In these times, we all need some Mozart and what could be better than Neville Marriner and the Academy of St. Martin-In-The-Fields? Here’s the Adagio from the Serenade For Winds, K 361. You’ll remember it from the movie Amadeus.
AI feudalism
The tech optimists like to put forth a utopian AI future where there will be extreme productivity and economic surplus for all to enjoy. Yet, without an actual mechanism to distribute the gains, the most likely AI future is feudalism. Prior to the industrial revolution, almost all wealth came directly from the land and thus whomever controlled the land captured the wealth. Skilled artisans like blacksmiths and masons had some economic pull but really could only ply their trade if they had access to land or what lay beneath it, which made them subject to the whims of feudal lords that owned the land. The Enlightenment and industrial revolution made intellectual property a viable a path to wealth independent of land ownership. Liberalism and liberal democracy depends on the ability to benefit from the fruits of one’s labour.
An AI that can do anything a human can do would upend this liberal achievement because wealth gets tied back to land again. If we truly had an AI as capable as what the tech lords propose then you could run an entire economy without any humans. The only thing you would need is land to produce energy, grow food, extract raw materials, and run data centers. If you had no humans at all then you could even skip the food part.
While the tech optimists like to expound on a future where we all share in this immense wealth, history has shown us that the ruling class have rarely wanted to intermingle with the hoi polloi. In todays world, the billionaire class take their private jets and helicopters to hop from one private enclave (or island) to another. So it seems to me that a very plausible future is a feudal one with tech lords presiding over their court, while the rest of us fight it out in shanty towns. One way to prevent this is to make sure that the rest of us keep control of the land or at least tax away the extracted wealth. Otherwise, the tech optimists will be right about one thing: AI will indeed transform society. Just not in the direction most of us would prefer.
Demand side economics
Dario Amodei, the CEO of AI company Anthropic, has proclaimed that AI could lead to 10% to 20% growth in the GDP. He sees economic growth as a supply side issue; if we increase productivity then we will automatically produce more and increase growth. There is another view of the economy through a Keynesian demand side lens. GDP is defined as the sum of consumption, investment, government expenditures, and net exports. It is meant to be the total of all finished products sold in the country in a given year. These quantities are not independent. Take a toaster for example. If it gets sold in a store it counts as consumption but if is not sold by the end of the year and sits in the store then it counts as investment. If it is imported then it is subtracted from net exports so it doesn’t contribute to GDP at all. The government can juice GDP by spending more but then it has to get this money either from taxes or borrowing, both of which can affect consumption and investment. Thus for AI to make an impact it needs to increase consumption and/or investment. AI is technically already increasing GDP because of all the investment in data centers, which for 2024 actually contributed more to GDP growth than consumer consumption. But this is not what Dario meant. He meant that AI will do what people do now but faster and better and whatever you produce now you can produce more in the future.
Suppose you are a toaster company and AI allows you to produce twice as many toasters as you do now. What should you do with this new productivity? You could 1) Try to sell more toasters by lowering prices and/or spend more in marketing. 2) Add features and make more expensive toasters. 3) Make something else in addition to toasters. 4) Make the same number of toasters but give the staff more vacation time. 5) Make the same number of toasters and lay off staff. Toasters are already absurdly cheap compared to when I was a child yet I’m still only going to buy one if my old one breaks. The demand for toasters is capped by the population size. People don’t really want their houses full of toasters. This goes for most consumer products. It is true that houses are bigger now and we have more stuff than 30 years ago but this is not scaling forever. The average family went from having one to maybe two or three TVs over the past 40 years. The number has actually gone down from 15 years ago because we’re on our phones all the time now. We have only so many hours in the day to stare at a screen. Netflix famously said that it is only competing against sleep. Current GDP growth is around 2% to 3%. I don’t see how we will increase by a factor of five or more by selling more stuff so 1) seems out. How about making stuff more expensive? My toaster already does more than I really need to do so how many more features could you add? I personally don’t want a toaster that I can control with an App. I don’t want a gold plated toaster either. I’m pretty happy with a twenty dollar one that makes toast. You can make something expensive by making it rare (like a Birkin bag), but that doesn’t help boost GDP or take advantage of the AI productivity boost. So 2) is only a partial solution. 3) has the same problem as 1), we already have too much stuff. 4) ain’t happening under capitalism as we know it, which brings us to 5). Companies can increase profits by replacing people with cheaper AI.
Companies have already started laying off people under the cover of AI, which may nor may not be true, but if AI can replace a person then it will replace the person. However, people are responsible for consumption and if you have fewer people with good paying jobs then you have less money to go to consumption. The irony is that the business model of most tech companies relies on consumption. Amazon sells stuff. Apple and Tesla sell expensive stuff. Meta and Google sell ads for the consumption of stuff. The AI companies need consumers and companies with income to buy their product. Amodei has warned that AI will lead to job losses although he doesn’t seem too concerned that it will affect GDP growth. Perhaps, he thinks that we will figure out some sort of scheme to redistribute the gains from AI that will allow for more consumption or maybe the tech bros just haven’t fully thought this through.
Investing to socialism
Elon Musk in a recent interview claimed that in the near future, work would be optional, like gardening is today. Those who enjoy it could still do it whenever they wanted to take a break from the radical abundance that AI would provide. I thought it was an odd statement from perhaps the world’s premiere capitalist because a world without work is a world where the means of survival is no longer tethered to the fruits of one’s labour. As the economist Justin Wolfers pithily put it, the problem of the displacement of jobs by AI is not a technology issue but an ownership issue. Many (most?) of us would be delighted if we each owned a robot that we could send to work in our place everyday while we lived a life of leisure or play-acted work like Victorian aristocrats. Call me a cynic but I suspect that a more likely scenario is that a small cadre of tech overlords controls that AI and we’re at their mercy. So what exactly is their plan? No plan is one of the options. Why exactly are they pouring in a trillion dollars of investment into AI data centers when the only possible outcome of this investment is the world’s largest welfare state? Are these acolytes of Ayn Rand trying to build a socialist utopia? There must be a good German word for this delicious irony.
AI won’t take your job until it does
Since the advent of the industrial revolution, there has been concern that machines will take jobs and usually this is true. Machines do take jobs. The automatic loom took away weaving jobs. Trains took away pony express jobs. The usual process is that a technology comes along and it either increases the productivity of workers or replaces a job that humans used to do. However, historically the net effect is not a loss of jobs in toto. Instead, humans started doing other things, which expanded the economy in other directions, and that allowed other humans to do other things and so forth.
Is AI an ordinary technology that will displace some jobs while creating others or will it take away jobs? There are good arguments on both sides but I think the discussion glosses over an important point, which is that what happens with AI is a moving target that depends on the capability of AI. Unlike a technology like the wheel or air conditioning, the pinnacle of that technology is restricted to what it was meant to do. AI is different. The aim of AI is to replicate or supersede all human capabilities. So clearly, if an AI is developed that can do do anything and everything you do better and cheaper, it will replace you. The question is whether there is a limit to how good AI can get and this boils down to whether or not biology and the human brain is describable by the laws of physics. If you believe you or your mind is beyond physics then machines can never fully replace you. But if you believe in a mechanistic view of the universe where everything follows the same understandable laws (as I do), then there is nothing in principle that would negate human level or superhuman artificial intelligence.
I am certain that human level AGI is possible and will be attained within my lifetime but I no longer think it will be soon enough to make me obsolete before I retire. If anything, it may even prolong my career because it can compensate for my eventual (current?) decline. If you haven’t tried ChatGPT or Google Gemini or XAI’s Grok lately, I suggest you give it a whirl. The capabilities are simply astonishing. They write computer code, summarize scientific research, do mathematical calculations, and so forth. They are also far from perfect. They hallucinate, lose focus, and can forget what happened in a discussion just minutes ago. I used AI to write most of the code for a project I just finished. I have to iterate with it a lot and give it a lot of guidance but it can instantly generate hundreds of lines of code. It’s hard to tell if it increased my productivity given that it makes a lot of mistakes and I have to repeat steps over and over again. Perhaps, I could have gone faster if had I just wrote the code myself. But the AI models are getting better. AI leaders like Andrej Karpathy and Demis Hassabis think that several more breakthroughs are required before we get to full AGI but that labs are frantically working and they will come. Those that argue that AI will never reach human level intelligence because it just replicates the entire internet have either not kept up with the progress or don’t actually understand how models are trained. Learning from the internet is just a portion of what goes into an AI model and will be less and less important in the future.
The answer as to whether AI will take your job or be a productivity enhancer is yes. It will do both. It will help you with your job. It will create new jobs. As it gets better it will take jobs. How this all plays out is anyone’s guess. AI is like sea-level rise. As the water level rises, we run to higher ground, and that high ground becomes more and more valuable. It is most valuable right before it is submerged just as I will be most productive right before I am completely obsolete.
COVID exposed liberalism’s greatest gap
I argued in a post four years ago (see here) that Western Liberalism is inherently conflicted. By Liberalism, I mean the modern continuation of the philosophy that arose from the British enlightenment of the seventeenth century initiated by the writings of John Locke. In that previous post, I wrote of the inherent conflict between the “freedom to (do as one chooses)” and the “freedom from (oppression, bullying, …)”, now loosely represented by twentieth-century libertarianism and American New Deal liberalism, respectively. But what should be done if one’s personal choice oppresses another person? I argued that liberalism has no answer, and this conflict is just the tip of the iceberg of liberalism’s biggest problem, which was overtly exposed during the COVID-19 pandemic.
During the pandemic, public health officials would proclaim that their health directives such as social distancing, masking, shutting down schools, and so forth were merely “following the science”. I believe they meant it. They really did think that they were following the science, but science, as David Hume pointed out long ago, cannot make claims on moral choices. What they should have said was “according to my current take on the incomplete data that we have, l believe the somewhat draconian actions I suggest will minimize deaths due to COVID infection, and according to my personal moral principles is what I deem to be most important.” I strongly suspect that most of those officials and scientists don’t actually realize that their statements and actions are reflections of their personal moral philosophies rather than some scientific truth. I know because I myself was one of those people who was either blind to or in denial of this glaring gap. I only realized my delusion after many a discussion with a conservative thinker.
Philosophers have been grappling with this moral gap since the advent of liberalism. The Utilitarians such as Jeremy Bentham and John Stuart Mill believed that society should be designed to maximize happiness for the maximum number of people, but even they disagreed as to what constitutes happiness. John Rawls critiqued Utilitarianism and proposed a solution based on his “veil of ignorance” concept. He proposed that society should be designed such that a person who had no control of what attributes or segment of society they would be born into would find the most acceptable. It was “obvious” to him that most people would choose a society that made sure the worst off still had a pretty good life, which is what modern American Liberals advocate and is probably what someone with an upper-middle-class intellectual background would suggest. But this is simply not true. It is quite possible that some people don’t want to live in such a society. Maybe they would rather live in a world where a small set of individuals dominate the rest and take the chance of where they end up. Lots of people like to gamble and take risks. Plato advocated for rule by aristocrats, which meant “rule by the best” and not the modern usage of landed gentry. I don’t think it’s a stretch to suggest that many Silicon Valley power brokers would agree with this idea. There is simply no universally accepted view of what an ideal society would be.
In terms of COVID, many liberals have now come to accept that a more balanced response weighing factors such as the harm to children’s education, viability of small businesses, restrictions on personal freedom and speech should be considered along with minimizing death due to the disease. However, I don’t think they have fully grasped that there is still a glaring hole in Liberalism that can never be filled by Liberalism alone. In 1989, after the fall of communism, Francis Fukuyama suggested that we reached the “end of history” with Western Liberalism as a stable ideological fixed point. While he thought that it may not be a smooth process towards universal Liberalism and has refined his ideas since, he still fundamentally believes that Liberalism (more towards the libertarian view) will still win out in the end. I, personally, am not so sure. I think we will be lost for a very long time.
I don’t have any good answers but I do think the most relevant work on this question may be C.S. Lewis’s (yes, the same one) 1943 essay, “The Abolition of Man”, which addresses this gap and defends objective moral law, which he calls interestingly, “The Tao”. You may or not agree with it but this book may be one of the most insightful (and underrated) works of philosophy ever. I’m going to let you read it first before I give my take.
The rate of AI takeoff
Artificial General Intelligence or AGI means having cognitive capabilities as good as or better than humans in every facet. As I opined long ago (see here), while there is no inherent physical law to prevent AGI from exceeding humans, I doubt it would make economic sense to do so for everything. Is there really that much utility for a machine to be able to tell jokes better than any human? It’s not clear to me how anyone or any thing could be funnier than the late Sam Kinison anyway. It would take a lot of reinforcement learning in front of a lot of audiences and even then it might fail because comedy in the 80’s was just funnier (I’m purposely dating myself).
The real issue for society is when AGI will be able to do most jobs better than humans. I think AGI capability may come reasonably soon, maybe in the next few years but I think it will take some time before it completely upends society. AI aficionados believe in something called the intelligence explosion, where they believe that once AGI reaches a certain level they will then design new AGIs and iterate to infinite intelligence rapidly. Yet, even with iterative self-improvement there is still a wide range of possible AGI take off speeds depending on how exactly new AGI will increase the capacity of the next generation.
We can make this quantitative with a simple growth analogy. For population growth, if each member of the population reproduces at some fixed rate then the rate of increase will scale as the size of the population, like bacteria dividing in two and thus doubling the population every generation. This is classic exponential growth and can be represented by the ordinary differential equation:

where 


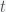



where 







for which 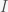
In exponential growth, it will take infinite time to get to infinity. There is no singularity, which would require

where 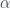


We can solve the differential equation by rearranging to obtain

and integrating both sides to get

where 


Notice that we have 


The rate of AI takeoff thus boils down to the values of
I use AI tools daily and I’ve gotten pretty good at getting them to do what I need them to do but I need to be quite specific and I often have to iterate multiple times before I get something useful. The biggest problem I have is that the AI forgets what transpired a few interactions ago, so I have to explain the problem over and over again. It’s kind of like working with someone without a hippocampus who will forget everything once it’s out of their immediate attention. Part of this will be solved with longer context windows. But having a completely viable AGI helper may require having a dedicated model whose weights are updated as you interact with it. All of this will require a lot more compute and that will be a rate limiting step for at least the next short while.
AI will increase productivity of AI research but for growth to explode, AI cannot be limited by anything other than itself. Even if AI takes over all research including designing hardware and building foundries and power plants, it still has to obey the laws of physics. The size of transistors on GPUs are limited by the structure and properties of matter. How fast information can travel is limited by the speed of light. How large buildings can be are limited by the strength of gravity. AI optimists seem to think that all problems are limited by intelligence but intelligence can only do so much. The theory of computation shows that there are problems that are just plain hard to solve no matter how smart you are. Biological systems are complex and contingent on random evolutionary quirks that must simply be discovered. From my own experience, I don’t think intelligence is the rate limiting step for progress in medicine. Most drugs fail because you just don’t know how a drug will behave unless you actually test it on lots of people, and that is just going to be slow. Being smarter might make the odds better but it will still take time to test. I thus think the jury is still out on how fast AI will take off. I am sure that I will be replaced someday but I’m really not sure when.
My obsolescence is nigh
Nine years ago I wrote a post, Alpha Go and the Future of Work, where I argued that the replacement of human work with AI was inevitable and that humans would have to figure out what to do with themselves. I hypothesized a possible non-dystopian future (I felt obliged to go against type and be optimistic in that post) where humans could live in a fabricated pre-industrial world doing low productivity but rewarding tasks like making pottery or writing poems while having most of our material needs met by machines. I also argued that mathematicians could still do mathematics since it was infinite and even if machines were better at it than us, we could still find open problems to explore and amuse ourselves. That post was written pre-ChatGPT and so I wasn’t sure when the machine takeover would happen but now it is clear to me that the time is soon if not now.
When OpenAI first introduced their GPT (which stands for generative pre-trained transformer) models a few years after I wrote my post, I was skeptical that it would get us all the way to AGI. (What used to be called artificial intelligence (AI) is now called artificial general intelligence (AGI) because AI is now used for what used to be called machine learning, which is what used to be called statistics). I was skeptical because GPT used supervised learning, which is limited by the data it is trained on. It was noticed around 2012 that deep learning model performance got better if you increased the amount of data, the number of parameters in the model, and the amount of computation (now called compute). (I notice that in the 21st century, verbs can be nouns and vice versa). The great improvements we have seen recently in AI is mostly due to the increase in these three quantities. While technical tweaks can help, generally bigger is better. That is why the big tech companies are scrambling to build larger and larger data centers. I’m still long on NVIDIA because even though newer smaller models can often do the same thing as older larger models (e.g. DeepSeek R1) there is still much to be gained by going bigger both in the training of the models and especially as I will get to more later, in the delivery.
What convinced me that AGI is around the corner is that the power of the current frontier large language models (LLM) like OpenAI’s ChatGPT-4.5 and Anthropic’s Claude3.7 Sonnet is all in the post training. To really understand why I need to explain how large language models work and are trained. Those in the know can just skip ahead. What these models do is take a sequence of tokens (tokens are like pieces of words) and predict the next token. The prediction involves a series of simple mathematical operations like matrix multiplication with a whole lot of adjustable parameters. Changing the values of the parameters changes the prediction. Pre-training involves comparing the predicted token with the actual token and then adjusting the parameters (using gradient descent) to make any discrepancy smaller. The pre-training phase involves taking these models, feeding it as much of the world’s written record as can be acquired, and then adjusting the hundred billion or more model parameters. This process can take months on thousands upon thousands of GPU’s (graphical processing units made mostly by NVIDIA) and costs multiple millions of dollars.
This phase is then followed by post-training, which is why ChatGPT will produce nicely organized paragraphs with an enthusiastic and polite tone (xAI’s Grok 3 will give you rude responses if you choose the unhinged mode). Post-training involves giving a model feedback on its responses to steer it in a desired direction. Part of this involves something called reinforcement learning (RL), which is how animals and humans mostly learn. In RL, a model (or animal) will modify its actions (called a policy) to maximize its predicted rewards (e.g. like being right or wrong or catching a rabbit). So you could give it a math problem (the model not the wolf) and instead of training it to match the solution explicitly as in pre-training, you simply let it try to solve the problem and then tell it if it is right or wrong. In this way, you let the machine figure out on its own how it should respond. You can also have it produce responses and ask humans to give feedback on the answers (i.e. reinforcement learning with human feedback, RLHF). RL is where the magic happens. It’s what was used to train Alpha Go. RL is what will take LLMs to AGI.
The CEO’s of the leading AI companies are predicting that AGI will arrive this year or next. I am generally a skeptic and a naysayer about tech hype but this time I’m convinced it will happen. I use LLMs regularly in my work and daily life and can see in real time how fast they are improving. All of them can pass the Turing test with ease. Sure they hallucinate occasionally and give wrong answers but so do humans. However, while AGI will arrive in principle very soon, it is not clear how long it will take to drastically change the world. One of the factors will be cost. AGI will be expensive and the bulk of that cost will be in the delivery. When an LLM generates a response it does so one token at a time. After it produces the first token, it adds it to the original sequence and runs the whole thing back through the model to get the next token. This is why the current models will limit how long an input, called the context length, can be. Right now context lengths are on the order of a hundred thousand tokens, with the Google models up to 2 million. The longer the context length, the more compute is required to generate responses. Additionally, models with some reasoning capability will run through the model multiple times and build on previous passes, verify responses, backtrack and correct errors, or just try out different responses and then pick the best one. This all requires a lot of compute. Advances are continuously bringing down this cost but whatever we end up with will cost more than a simple Google search. The increase in required compute, be it a hundred or a thousand fold, will require increasing the existing infrastructure by that factor. That will be a lot of data centers using a lot of energy.
Given this expense, the first jobs that AI will displace are those that are among the most high paying. As I mentioned in my post nine years ago, Alpha Go was easily able to defeat humans at Go not because it was particularly good at Go but because humans (in general) are really bad at it. The more practice, study, and training it takes for a human to do a task, the easier it will be for a machine to do it better. Thus, the jobs that require specialized skills, like computer programming, accounting, statistics, and applied math will be the first to be replaced. The things that humans do naturally, like guess which member of the tribe stole their lunch, will be the hardest for machines to replicate because those are capabilities that evolved over millions of years. That is not to say that machines using RL won’t be able to do them, just that it will likely take more time and compute. After all, natural selection is a form of reinforcement learning.
So sadly, I may be the last person to hold my job. I am fortunate that this is arriving in the twilight of my career so it doesn’t affect me that much but I feel bad for those younger than me. For example, I’ve been working on my software tool StochasticGene for the past five years, which builds on my work from the past decade. An AI agent will soon be able to recreate everything I’ve done in 30 seconds. It will also be easier for the AI to recreate my code from scratch rather than help me build from what I have because it’s much harder for the AI to understand what I’ve done and integrate changes into it without breaking something (which it has done several times already) then to just make its own code that will fit single molecule imaging data with stochastic models of gene transcription. I also feel that once an AI is better at my job than me then I should simply step aside. Unlike pure mathematics where nothing vital is really at stake, doing my job faster and better could possibly lead to a new treatment sooner. While I’m heartened that maybe this will accelerate medical research so that it will save a life someday, I am also very sad that I won’t get to do what I truly loved doing.
2025-03-24: I corrected a grammatical error in the first paragraph. Yes, I actually wrote this without using an LLM.
Toolkit for the physical world: Chapter 2 – All interactions are local
I still haven’t quite decided how to organize this series. I’ll stick with chapter numbers for now although these short posts hardly count as real chapters and the chapters don’t necessarily need to be read in order. I just need to try to get back into the habit of writing so bear with me as I try to figure this out.
A crucial thing to know about (our modern understanding of) the physical world is that all physical interactions are local. By this I mean that for thing A to affect thing B, thing A had to go out and “touch” thing B or send an agent to do the “touching” for it. There is no action at a distance without some mediator. Well what about radio and TV (mobile phones for any Gen Z readers) you might ask? Yes, the magic of modern technology allows us to use a device to hear voices and watch images from around the world. In fact, Newton kind of kicked off the quantitative science revolution by proposing that the moon stays in orbit around the earth because earth’s gravity exerts a pull on it. So how is that not action at a distance?
Well, this seeming contradiction is resolved by the concept of fields. Although a full understanding of a field requires some advanced physics like Maxwell’s equations, general relativity, and quantum mechanics, the gist of it can be understood quite easily. A field is a thing that has a value at every point in space. A gravitational field is the thing in space that pushes an object with mass in a given direction. The gravitational field is also induced by any object with mass. So the earth and moon both create gravitational fields that attract each other. They don’t crash into each other because they are moving so they kind of miss each other as they fall towards each other. Yes, it is confusing but trust me for now. Orbital motion is very well understood, so well understood that we can launch a spacecraft and land it on the moon or any planet.
I can hear some of you muttering that a field sounds like action at a distance to me. How can the earth set up a gravitational field that affects the moon? Yes, the caveat is that nothing can travel faster than the speed of light. So, it actually takes time for the earth to set up its gravitational field. If the earth were to suddenly disappear, the moon would not notice for a little more than a second, which is the time it takes light to travel from the earth to the moon. The gravitational field generated by the earth would dissipate as a complicated wave that was initiated at the former location of the earth. Same with when you turn on a light in a room. It seems instantaneous but it took time for the electricity to reach the bulb to generate light and then for that light to fill the room.
Locality is also true when it comes to biology and your health. Drugs work because the drug molecules travel through your blood stream and affect cells. A pain killer like Ibuprofen works because it inhibits the action of certain molecules. If you think some agent like microplastics or power transmission lines in the environment can cause illness then you need to come up with a local explanation of why and then test it. For example, microplastics might cause health problems by stimulating immune cells and cause excessive inflammation. But it’s a lot harder coming up with a plausible hypothesis for power lines. Power lines carry AC current at 50 or 60 cycles per second so they do induce radio waves but these wavelengths are on the order of thousands of kilometers. Microwaves have wavelengths on the order of ten centimeters and heat up tissue by inducing polarized molecules like water to vibrate and bang into each other thereby creating heat. Electromagnetic waves at very high frequencies like infrared radiation, visible light, and UV radiation can affect tissue but they are not generated by power lines. That is not to say that power lines couldn’t affect health but you need to come up with a plausible explanation with local interactions.
You can get quite far just using locality to try to understand how something can work or if it is reasonable. One of my pet peeves about science fiction movies is that you can see the laser beams in ray gun battles. Now, in order to see something, light had to enter your eyes. So to see a laser beam shooting from one point to another, some of the photons in the beam of light had to reach your eye. Well, why would that happen? If you were shooting through air some of the photons might scatter off of air molecules and enter your eye but that wouldn’t happen in the vacuum of space. If there is no scattering then there is no reason a well designed weapon would be visible, where you would want to concentrate all the energy on the target. A visible beam just means energy is being wasted. My series will have succeeded beyond all expectations if future movie goers become discerning enough to insist that laser beams not be visible in movies.
Toolkit for the physical world: Chapter 1 – Where do we start?
Obviously, I should have prepared Chapter 1 after I posted the Introduction but of course I hadn’t. I thought it would be easy to write these posts but then I got stuck in the “everything is connected” conundrum. Science is like an arch where all the stones need to be in place for it to stand. Everything relates to everything else. So like every other botched attempt to explain science, I’m going to have to blunder down the same path of introducing a lot of concepts that won’t fully make sense until they are all put together.
I’ll start with the main scientific premise, which is that science is objective – meaning that everything that happens is governed by a strict set of rules or laws, which we mostly understand. In principle, these laws of physics give us the tools to understand and explain all physical phenomena. But there’s a catch: these laws operate primarily at a microscopic level. What we observe at human scales is not always a direct application of these laws but the cumulative effect of their manifold applications.
A natural way to explain science would be to start with these laws. The world is made up of tiny elementary particles, and their movements and interactions are governed by four fundamental forces: gravity, electromagnetism, the weak nuclear force, and the strong nuclear force. There are also universal quantities, like energy and momentum, that are conserved. These laws form the backbone of how the universe works, but it’s not always obvious how they’re being applied.
A good rule of thumb is that the simpler the physical system—like the motion of a single particle—the easier it is to figure out which laws are in operation and how to make accurate predictions. But when it comes to more complex phenomena, like living organisms, there’s a myriad of microscopic actions playing out across a wide range of scales. Sometimes, out of this turmoil, new regularities will emerge—meta-laws, so to speak. These emergent meta-laws aren’t fundamental, nor are they entirely reliable, but they’re often just good enough to let us make predictions.
There’s no one-size-fits-all way to discover and use these meta-laws, and that’s what makes the practice of science both engaging and frustrating. It’s also what makes science so hard to explain to a layperson. How do you explain why we’re both confident and confused at the same time? Why we can answer some questions but not others? Why flimsy pieces of evidence sometimes carry more weight than they should? It’s why we occasionally succeed but often fail. The fundamental laws give us confidence that there might be a way to figure things out, but they don’t tell us how to find it. And sometimes, what looks like a meta-law turns out to be nothing more than us spotting patterns in randomness.
Science is two things: a vast body of accumulated knowledge that explains how the world operates, and the process by which we acquire and validate new knowledge that revises and updates the old. I’m always skeptical of what we think we know, but I trust the process. In fact, writing this series feels a lot like doing science. I don’t know exactly where I’m going or whether I’m doing it right, but I do know I can at least leave a trail—one that others can follow, improve, and fix.
Toolkit for the physical world: An introduction
I had trouble writing this post so I gave it to ChatGPT4o and asked it to fix it. This is what it came up with (after some further editing by me. I had to remove some (but not all) of the cheeriness for example):
I can’t remember the exact source—maybe a podcast like the BBC’s In Our Time or something I read—but it was about a public debate over a contentious scientific topic in the Victorian age. What struck me wasn’t the details of the topic itself, but how the discourse unfolded. The discussion revolved around the plausibility of competing hypotheses in light of existing data, with proposals for experiments to resolve the uncertainties. What stood out most was the shared, implicit assumption that the scientific method was the only valid way to uncover the truth. It was the kind of rigorous, data-driven reasoning we rarely see in the public sphere today.
This observation led me to reflect on a curious paradox: though our world is more reliant on science and technology than ever before, the public’s connection to science has diminished. During the Victorian age, science was widely admired—even romanticized—for its potential to reveal the secrets of the universe. Today, that admiration has waned. In popular culture, magic often eclipses science, both in entertainment value and in how it captivates the imagination. Just look at the way science is portrayed in movies: more often than not, it’s either a plot device for catastrophic hubris (Frankenstein, Jurassic Park) or a stand-in for magic (Iron Man, Doctor Strange). Arthur C. Clarke famously wrote, “Any sufficiently advanced technology is indistinguishable from magic;” it feels like many have skipped over the science entirely and gone straight to the magic.
Why has this disconnect grown? Part of the answer lies in the failures of science and the hubris of scientists—manifested in events like World Wars, nuclear weapons, climate change, social media’s unintended consequences, the COVID-19 pandemic, etc. I won’t delve into that here. Instead, I want to focus on another factor: the very nature of science itself. Thinking scientifically isn’t “natural” for the human brain. Our minds evolved to make quick inferences with limited data, spot patterns, and leap to conclusions—abilities that were essential for survival but are fundamentally at odds with the slow, methodical process of gathering evidence, testing hypotheses, and refining theories that science demands. Science, like playing the violin, is a skill that must be learned. It requires years of practice, patience, and, above all, the resilience to persist through repeated failure.
This leads to another challenge: science education. Understanding modern science and technology requires not only a grasp of the scientific method but also a large body of background knowledge. Physics, chemistry, biology, mathematics—the sheer volume of information is daunting. Compounding the problem is that science is often taught as a series of isolated facts, obscuring the process by which those facts were discovered. The messy, iterative, failure-ridden practice of science rarely makes it into the classroom, much less the big screen. And let’s face it: a realistic depiction of someone running failed experiments over months or years wouldn’t exactly be box office gold.
Yet the practice of science is what makes it so powerful. Hypothesis testing, experimentation, measurement, and iteration—these are the tools we’ve honed to understand the physical world. They’re slow and arduous, but they work. My greatest superpower, as someone who practices science, is the ability to fail repeatedly and keep going. That resilience is crucial because science is mostly failure—until it isn’t.
I thus want to write a series of articles outlining some essential concepts and tools you need to understand the physical world. You really just need to know a specific set of keystone concepts and a handful of practical tools, to navigate the complexities of the modern world. I hope these ideas will equip you to assess statements for their validity, distinguish fact from fiction, and evaluate statistical claims with a discerning eye. Whether it’s understanding the principles behind a medical study, interpreting the risks of new technology, or simply questioning “too-good-to-be-true” claims, these tools aim to allow you to cut through noise and misinformation. They’re not about mastering every detail but about recognizing patterns, asking the right questions, and applying a systematic way of thinking that empowers you to make informed decisions in a world driven by data and complexity. Through this series, I hope to provide a toolkit for understanding the physical world.
Selection of the week
There is no greater achievement of humanity than the Beaux Arts Trio playing Schubert’s Piano Trio No. 2 in E Flat.
The Physics of Refrigeration
Today, the high temperature for Baltimore was 37 Celsius, which is body temperature. Much of the US is experiencing a heat wave with many places in the south and southwest experiencing highs over 40 C. It’s pretty clear that without air conditioning (which is a room refrigerator), life in the summer would be unbearable. I think the refrigerator is one of the greatest inventions in history. Now of course things like writing, the wheel, the printing press, electric lights, etc. may have had more impact on the world but I think pumping heat (which is what a refrigerator does) is the greatest because it required an extremely deep understanding of physics and math before it could happen. It would be very unlikely to accidentally discover how to pump heat.
Given the importance of refrigeration and air conditioning to modern life, I think it is imperative that everyone knows how they actually work. People probably know that it involves some sort of refrigerant that is pumped around. They may even vaguely remember learning about the Carnot cycle in their high school or college physics classes. However, my guess is that many people don’t really get intuitively how a refrigerator works, unlike say a furnace, which they do get (i.e. it burns a fuel that makes hot air that is blown around the house, or it burns gas to heat water that is pumped around the house).
To make a refrigerator, there are a few things you need to know. The first is that there is this thing called energy that is conserved. This is known as the first law of thermodynamics. What is energy? Physicists and philosophers could debate that into the wee hours of the night but suffice to say it is a thing that can take many forms but cannot be destroyed. More importantly, energy can take the form of work (i.e. the ability to move something) or heat, which is a form of internal energy measured by temperature. The second thing you need to know is that heat flows from a higher temperature to a lower temperature. This is the second law of thermodynamics and has to do with entropy always increasing, which is a topic I will visit in the future.
The second law is less obvious than it seems. If you boil some water and leave it on the counter, it will cool down to room temperature. Heat flows out of the hot water and into the room. However, if you take a cup of cold water out of the fridge and leave it on the counter then it will warm up to room temperature. So, if you were not careful you would might believe things just flow to room temperature. The question is why did the cup get warmer but the room not get colder if heat flowed from the room to the cup. Likewise in the first example, the hot cup got colder but the room didn’t seem to change either. Why? Well it is because the room is really big compared to the cup and how much the temperature changes when you add or subtract heat depends on how much stuff (called heat capacity) you have. Removing a cup’s worth of heat from the room only changed the temperature by an imperceptible amount because the room has a lot of heat capacity. The excess energy was basically spread out over a large volume. Refrigeration is hard because you need to make heat flow from a cold area to a hotter area. The laws of thermodynamics, which are absolutely not obvious and one of the greatest human achievements, also explain why perpetual motion machines are not possible (another post perhaps).
The first two laws of thermodynamics still don’t tell you how to make a heat pump. They only tell you that it requires work (energy). But what work do you need to do? Most heat pumps use some form of compression and expansion cycle because when you compress a gas/fluid (i.e. do work on it) the temperature goes up and conversely when you let a gas expand against something like a piston (the gas does work) and the temperature will go down. Because energy is conserved, when you do work on a gas that energy is converted into heat or “internal” energy, which is manifested by an increase in temperature. When the gas expands against something it must use some internal energy and the temperature will decrease. Finally, most gases will cool down just by moving from high pressure to lower pressure through a small opening (called a throttle). This is called the Joule-Thompson effect and occurs because the gas molecules have an attractive force for each other (Van der Waals forces) and thus expansion requires work to pull them further apart.
Now, we almost have all we need to build a refrigerator. As you can anticipate, we will use expanding gas to cool our fridge. One possible design is to have a container of compressed gas with a throttle attached so the gas cools as it is released and expands. Pump this cool gas into the fridge where it can absorb heat from the inside of the fridge (heat flows from the warmer interior of fridge into the colder gas and heats that gas). Pumping out the gas and compressing it makes it a full cycle. Energy is used to pump the gas around and to compress it. This is called a reverse gas or Brayton cycle. It uses energy to move heat from a cold place to a warm place. In the forward direction, the Brayton cycle is a heat engine (in fact it is a jet turbine) where you convert heat into work. The problem with the Brayton cycle is that it is very inefficient (or impossible) to use as a heat pump at room temperatures or lower. This is because you can only get so much cooling when you throttle a gas at low temperatures (modern freezers can go down to -40 C).
Thus, most modern fridges and air conditioners use a vapour-compression cycle, where a liquid/gas combination refrigerant is used. The principle is similar, you get cooling by expansion but the added twist is you don’t just expand a gas but you let a liquid “boil” into gas when expanded. This will result in a much larger drop in temperature but requires finding a magical substance that is liquid at room temperature when under compression and then turns into gas when sent through a throttle. Freon, which is such a refrigerant, was invented in the mid-twentieth century and made refrigerators practical and affordable to the masses. However, Freon (and related CFCs) also destroyed the ozone layer that protects the earth from harmful UV rays and was internationally banned in 1994 in the Montreal Protocol. We should note that this beneficial agreement would not have happened so quickly if chemical companies hadn’t already found replacements (and could thus enforce new patent monopolies since the old ones had expired). Regulation can happen when the interests of capitalists are aligned. Something to note when dealing with climate change.
There is one final trick that makes the modern fridge/AC more efficient and that is when you compress the gas back into liquid, it raises the temperature to much higher than room temperature and even higher than the temperature in Texas during a heat wave (although barely). This hot liquid is then cooled by releasing heat into the less hot environment and giving it a head start before it passes through the throttle. A commercial heat pump is an air conditioner that can move heat in both directions. When it is in air conditioning mode the refrigerant expands and cools when inside the house and is compressed outside of the house and when acting as a heater it does the opposite.
Finally, it is actually possible to build a refrigerator with no moving parts using what is called the thermoelectric effect (Peltier effect) where passing electricity across a junction of two different materials can cause one side to cool down and the other heat up due to a quantum mechanical effect, which I may explain later). Now that you know the laws of thermodynamics and how a refrigerator works, explain why you can’t cool a room by leaving the fridge door open.
A short history of me
I was invited to write a short profile of my career for DSWeb this week. You can find it here.
The venture capital subsidy is over
Much has been written about the low approval of the current President and the general disgruntlement of the population despite conventional economic measures being good. The unemployment rate is low, wages are rising, and inflation is abating. The most logical explanation is that while the rate of inflation is slowing prices are still higher than before and while unemployment affects a few, high prices affect everyone. I think this is correct but one thing that doesn’t seem to be mentioned is that one of the reasons prices are higher and in some cases much higher is that many of the tech sector services that people relied on like ride share and food delivery were basically giving away their goods for free before and now they are not. Companies like Uber, DoorDash, and Grubhub were never profitable and were kept afloat by unlimited venture capital money, especially from SoftBank, and now this subsidy is gone. Now if you want a ride or get food delivered, you’re going to have to pay full price and this has made a lot of people really unhappy.
The subsidy was premised on the Silicon Valley idea that all start-ups need to “scale” until they are a virtual monopoly (like Amazon, Google/Alphabet and Facebook/Meta). However, the one thing that these tech strategists seemed to not consider is that scaling is useful when getting bigger means getting better, either by having lower cost, acquiring more data, or exploiting network effects. Scaling can work for search and entertainment companies because the more users there are the more data you have to determine what people want. It works for social network companies because the more people there are on the network, the more other people want to join that network. However, it doesn’t really work for delivery and transportation. Costs do not really decrease if Uber or DoorDash get bigger. You still need to pay a person to drive a car and the more miles they drive the more it costs. It could possibly scale if the cars were bigger and drove on fixed routes (like public transportation) but no one has yet to figure out how to scale point-to-point services. The pitch was that the tech companies would optimize the routes but that essentially means solving the “traveling salesman problem” which is NP-complete (i.e. cannot be easily solved and gets exponentially harder as the size gets bigger). Thus, while these tech companies got bigger they just burned through more cash. The primary beneficiaries were us. We got rides and food for next to nothing and now that’s over. However, it was not all costless. It hurt existing industries like traditional taxis, which were heavily regulated. One of the greatest failures in oversight was letting Uber operate in New York but that is another story.
Now these companies are either going bankrupt or increasing their prices. It is true that inflation is partially responsible for ending the subsidy because it led to higher interest rates which made borrowing more expensive but the reckoning would have to come sooner or later. Technological idealism does not obviate the laws of physics or capitalism – all businesses need to make money.
The myth of the zero sum college admission game
A major concern of the commentary in the wake of the recent US Supreme Court decision eliminating the role of race in college admission is how to maintain diversity in elite colleges. What is not being written about is that maybe we shouldn’t have exclusive elite colleges to start with. Americans seem to take for granted that attending an elite college is a zero sum game. However, there is no reason that a so-called elite education must be a scarce resource. Harvard, with its 50 billion plus endowment could easily expand its incoming freshman class by a factor of 5 or 10. It doesn’t because that obviously would make its product less prestigious and diminish its brand. It is a policy decision that allows elite universities like Harvard and Stanford to maintain their status. Being old is not an excuse. Ancient universities in Europe like the University of Bologna in Italy or University of Heidelberg in Germany, are state run and have acceptance rates well over 50%.
The main problem in the US is not that exclusive universities exist but that they have undue power. Kids are scrambling to get in because they believe it gives them a leg up in life. And they are mostly correct. All the Supreme Court Judges, save one, went to either Harvard or Yale law school. The faculty of elite schools tend to get their degrees from elite schools. High power consulting, Wall Street, and law firms tend to recruit from a small set of elite schools. Yet, this is only because we as a society choose it to be this way. In the distant past, elite colleges were basically finishing schools for the wealthy and powerful. Going to an Ivy league school was not what conferred you power and wealth. You were there because you already had power and wealth. It has only been in the past half century or so that the elite schools started admitting on the basis of merit. The cynical view is that world was getting more technical and thus it was useful for the wealthy and powerful to have access to talented recruits.
While it is true that the top schools generally have more resources and more research active faculty, what really makes them elite is the quality of their students. It is not that elite colleges produce the best graduates but rather that the best students choose elite colleges. Now there is an over supply of gifted students. For every student that is admitted to a top ten school there are probably five or more others who would have done equally well. This is not entirely a negative thing. Having talent spread across more universities is a boon to students and society.
As seen with what happened in California and Michigan, eliminating race-conscious admission will likely decrease the number of under-represented minorities at elite schools. But this only matters if going to an elite school is the only way to access to the levers of power and have a productive life. We could make an elite education available to everyone. We could increase supply by increasing funding to state run universities and we could take away the public subsidy of elite private schools by taxing their land and endowments. The fact that affirmative action still matters over a half century later is an indication of failure. There is talent everywhere and that talent should be given a chance to flourish.
Chat GPT and the end of human culture
I had a personal situation this past year that kept me from posting much but today I decided to sit down and write something – all by myself without any help from anyone or anything. I could have enlisted the help of Chat GPT or some other large language model (LLM) but I didn’t. These posts generally start out with a foggy idea, which then take on a life of their own. Part of my enjoyment of writing these things is that I really don’t know what they will say until I’m finished. But sometime in the near future I’m pretty sure that WordPress will have a little window where you can type an idea and a LLM will just write the post for you. At first I will resist using it but one day I might not feel well and I’ll try it and like it and eventually all my posts will be created by a generative AI. Soon afterwards, the AI will learn what I like to blog about and how often I do so and it will just start posting on it’s own without my input. Maybe most or all content will be generated by an AI.
These LLMs are created by training a neural network to predict the next word of a sentence, given the previous words, sentences, paragraphs, and essentially everything that has ever been written. The machine is fed some text and produces what it thinks should come next. It then compares its prediction with the actual answer and updates its settings (connection weights) based on some score of how well it did. When fed the entire corpus of human knowledge (or at least what is online), we have all seen how well it can do. As I have speculated previously (see here), this isn’t all too surprising given that the written word is relatively new in our evolutionary history. Thus, humans aren’t really all that good at it and there isn’t all that much variety in what we write. Once an AI has the ability to predict the next word, it doesn’t take much more tinkering to make it generate an entire text. The specific technology that made this generative leap is called a diffusion model, which I may describe in more technical detail in the future. But in the simplest terms, the model finds successive small modifications to transform the initial text (or image or anything) into pure noise. The model can then be run backwards starting from random noise to create text.
When all content is generated by AI, the AI will no longer have any human data on which to further train. Human written culture will then be frozen. The written word will just consist of rehashing of previous thoughts along with random insertions generated by a machine. If the AI starts to train on AI generated text then it could leave human culture entirely. Generally, when these statistical learning machines train on their own generated data they can go unstable and become completely unpredictable. Will the AI be considered conscious by then?
New Paper
Distributing task-related neural activity across a cortical network through task-independent connections
Nature Communications volume 14, Article number: 2851 (2023) Cite this article
Abstract
Task-related neural activity is widespread across populations of neurons during goal-directed behaviors. However, little is known about the synaptic reorganization and circuit mechanisms that lead to broad activity changes. Here we trained a subset of neurons in a spiking network with strong synaptic interactions to reproduce the activity of neurons in the motor cortex during a decision-making task. Task-related activity, resembling the neural data, emerged across the network, even in the untrained neurons. Analysis of trained networks showed that strong untrained synapses, which were independent of the task and determined the dynamical state of the network, mediated the spread of task-related activity. Optogenetic perturbations suggest that the motor cortex is strongly-coupled, supporting the applicability of the mechanism to cortical networks. Our results reveal a cortical mechanism that facilitates distributed representations of task-variables by spreading the activity from a subset of plastic neurons to the entire network through task-independent strong synapses.
Milo Time
Milo Kessler died of osteosarcoma on March 11, 2022. He was just 18. He was a math major and loved tennis. I never met Milo but I think of him often. I got to know his father Daryl after Milo had passed. Daryl created this podcast about Milo. It’s very well done and gives me comfort.
