
Finding neural network topologies is a problem with a rich history in evolutionary computing, or neuroevolution. This post will revisit some of the key ideas and outgoing research paths. Code related to this post is found here: [code link].
NEAT
In their 2002 paper, Kenneth Stanley & Risto Miikkulainen proposed the foundational algorithm NeuroEvolution of Augmenting Topologies (NEAT). I’ll focus on this algorithm as a starting point; for earlier developments please see Section 5.2 of this great review, Schaffer’s 1992 review, and Yao’s 1999 review. The NEAT paper introduces the ideas clearly and there are other great NEAT overviews, so to change it up I will try to present the algorithm with generic notation, which is perhaps useful for thinking about how to modify the algorithm or apply it to a new problem setting.
I’ve also made an implementation [code link] contained in a single python file; you might find it useful to see the entire algorithm in one place, or as a comparison if you also implement NEAT as an exercise. For a more robust implementation, see NEAT-Python (which the code is based on) and its extension PyTorch-NEAT.
Problem
NEAT addresses the problem of finding a computation graph 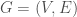



Searching through the space of these graphs amounts to searching through a space of neural networks. NEAT conducts this search using a few generic neuroevolution concepts, which I’ll focus on below, and often implements them with design decisions that can be relaxed or modified for different problems.
High-Level Method
NEAT iteratively produces a set of candidates 




The candidate set (“population”, rectangle) contains partitions (“species”, circles), each containing candidate graphs (diamonds).
Each NEAT iteration returns a new candidate set and new partitioning, denoted as 


Evolution Steps
Each evolution step 
Mutation 

An add-node mutation followed by an add-edge mutation. The add-node mutation splits an existing edge into two edges.
Crossover 



NEAT crossover mechanism (diagram from the NEAT paper)
Fitness Ranking follows its name, first ranking candidates according to fitness, 


Partitioning, or speciation, groups candidates according to a distance function 
Intuitively, a small partition contains graphs with relatively unique characteristics which might ultimately be useful in a final solution, even if they do not yield immediate fitness. To avoid erasing these characteristics from the search during fitness ranking, the small partition candidates receive guaranteed spots in the next phase.

Novel structures (diamonds, triangles) may ultimately yield a performance gain after further development, despite initially having lower fitness (light green) compared to common, developed structures with high fitness (dark green).
We can write this step as 

The partitions 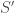
Example Results
Let’s use the implementation [code link] to solve an xor problem and the Cartpole and Lunar-Lander gym environments.
To solve xor, NEAT finds a network with a single hidden node:

An xor network, including input (green), hidden (blue), and output (red) nodes. Labels show edge weights and node activations.
CartPole-v0 is easy to solve (even random search is sufficient), and NEAT finds a simple network without hidden units (for fun we’ll also construct an artificially complicated solution in the Variations section below):

A CartPole-v0 network.
LunarLander-v2 is more difficult, and NEAT finds a network with non-trivial structure:

A LunarLander-v2 network.
On the xor environment, NEAT creates around 10 partitions, on Cartpole just 1, and on LunarLander it tends to create 2-3 partitions. On these simple environments NEAT also performs similarly without crossover.
Variations As mentioned before, we may want NEAT to produce a diverse set of solutions rather than a single solution. To manually demonstrate this intuition, suppose I want NEAT to find a network that uses sigmoid activations, and one that uses tanh. To do so, I increased the activation parameter in the node distance function (the 


While Cartpole is evidently simple enough for a network with no hidden layers, perhaps we want to follow a trend of using large networks even for easy problems. We can modify the fitness function to ‘reject’ networks without a certain number of connections, and NEAT will yield more complicated solutions:

A more complicated way to play Cartpole.
In particular, I added -1000 to the fitness when the network had less than k connections, starting with k=5 and incrementing k each time a candidate achieved max fitness at the current k (stopping at k=20).
Discussion & Extensions
Vanilla NEAT attempts to find both a network structure and the corresponding weights from scratch. This approach is very flexible and involves minimal assumptions, but could limit NEAT to problems requiring small networks. However, the key idea can still be applied or modified in creative ways.
Minimal Assumptions
NEAT represents an extreme on the spectrum of learned versus hand-crafted architectural biases, by placing few assumptions on graph structure or learning algorithm. At a very speculative level, such flexibility may be useful for networks with backward or long-range connections that may be difficult to hand design, or as part of a learning process which involves removing or adding connections rather than optimizing weights of a fixed architecture.
A more concrete example is the recent Weight Agnostic Neural Networks paper (Gaier & Ha 2019), where the authors aimed to find a model for a task by finding good network structures, rather than finding good weights for a fixed network structure; they use a single shared weight value in each network and evaluate fitness on multiple rollouts, with a randomly selected weight value for each rollout. In this case, a NEAT variant allowed finding exotic network structures from scratch, without requiring prior knowledge such as hand-designed layer types.
As a rough approximation, I modified the NEAT implementation so that each network only has a single shared weight value, and included more activation functions (sin, cos, arctan, abs, floor). Each run of evaluation sets the network’s shared weight to a randomly sampled value (![\mathcal{U}([-2,2])](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BU%7D%28%5B-2%2C2%5D%29&bg=ffffff&fg=404040&s=0&c=20201002)
![[-0.1,0.1]](https://s0.wp.com/latex.php?latex=%5B-0.1%2C0.1%5D&bg=ffffff&fg=404040&s=0&c=20201002)

XOR network with a random shared weight value
This was just an initial experiment to give intuition, so check out the WANN paper for a good way of doing this for non-trivial tasks.
Scalability
One could also consider improving NEAT’s scalability. A high level strategy is to reduce the search space by restricting the search to topologies, searching at a higher abstraction level, or introducing hierarchy.
An example is DeepNEAT (Miikkulainen et al 2017), which evolves graph structures using NEAT, but with nodes representing layers rather than single neurons, and edges specifying layer connectivity. Weight and bias values are learned with back-propagation. The authors further extend DeepNEAT to CoDeepNEAT, which represents graphs with a two level hierarchy defined by a blueprint specifying connectivity of modules. Separate blueprint and module populations are evolved, with the full graph (module + blueprint) assembled for fitness evaluation.

Blueprint and Module populations. Each node in a Blueprint (hexagon) is a Module.
This view is quite general, allowing learning the internal structure of reusable modules as well as how they are composed. In the experiments the authors begin with modules involving known components such as convolutional layers or LSTM cells and evolve only specific parts (e.g. connections between LSTM layers), but one might imagine searching for completely novel, reusable modules.
Indirect Encodings
NEAT essentially writes down a description, or direct encoding, of every node and edge and their properties, then evolves these descriptions. The description size grows as the network grows, making the search space prohibitively large.
An alternative is to use a function to describe a network. For instance, we can evaluate a function 

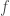
HyperNEAT (Stanley et al. 2009) uses this idea to find network weights by evolving an indirect encoding function. HyperNEAT uses NEAT to evolve a (small) CPPN to act as
Several works have adopted or extended ideas from HyperNEAT for a deep learning setting. Fernando et al. 2016 proposed the Differentiable Pattern Producing Network (DPPN) which evolves the structure of a weight-generating CPPN

From [Fernando et al 2016]

From [Ha et al. 2016]
Wrapping Up
In this post we revisited a core technique for generating neural network topologies, and briefly traced some of its outgoing research paths. We took a brief step back from the constraints of pre-defined-layer architectures and searched through a space of very general (albeit small-scale) topologies. It was interesting to see how this generality has been refined towards some larger scale tasks, but also revisited. We briefly saw how fitness re-ranking and partitioning can be used to yield a set of distinct solutions, which connects to other concepts that I may discuss further in future posts.
[Code]



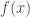 that minimizes the expected loss
that minimizes the expected loss 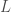 :
:![\hat{f}(x) = \arg\min_{f(x)}E[L(y, f(x))|x]](https://s0.wp.com/latex.php?latex=%5Chat%7Bf%7D%28x%29+%3D+%5Carg%5Cmin_%7Bf%28x%29%7DE%5BL%28y%2C+f%28x%29%29%7Cx%5D&bg=ffffff&fg=404040&s=0&c=20201002)
 and labels
and labels 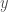 .
.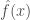 as a sum of weak learners
as a sum of weak learners 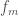 :
:
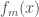 corresponds to passing
corresponds to passing  until it reaches a leaf node
until it reaches a leaf node 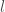 . The predicted value is then equal to a parameter
. The predicted value is then equal to a parameter 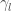 .
. that assign a training example
that assign a training example  to a leaf node
to a leaf node 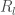 . Hence we can write each weak learner
. Hence we can write each weak learner 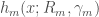 , giving:
, giving:
 , then step to another tree
, then step to another tree 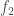 , and so on:
, and so on: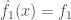
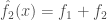
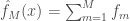
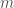 :
:![g_{im}=\frac{\partial L[f(x_i), y_i]}{\partial f(x_i)}](https://s0.wp.com/latex.php?latex=g_%7Bim%7D%3D%5Cfrac%7B%5Cpartial+L%5Bf%28x_i%29%2C+y_i%5D%7D%7B%5Cpartial+f%28x_i%29%7D&bg=ffffff&fg=404040&s=0&c=20201002)
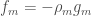 . This gives us insight into how Gradient Boosting solves the minimization – the algorithm is performing Gradient Descent in function space.
. This gives us insight into how Gradient Boosting solves the minimization – the algorithm is performing Gradient Descent in function space.
 denotes a regression tree with parameters
denotes a regression tree with parameters  .
. , we compute a value
, we compute a value 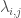 that acts as the gradient we need. Intuitively,
that acts as the gradient we need. Intuitively, 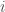 is ranked lower than document
is ranked lower than document  , then document
, then document  downwards in the ranked list, and
downwards in the ranked list, and 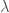 ‘s have been used successfully to optimize NDCG, MAP, and MRR.
‘s have been used successfully to optimize NDCG, MAP, and MRR.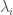 ‘s acting as the gradients
‘s acting as the gradients 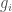 . This leads to update rules for the leaf values
. This leads to update rules for the leaf values 
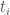 is dependent on the model state
is dependent on the model state  since it is fit to the gradient with respect to that model’s gradient.
since it is fit to the gradient with respect to that model’s gradient.
 possible node positions. We can collect the feature frequencies for each of these positions across the ensemble. If a position doesn’t appear in a tree, we mark it as ‘DNE’, and if a position is a leaf, we mark it as ‘Leaf’, such as position (3, 6):
possible node positions. We can collect the feature frequencies for each of these positions across the ensemble. If a position doesn’t appear in a tree, we mark it as ‘DNE’, and if a position is a leaf, we mark it as ‘Leaf’, such as position (3, 6):









 denote the set of queries,
denote the set of queries, 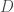 denote the set of documents, and
denote the set of documents, and 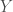 denote the set of relevance scores.
denote the set of relevance scores. we have a list of
we have a list of  . We want to produce a ranking for the documents
. We want to produce a ranking for the documents  , specifically a permutation
, specifically a permutation  of the document indices
of the document indices  . To do so, we want to learn a function
. To do so, we want to learn a function  that produces an optimal permutation
that produces an optimal permutation  pair, while others learn to tell whether the rank of
pair, while others learn to tell whether the rank of  .
. is assigned a relevance score
is assigned a relevance score  that says how relevant the document is to query
that says how relevant the document is to query 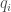 . These scores can be assigned by human annotators, or derived implicitly from sources such as click through data.
. These scores can be assigned by human annotators, or derived implicitly from sources such as click through data. ; one training example consists of a query, a candidate document, and a measure of how relevant that document is to the query. An example labeling is
; one training example consists of a query, a candidate document, and a measure of how relevant that document is to the query. An example labeling is  , where 1 means “not relevant” and 5 means “very relevant”.
, where 1 means “not relevant” and 5 means “very relevant”. = “Leo Tolstoy famous novel”, with candidate documents
= “Leo Tolstoy famous novel”, with candidate documents  , and relevance labels
, and relevance labels  .
. is actually a feature vector
is actually a feature vector  , so the final training set is defined as
, so the final training set is defined as  for
for  , where
, where 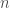 is the number of queries, and
is the number of queries, and  with:
with: = #docid 244338 = “Effects on bone of surgical menopause and estrogen therapy with or without progesterone replacement in cynomolgus monkeys.”
= #docid 244338 = “Effects on bone of surgical menopause and estrogen therapy with or without progesterone replacement in cynomolgus monkeys.” = 0 = not relevant
= 0 = not relevant with:
with: = #docid 143821 = “Cardiovascular benefits of estrogen replacement therapy.”
= #docid 143821 = “Cardiovascular benefits of estrogen replacement therapy.”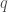 and a list of
and a list of  . We evaluate
. We evaluate 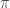 of the document indices
of the document indices  with annotated relevance scores
with annotated relevance scores  . The ranker produces a ranking
. The ranker produces a ranking  , so that
, so that  represents the predicted ranking of document
represents the predicted ranking of document 

 .
.
 .
.
 and
and  .
. is just a normalized version of
is just a normalized version of  . The normalization is done by finding the
. The normalization is done by finding the 


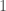 .
.

 is computed for a single query.
is computed for a single query.  is the mean
is the mean  .
. , then sort by the score.
, then sort by the score. . Model-wise, we find
. Model-wise, we find  when
when  .
. is a subtype of a function
is a subtype of a function  when A is a subtype of C and B is a subtype of D. However, this is incorrect!
when A is a subtype of C and B is a subtype of D. However, this is incorrect!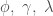 with the original parameters
with the original parameters  respectively. Recall that
respectively. Recall that  gives the topic assignments for each word in each document ,
gives the topic assignments for each word in each document , 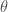 gives the topic composition of each document, and
gives the topic composition of each document, and 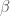 gives the word-topic probabilities for each word and each topic.
gives the word-topic probabilities for each word and each topic.
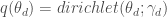
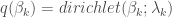
 using the current value of
using the current value of 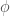
 repeat until change in
repeat until change in 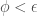 update
update 


 is the number of occurrences of
is the number of occurrences of  in document d.
in document d.
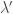 , which is the value of
, which is the value of 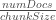 copies of the current chunk. Then
copies of the current chunk. Then 

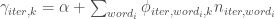


 is the number of occurrences of
is the number of occurrences of  is a weighting parameter.
is a weighting parameter.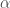 plus a weighted sum of word counts. The word counts are weighted by
plus a weighted sum of word counts. The word counts are weighted by  , the probability of assigning the word to the topic. Intuitively, if we count a lot of instances of “potato” in a document, and “potato” is likely to be assigned to topic 2, then it makes sense that the document has more of topic 2 in it than we previously thought.
, the probability of assigning the word to the topic. Intuitively, if we count a lot of instances of “potato” in a document, and “potato” is likely to be assigned to topic 2, then it makes sense that the document has more of topic 2 in it than we previously thought.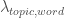 (the word-topic probabilities) use word counts weighted by the probability that the word will be assigned to the given topic. If “potato” shows up a lot in the dataset is likely to be assigned to topic 2, then it makes sense that
(the word-topic probabilities) use word counts weighted by the probability that the word will be assigned to the given topic. If “potato” shows up a lot in the dataset is likely to be assigned to topic 2, then it makes sense that 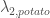 should increase.
should increase.





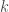 denote the number of topics that we think these tweets are generated from. Let’s say there are
denote the number of topics that we think these tweets are generated from. Let’s say there are  topics. Note that there are
topics. Note that there are  words in our corpus. LDA would tell us that:
words in our corpus. LDA would tell us that: distributions of size
distributions of size  It might look something like:
It might look something like:![\beta_{1} = [0.4, 0.2, 0.15, 0.05, 0.05, 0.05, 0.05]](https://s0.wp.com/latex.php?latex=%5Cbeta_%7B1%7D+%3D+%5B0.4%2C+0.2%2C+0.15%2C+0.05%2C+0.05%2C+0.05%2C+0.05%5D&bg=ffffff&fg=404040&s=0&c=20201002)
 lets us answer questions such as: given that our topic is Topic #1 (‘Food’), what is the probability of generating word #1 (‘Fruits’)?
lets us answer questions such as: given that our topic is Topic #1 (‘Food’), what is the probability of generating word #1 (‘Fruits’)?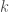 is the number of topics.
is the number of topics.
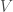 is the number of unique words in the vocabulary.
is the number of unique words in the vocabulary.
 is the topic distribution (of length
is the topic distribution (of length 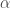 .
.
 is a topic 'assignment' for word
is a topic 'assignment' for word  , sampled from
, sampled from  .
.
 is a document with N words.
is a document with N words.
 means that the word
means that the word  is a
is a  matrix, where each row
matrix, where each row  is the multinomial distribution for the
is the multinomial distribution for the  .
.
 .
. .
. is the degree to which
is the degree to which  appears in the document.
appears in the document. :
: from
from  tells us that the word we are about to generate will be generated by topic
tells us that the word we are about to generate will be generated by topic  .
. .
.



 , and in the M-step, we perform the updates:
, and in the M-step, we perform the updates:

 as desired.
as desired. matrix that gives word probabilities given a topic, and
matrix that gives word probabilities given a topic, and  for
for  .
.



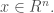 Each
Each 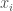 will represent the percentage of our budget invested in asset
will represent the percentage of our budget invested in asset  different stocks, identified by their ticker symbols:
different stocks, identified by their ticker symbols: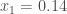 would mean that we invested 14% of our budget in Google. A naive allocation could be investing equal amounts (10%) into each stock, so that
would mean that we invested 14% of our budget in Google. A naive allocation could be investing equal amounts (10%) into each stock, so that ![x=[0.10,0.10,0.10,0.10,0.10,0.10,0.10,0.10,0.10,0.10]](https://s0.wp.com/latex.php?latex=x%3D%5B0.10%2C0.10%2C0.10%2C0.10%2C0.10%2C0.10%2C0.10%2C0.10%2C0.10%2C0.10%5D&bg=ffffff&fg=404040&s=0&c=20201002) . Our goal is to do better, and choose the best possible
. Our goal is to do better, and choose the best possible 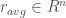 , where
, where  is the average return of asset i
is the average return of asset i . Using
. Using  :
: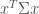 as a measure of risk for a given portfolio allocation
as a measure of risk for a given portfolio allocation  . Our objective is to minimize
. Our objective is to minimize  . Since we want each
. Since we want each 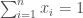 and
and 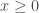 . These are simple linear constraints, maintaining convexity of the new problem:
. These are simple linear constraints, maintaining convexity of the new problem:


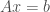
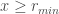 and
and 