machine Learning & AI services
Supercharging and scaling
"Developers everywhere are helping their companies adopt and implement generative AI applications that are customized with the knowledge and needs of their business. Adding full-stack NVIDIA accelerated computing support to the MAX platform brings the world’s leading AI infrastructure to Modular’s broad developer ecosystem, supercharging and scaling the work that is fundamental to companies’ business transformation."

Dave Salvator
Director, AI and Cloud
Build, optimize, and scale AI systems on AMD
"We're truly in a golden age of AI, and at AMD we're proud to deliver world-class compute for the next generation of large-scale inference and training workloads… We also know that great hardware alone is not enough. We've invested deeply in open software with ROCm, empowering developers and researchers with the tools they need to build, optimize, and scale AI systems on AMD. This is why we are excited to partner with Modular… and we’re thrilled that we can empower developers and researchers to build the future of AI."

Vamsi Boppana
SVP of AI, AMD
SOTA Performance
Speed of light performance at every level
We own the entire stack to deliver unprecedented performance - the latest models, running at incredible speeds, on the most advanced hardware.
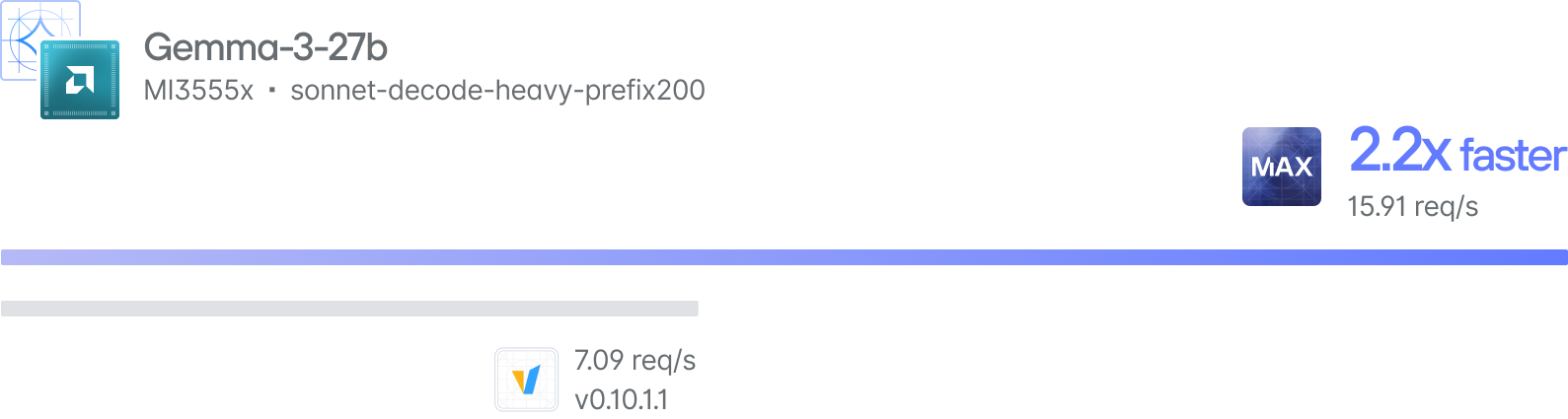
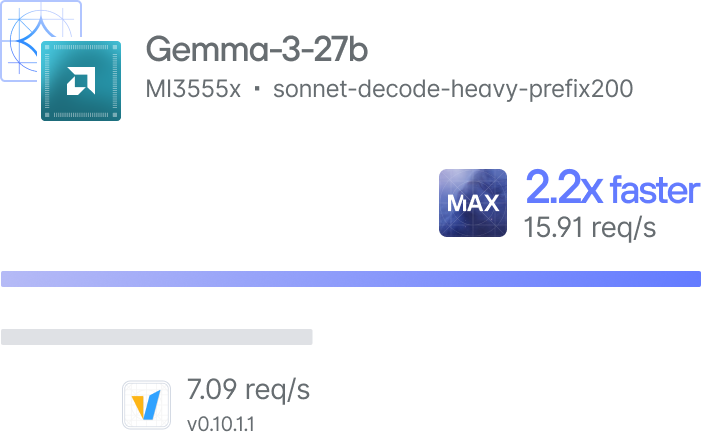

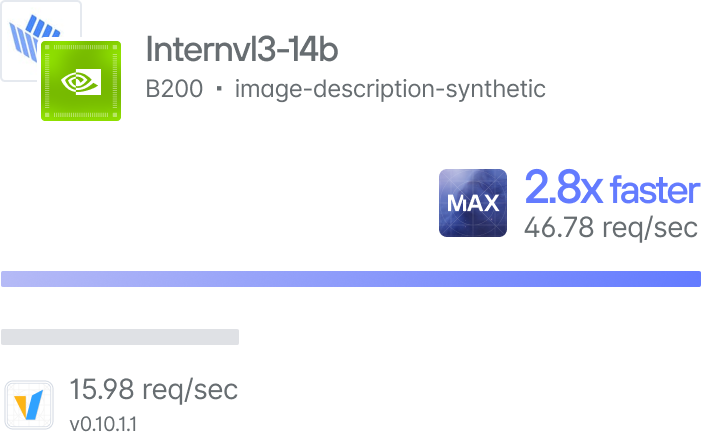

Case Study - 2x cost savings with the fastest text-to-speech model ever
2.5x cost savings and 3.3x latency improvements

Performance out-of-the-box
We enable performance that surpasses CUDA limitations with unprecedented simplicity out-of-the-box. See how we do it on our latest blog post.

Drive Total Cost Savings
When we deliver speed at scale, we’ve been proven to bring Enterprise costs down by up to 60%. Read a recent case study for how we did it with text-to-speech.

Scale from 1 GPU, to unlimited
Kubernetes-native control plane, router, and substrate specially-designed for large-scale distributed AI serving. Learn more about what powers our scalability.
Benchmark our performance
Everyone says they’re fast ... but we walk the walk. We empower you to test it for yourself. Find an optimized model and then follow our quickstart guide.
Hardware Portability
Achieve true AI hardware portability

Write once, deploy everywhere
Our breakthrough compiler technology automatically generates optimized kernels for any hardware target, eliminating the need for platform-specific code

Infrastructure Resilience
Break free from GPU vendor lock-in. Modular delivers peak performance across NVIDIA and AMD - resilient infrastructure that adapts to any compute type.
BEST-IN-CLASS
The most advanced teams
use Modular
Modular supports the entire AI lifecycle in one platform. Mojo for development, MAX for serving, and Mammoth for scale. Research to production will never be smoother.
Video - 70% lower TTS costs and 4x performance unlocking both NVIDIA and AMD GPUs for the first time
By unlocking optionality across the infrastructure, the application layer, and the hardware, Modular helped to power the best inference experience for Inworld's users through reduced costs and breakthrough latency.

Start anywhere, use what you need
Start with our free community edition. Scale using our Batch or Dedicated Endpoints, work with us to customize for your Enterprise.

Customize down to the silicon
Customize everything - model architectures to hardware-agnostic kernels. We helped Qwerky AI unlock 50% faster GPU performance.

Vertically integrated
Mojo's MLIR foundation delivers raw kernel performance. MAX adds kernel fusion and batching. Mammoth orchestrates everything across thousands of nodes.

Open source
We're democratizing blazing-fast AI by open-sourcing our entire stack. Join the mission. Explore our open kernels.
Details Matter
Smaller, faster & easier to deploy
90% smaller containers. Sub-second cold starts. Fully open source.
We eliminated deployment friction so you don't have to.
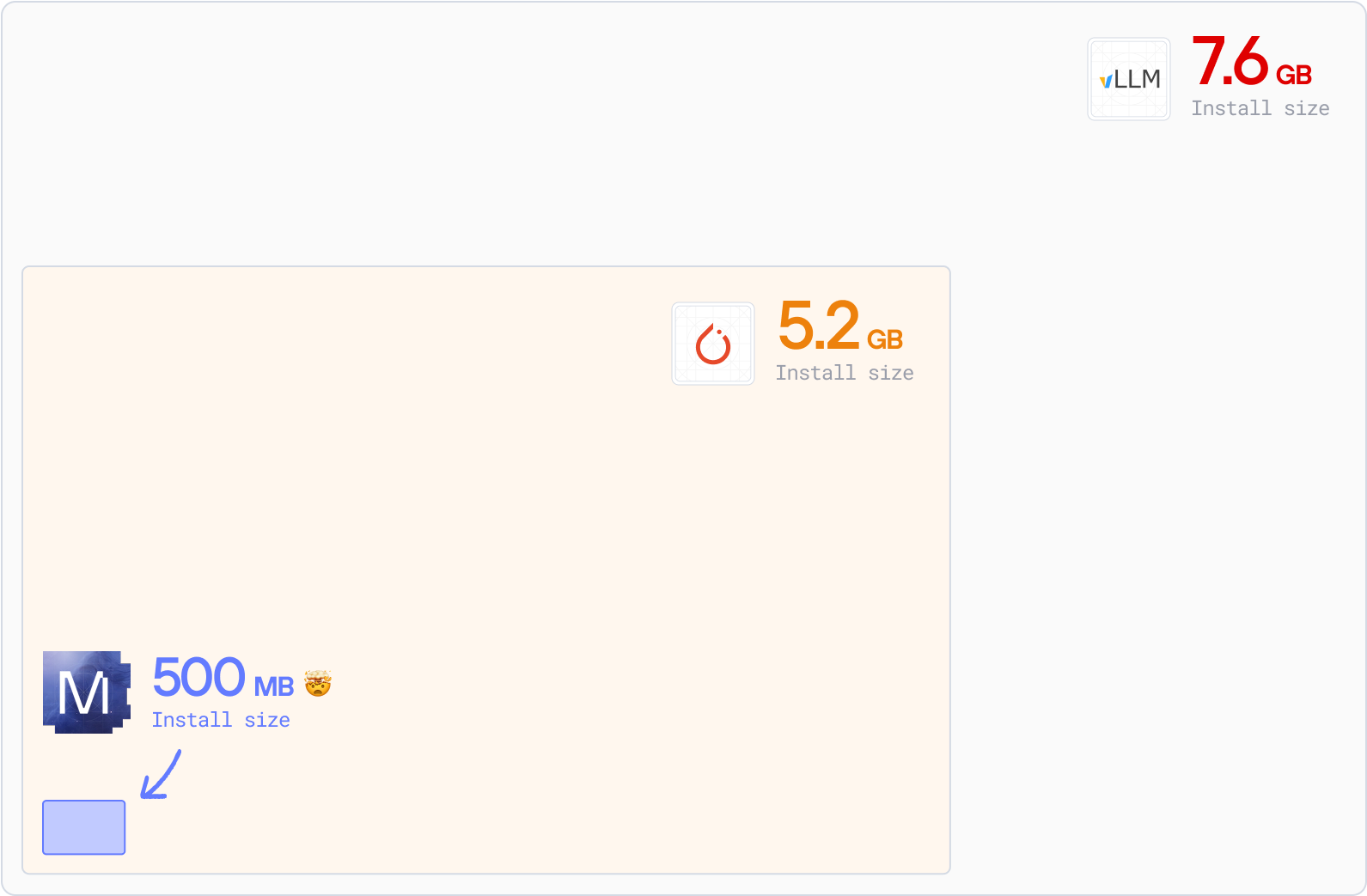
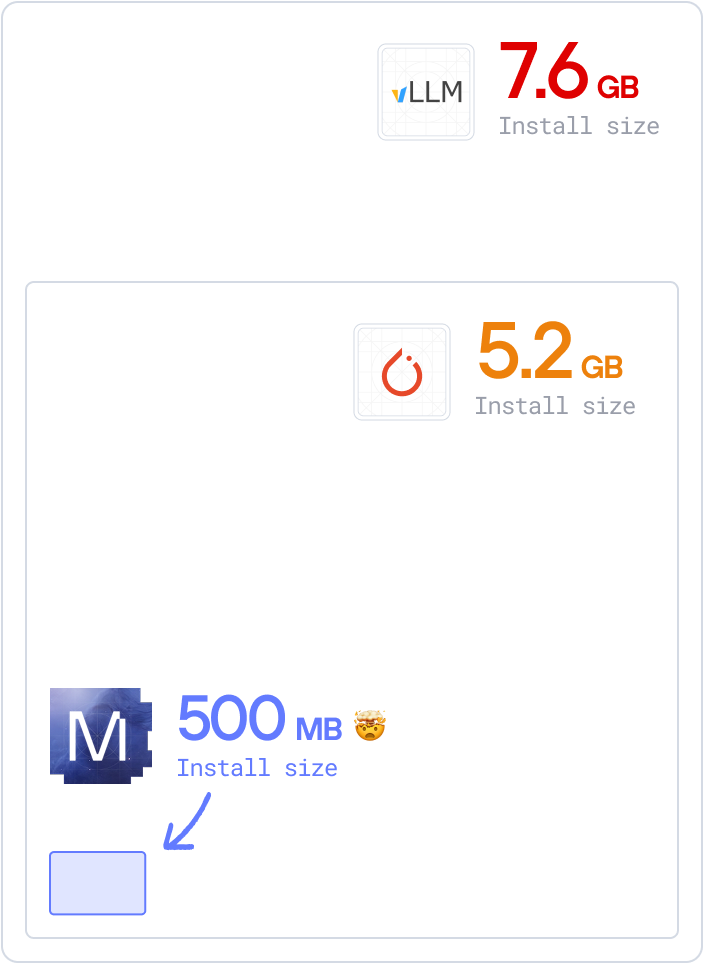

Faster build, pull, and deploy times
Minimal dependencies. Faster installs. Smaller packages. Smoother deployments. Less complexity, more speed. And more time for your engineers to deliver value.

Improved security
A leaner container reduces exposure to vulnerabilities, lowering compliance risks and potential downtime costs. A stack you have full access to customize yourself.
Lower resource consumption
- MAX serving: under 700MB. 90% smaller than vLLM. Reduce infrastructure cost — use less disk space, memory, and bandwidth. Get started with faster deployments now.

Simpler cross-hardware stack management
- No vendor lock-in. One stack for NVIDIA, AMD, CPU—any accelerator. Simpler deployment, easier debugging, unlimited possibilities.
Developer Approved


actually flies on the GPU
Sanika
"after wrestling with CUDA drivers for years, it felt surprisingly… smooth. No, really: for once I wasn’t battling obscure libstdc++ errors at midnight or re-compiling kernels to coax out speed. Instead, I got a peek at writing almost-Pythonic code that compiles down to something that actually flies on the GPU."

Community is incredible
benny.n
“The Community is incredible and so supportive. It’s awesome to be part of.”

12x faster without even trying
svpino
“Mojo destroys Python in speed. 12x faster without even trying. The future is bright!”

huge increase in performance
Aydyn
"C is known for being as fast as assembly, but when we implemented the same logic on Mojo and used some of the out-of-the-box features, it showed a huge increase in performance... It was amazing."

completely different ballgame
scrumtuous
“What @modular is doing with Mojo and the MaxPlatform is a completely different ballgame.”

very excited
strangemonad
“I'm very excited to see this coming together and what it represents, not just for MAX, but my hope for what it could also mean for the broader ecosystem that mojo could interact with.”

amazing achievements
Eprahim
“I'm excited, you're excited, everyone is excited to see what's new in Mojo and MAX and the amazing achievements of the team at Modular.”

The future is bright!
mytechnotalent
Mojo destroys Python in speed. 12x faster without even trying. The future is bright!
works across the stack
scrumtuous
“Mojo can replace the C programs too. It works across the stack. It’s not glue code. It’s the whole ecosystem.”

one language all the way through
fnands
“Tired of the two language problem. I have one foot in the ML world and one foot in the geospatial world, and both struggle with the 'two-language' problem. Having Mojo - as one language all the way through is be awesome.”

pure iteration power
Jayesh
"This is about unlocking freedom for devs like me, no more vendor traps or rewrites, just pure iteration power. As someone working on challenging ML problems, this is a big thing."
potential to take over
svpino
“A few weeks ago, I started learning Mojo 🔥 and MAX. Mojo has the potential to take over AI development. It's Python++. Simple to learn, and extremely fast.”

easy to optimize
dorjeduck
“It’s fast which is awesome. And it’s easy. It’s not CUDA programming...easy to optimize.”
feeling of superpowers
Aydyn
"Mojo gives me the feeling of superpowers. I did not expect it to outperform a well-known solution like llama.cpp."

was a breeze!
NL
“Max installation on Mac M2 and running llama3 in (q6_k and q4_k) was a breeze! Thank you Modular team!”

high performance code
jeremyphoward
"Mojo is Python++. It will be, when complete, a strict superset of the Python language. But it also has additional functionality so we can write high performance code that takes advantage of modern accelerators."

surest bet for longterm
pagilgukey
“Mojo and the MAX Graph API are the surest bet for longterm multi-arch future-substrate NN compilation”

impressed
justin_76273
“The more I benchmark, the more impressed I am with the MAX Engine.”

performance is insane
drdude81
“I tried MAX builds last night, impressive indeed. I couldn't believe what I was seeing... performance is insane.”

impressive speed
Adalseno
"It worked like a charm, with impressive speed. Now my version is about twice as fast as Julia's (7 ms vs. 12 ms for a 10 million vector; 7 ms on the playground. I guess on my computer, it might be even faster). Amazing."
Enterprise agreements
Built by the world’s best engineers, to handle the hardest problems at scale. We’re here to help you achieve the impossible.
Enterprise Support
flexible arrangements
Latest Blog Posts





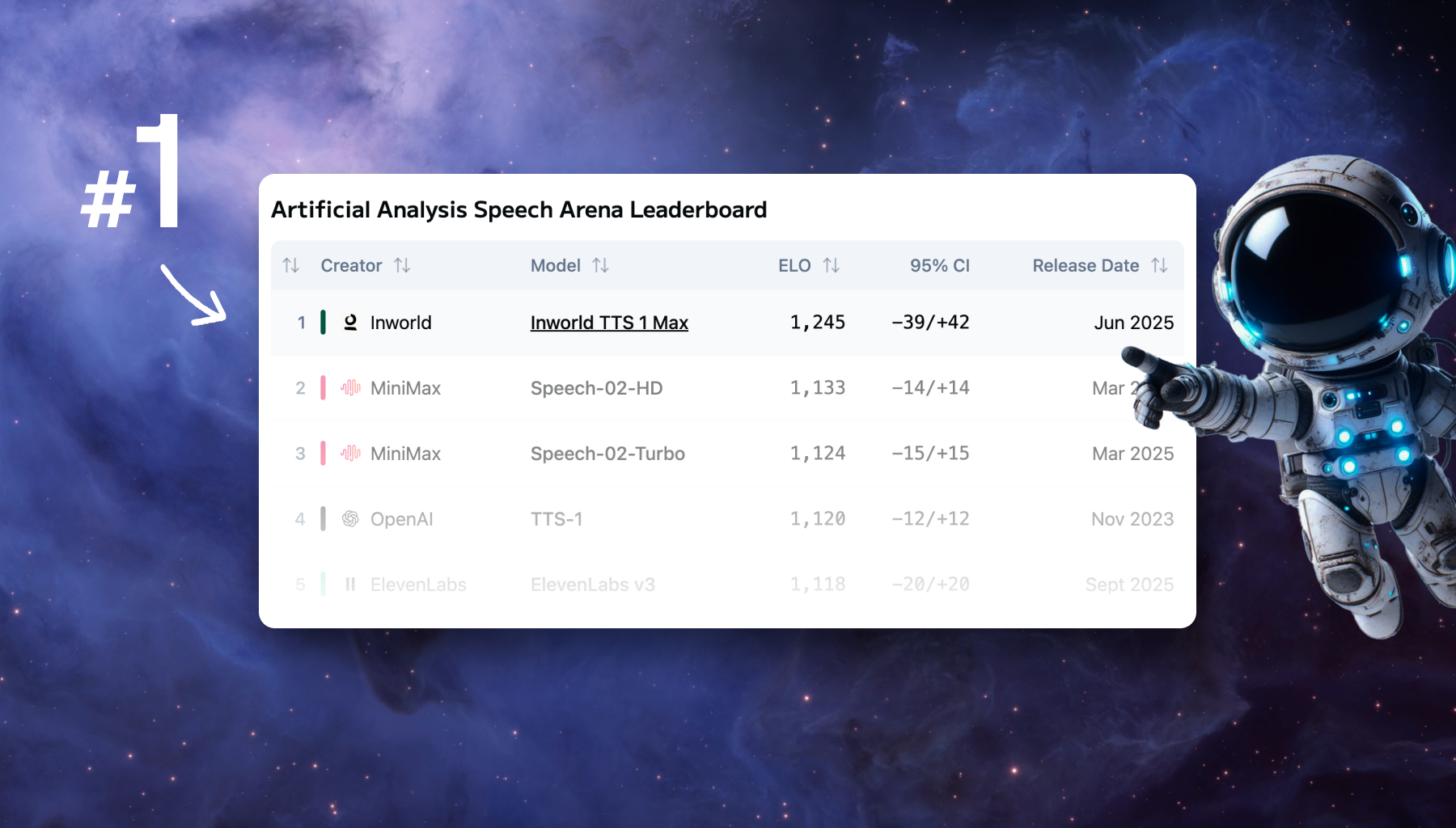





.png)








.png)



Get started guide
Install MAX with a few commands and deploy a GenAI model locally.
Read Guide
Browse open models
500+ models, many optimized for lightning-fast performance
Browse models